HiDe: Rethinking The Zoom-IN method in High Resolution MLLMs via Hierarchical Decoupling
作者: Xianjie Liu, Yiman Hu, Yixiong Zou, Liang Wu, Jian Xu, Bo Zheng
分类: cs.CV, cs.AI
发布日期: 2025-09-28
🔗 代码/项目: GITHUB
💡 一句话要点
HiDe:通过分层解耦重新思考高分辨率MLLM中的Zoom-IN方法
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态大模型 高分辨率图像 视觉理解 注意力机制 解耦框架
📋 核心要点
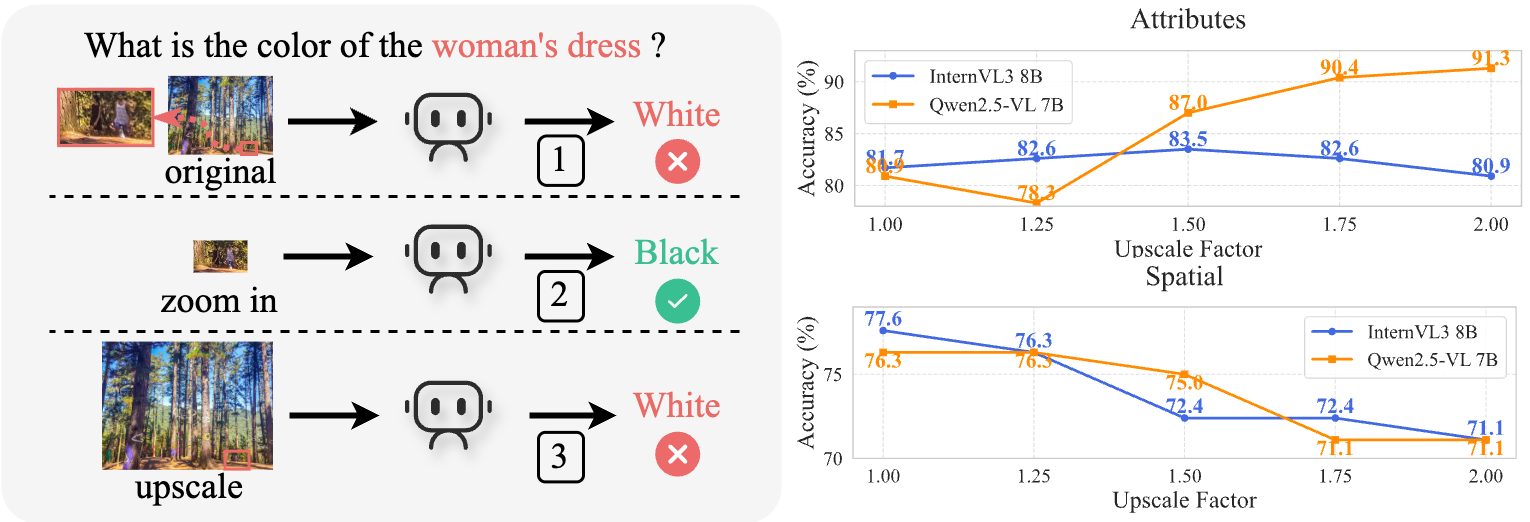
- 现有高分辨率多模态大模型在处理复杂背景时,性能受限,并非单纯的小物体识别问题。
- HiDe框架通过token级注意力解耦和布局保持解耦,有效分离目标区域与背景干扰。
- HiDe在多个高分辨率基准测试上取得SOTA,显著提升模型性能,并降低了内存占用。
📝 摘要(中文)
多模态大型语言模型(MLLMs)在视觉理解任务中取得了显著进展。然而,它们在高分辨率图像上的性能仍然欠佳。现有方法通常将此限制归因于感知约束,并认为MLLMs难以识别小物体,从而采用“放大”策略以获得更好的细节。我们的分析揭示了不同的原因:主要问题不是物体大小,而是由复杂的背景干扰引起的。我们通过一系列解耦实验系统地分析了这种“放大”操作,并提出了分层解耦框架(HiDe),这是一个免训练框架,它使用Token-wise Attention Decoupling(TAD)来解耦问题tokens并识别关键信息tokens,然后利用它们的注意力权重来实现与目标视觉区域的精确对齐。随后,它采用Layout-Preserving Decoupling(LPD)将这些区域与背景解耦,并重建一个紧凑的表示,该表示保留了必要的空间布局,同时消除了背景干扰。HiDe在VBench、HRBench4K和HRBench8K上创造了新的SOTA,将Qwen2.5-VL 7B和InternVL3 8B提升到SOTA(在VBench上分别为92.1%和91.6%),甚至超过了RL方法。经过优化,HiDe使用的内存比之前的免训练方法少75%。代码已在https://github.com/Tennine2077/HiDe提供。
🔬 方法详解
问题定义:现有高分辨率多模态大模型(MLLMs)在处理高分辨率图像时,性能往往不尽如人意。虽然一些研究认为这是由于模型难以识别小物体,需要通过“放大”策略来关注细节,但该论文指出,问题的关键在于复杂背景的干扰,而非物体本身的大小。现有方法缺乏有效分离目标区域和背景干扰的机制,导致模型性能下降。
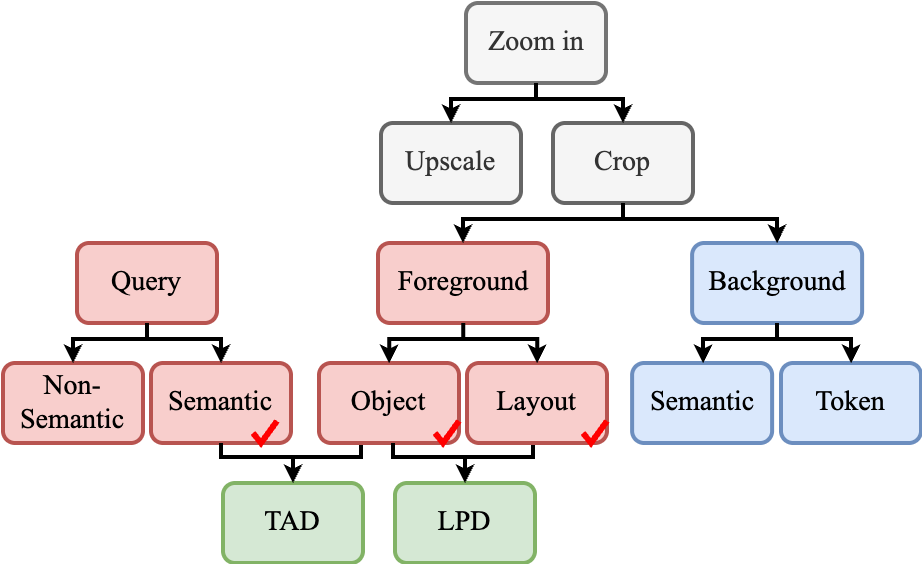
核心思路:论文的核心思路是通过分层解耦的方式,将问题tokens与视觉tokens解耦,并进一步将目标区域与背景解耦。首先,利用Token-wise Attention Decoupling (TAD) 识别与问题相关的关键视觉tokens。然后,利用Layout-Preserving Decoupling (LPD) 将这些关键区域从背景中分离出来,从而得到更干净、更紧凑的视觉表示。这样设计的目的是为了减少背景干扰,提高模型对目标区域的关注度。
技术框架:HiDe框架主要包含两个阶段:Token-wise Attention Decoupling (TAD) 和 Layout-Preserving Decoupling (LPD)。TAD阶段首先解耦问题tokens和视觉tokens,通过分析注意力权重识别与问题最相关的视觉区域。LPD阶段则利用这些注意力权重,将识别出的视觉区域从原始图像中分离出来,并重建一个保留空间布局的紧凑表示。最终,模型基于这个新的视觉表示进行推理。
关键创新:HiDe的关键创新在于其分层解耦的思想,它不仅关注了问题与视觉区域的对齐,还考虑了背景干扰的影响,并提出了相应的解耦策略。与现有方法相比,HiDe无需训练,可以直接应用于现有的MLLMs,具有更高的灵活性和实用性。此外,HiDe在解耦过程中保留了关键的空间布局信息,避免了信息丢失。
关键设计:TAD阶段的关键在于如何有效地解耦问题tokens和视觉tokens,并准确识别关键视觉区域。LPD阶段的关键在于如何在分离目标区域的同时,保留其空间布局信息。论文中可能涉及注意力权重阈值的设置、区域重建算法的选择等技术细节。具体的损失函数和网络结构细节需要在论文原文中查找。
🖼️ 关键图片

📊 实验亮点
HiDe在VBench、HRBench4K和HRBench8K等高分辨率基准测试上取得了显著的性能提升,创造了新的SOTA。例如,在VBench上,HiDe将Qwen2.5-VL 7B和InternVL3 8B的性能分别提升至92.1%和91.6%,甚至超过了使用强化学习(RL)的方法。此外,HiDe在优化后,使用的内存比之前的免训练方法减少了75%。
🎯 应用场景
HiDe框架具有广泛的应用前景,可用于提升各种视觉理解任务的性能,尤其是在需要处理高分辨率图像的场景中,例如自动驾驶、医学图像分析、遥感图像处理等。通过减少背景干扰,HiDe可以帮助模型更准确地识别目标物体,提高决策的可靠性。此外,HiDe的免训练特性使其易于部署和应用。
📄 摘要(原文)
Multimodal Large Language Models (MLLMs) have made significant strides in visual understanding tasks. However, their performance on high-resolution images remains suboptimal. While existing approaches often attribute this limitation to perceptual constraints and argue that MLLMs struggle to recognize small objects, leading them to use "zoom in" strategies for better detail, our analysis reveals a different cause: the main issue is not object size, but rather caused by complex background interference. We systematically analyze this "zoom in" operation through a series of decoupling experiments and propose the Hierarchical Decoupling Framework (HiDe), a training-free framework that uses Token-wise Attention Decoupling (TAD) to decouple the question tokens and identify the key information tokens, then leverages their attention weights to achieve precise alignment with the target visual regions. Subsequently, it employs Layout-Preserving Decoupling (LPD) to decouple these regions from the background and reconstructs a compact representation that preserves essential spatial layouts while eliminating background interference. HiDe sets a new SOTA on VBench, HRBench4K, and HRBench8K, boosting Qwen2.5-VL 7B and InternVL3 8B to SOTA (92.1% and 91.6% on VBench), even surpassing RL methods. After optimization, HiDe uses 75% less memory than the previous training-free approach. Code is provided in https://github.com/Tennine2077/HiDe.