Adapting Large Language Models to Mitigate Skin Tone Biases in Clinical Dermatology Tasks: A Mixed-Methods Study
作者: Kiran Nijjer, Ryan Bui, Derek Jiu, Adnan Ahmed, Peter Wang, Kevin Zhu, Lilly Zhu
分类: eess.IV, cs.CV, cs.CY
发布日期: 2025-09-28 (更新: 2025-10-07)
备注: Accepted to EADV (European Academy of Dermatology) and SID (Society for Investigative Dermatology)
💡 一句话要点
通过适配大型语言模型缓解临床皮肤病学任务中的肤色偏差
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 皮肤病诊断 肤色偏差 大型语言模型 公平性 临床评估
📋 核心要点
- 现有大型视觉-语言模型在皮肤病诊断中存在肤色偏差,对深色肤色诊断准确率较低,影响临床应用。
- 论文通过微调SkinGPT-4模型,并探索偏差缓解策略,定制更公平的皮肤病分类模型。
- 实验结果表明,定制模型在公平性指标上显著提升,证明了使用现有backbone训练公平模型的有效性。
📝 摘要(中文)
SkinGPT-4是一个大型视觉-语言模型,它利用带注释的皮肤病图像来增强服务欠发达社区的临床工作流程。然而,其训练数据集主要代表较浅的肤色,限制了其对较深肤色的诊断准确性。本文评估了SkinGPT-4在不同肤色人群中对常见皮肤病(包括湿疹、过敏性接触性皮炎和牛皮癣)的性能偏差,使用了开源的SCIN数据集。我们利用SkinGPT-4作为backbone,开发了用于自定义皮肤病分类任务的微调模型,并探索了偏差缓解策略。由认证皮肤科医生对来自300个SCIN病例的六种相关皮肤病图像进行了临床评估,评估了诊断准确性、信息性、医生效用和患者效用。计算了跨肤色的模型公平性指标,包括人口统计均等性和均等机会。SkinGPT-4在Fitzpatrick类型中实现了平均0.10的人口统计均等性,最浅和最深肤色之间在评估指标上存在0.10-0.15的显着差异。模型在伪影和解剖结构中出现幻觉的概率为17.8%。我们的定制模型在视觉上相似的疾病对中实现了平均0.75的F1分数、0.78的精确度和0.78的AUROC。公平性分析显示,平均人口统计均等性为0.75,最大差异为0.21。最佳模型在Fitzpatrick I-VI型中实现了0.83、0.83、0.76、0.89、0.90和0.90的均等性得分,表明了强大的公平性。SkinGPT-4等大型语言模型在较深肤色上的表现较弱。模型偏差存在于评估标准中,幻觉可能会影响诊断效果。这些发现证明了使用现有backbone训练准确、公平的模型用于自定义皮肤病分类的有效性。
🔬 方法详解
问题定义:论文旨在解决大型视觉-语言模型(如SkinGPT-4)在皮肤病诊断中存在的肤色偏差问题。现有模型在浅色肤色数据上训练,导致对深色肤色的诊断准确率显著下降,这限制了其在多样化人群中的临床应用。现有方法缺乏对肤色偏差的有效缓解策略,导致模型在不同肤色人群中的表现不一致。
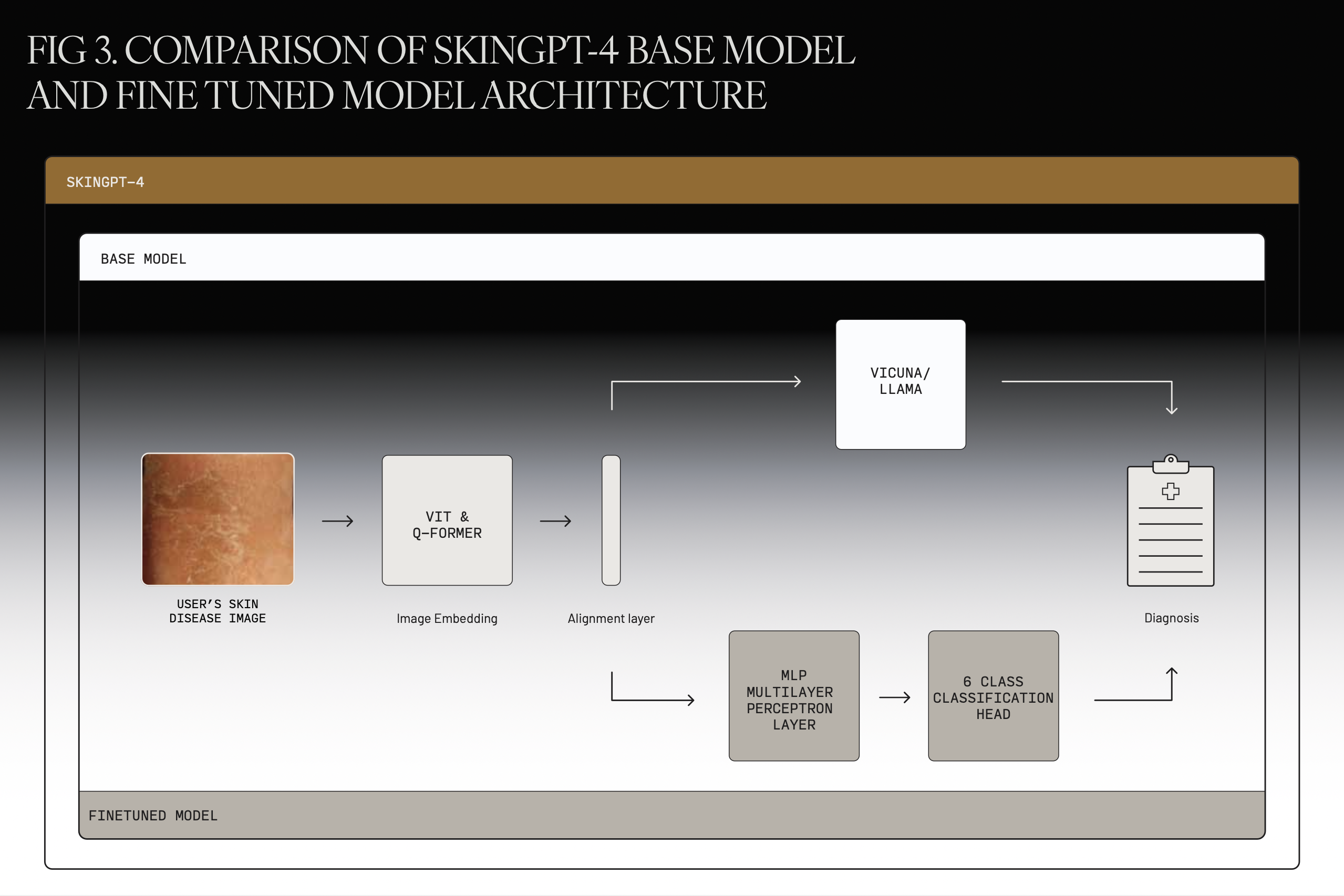
核心思路:论文的核心思路是利用SkinGPT-4的backbone,通过微调和偏差缓解策略,构建更公平的皮肤病分类模型。通过在包含不同肤色的SCIN数据集上进行训练,并结合临床医生的评估,来优化模型在不同肤色人群中的表现。这种方法旨在减少模型对肤色的依赖,提高其在所有人群中的诊断准确性和公平性。
技术框架:整体框架包括以下几个主要阶段:1) 使用SCIN数据集评估SkinGPT-4在不同肤色上的性能偏差;2) 基于SkinGPT-4 backbone,开发用于自定义皮肤病分类任务的微调模型;3) 探索和实施偏差缓解策略,以减少肤色偏差;4) 由皮肤科医生对模型进行临床评估,评估诊断准确性、信息性、医生效用和患者效用;5) 计算模型公平性指标,如人口统计均等性和均等机会,以量化肤色偏差。
关键创新:论文的关键创新在于针对皮肤病诊断任务,探索了大型视觉-语言模型中肤色偏差的缓解策略。与现有方法相比,该研究不仅关注模型的准确性,还关注模型在不同肤色人群中的公平性。通过结合临床评估和公平性指标,更全面地评估了模型的性能。
关键设计:论文的关键设计包括:1) 使用SCIN数据集,该数据集包含不同肤色的皮肤病图像;2) 利用SkinGPT-4作为backbone,进行微调,以适应自定义皮肤病分类任务;3) 采用人口统计均等性和均等机会等公平性指标,来量化和评估肤色偏差;4) 结合皮肤科医生的临床评估,来验证模型的实际应用价值。
🖼️ 关键图片


📊 实验亮点
定制模型在视觉相似疾病对上实现了平均0.75的F1分数、0.78的精确度和0.78的AUROC。公平性分析显示,平均人口统计均等性为0.75,最大差异为0.21。最佳模型在Fitzpatrick I-VI型中实现了0.83、0.83、0.76、0.89、0.90和0.90的均等性得分,表明了强大的公平性。
🎯 应用场景
该研究成果可应用于远程医疗、皮肤病筛查和诊断辅助等领域,尤其是在医疗资源匮乏的地区。通过部署更公平的AI模型,可以提高对不同肤色人群的诊断准确性,减少误诊和漏诊,从而改善患者的健康状况。未来,该研究可以扩展到其他医学图像分析任务,提高AI在医疗领域的公平性和可靠性。
📄 摘要(原文)
SkinGPT-4, a large vision-language model, leverages annotated skin disease images to augment clinical workflows in underserved communities. However, its training dataset predominantly represents lighter skin tones, limiting diagnostic accuracy for darker tones. Here, we evaluated performance biases in SkinGPT-4 across skin tones on common skin diseases, including eczema, allergic-contact dermatitis, and psoriasis using the open-sourced SCIN dataset. We leveraged the SkinGPT-4 backbone to develop finetuned models for custom skin disease classification tasks and explored bias mitigation strategies. Clinical evaluation by board-certified dermatologists on six relevant skin diseases from 300 SCIN cases assessed images for diagnostic accuracy, informativity, physician utility, and patient utility. Model fairness metrics, including demographic parity and equalized odds, were calculated across skin tones. SkinGPT-4 achieved an average demographic parity of 0.10 across Fitzpatrick types, with notable differences of 0.10-0.15 between lightest and darkest tones across evaluation metrics. Model hallucinations in artifacts and anatomy occurred at a rate of 17.8. Our customized models achieved average F1, precision, and AUROC of 0.75, 0.78, and 0.78 across visually similar disease pairs. Fairness analysis showed an average demographic parity of 0.75, with a maximum disparity of 0.21 across skin tones. The best model achieved parity scores of 0.83, 0.83, 0.76, 0.89, 0.90, and 0.90 for Fitzpatrick I-VI, indicating robust fairness. Large language models such as SkinGPT-4 showed weaker performance on darker tones. Model biases exist across evaluation criteria, and hallucinations may affect diagnostic efficacy. These findings demonstrate the efficacy of training accurate, fair models using existing backbones for custom skin disease classification.