HunyuanImage 3.0 Technical Report
作者: Siyu Cao, Hangting Chen, Peng Chen, Yiji Cheng, Yutao Cui, Xinchi Deng, Ying Dong, Kipper Gong, Tianpeng Gu, Xiusen Gu, Tiankai Hang, Duojun Huang, Jie Jiang, Zhengkai Jiang, Weijie Kong, Changlin Li, Donghao Li, Junzhe Li, Xin Li, Yang Li, Zhenxi Li, Zhimin Li, Jiaxin Lin, Linus, Lucaz Liu, Shu Liu, Songtao Liu, Yu Liu, Yuhong Liu, Yanxin Long, Fanbin Lu, Qinglin Lu, Yuyang Peng, Yuanbo Peng, Xiangwei Shen, Yixuan Shi, Jiale Tao, Yangyu Tao, Qi Tian, Pengfei Wan, Chunyu Wang, Kai Wang, Lei Wang, Linqing Wang, Lucas Wang, Qixun Wang, Weiyan Wang, Hao Wen, Bing Wu, Jianbing Wu, Yue Wu, Senhao Xie, Fang Yang, Miles Yang, Xiaofeng Yang, Xuan Yang, Zhantao Yang, Jingmiao Yu, Zheng Yuan, Chao Zhang, Jian-Wei Zhang, Peizhen Zhang, Shi-Xue Zhang, Tao Zhang, Weigang Zhang, Yepeng Zhang, Yingfang Zhang, Zihao Zhang, Zijian Zhang, Penghao Zhao, Zhiyuan Zhao, Xuefei Zhe, Jianchen Zhu, Zhao Zhong
分类: cs.CV
发布日期: 2025-09-28 (更新: 2026-02-02)
🔗 代码/项目: GITHUB
💡 一句话要点
腾讯混元发布HunyuanImage 3.0,开源最大规模的图像生成MoE模型
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 图像生成 多模态模型 自回归模型 混合专家模型 MoE 开源 文本图像对齐
📋 核心要点
- 现有图像生成模型在多模态理解和生成方面存在局限性,难以兼顾模型规模和生成质量。
- HunyuanImage 3.0采用自回归框架统一多模态理解和生成,并利用MoE架构扩展模型规模。
- 实验结果表明,HunyuanImage 3.0在文本-图像对齐和视觉质量方面与现有最佳模型具有竞争力。
📝 摘要(中文)
本文介绍了HunyuanImage 3.0,这是一个原生的多模态模型,它在一个自回归框架内统一了多模态理解和生成,其图像生成模块已公开可用。HunyuanImage 3.0的实现依赖于几个关键组件,包括细致的数据管理、先进的架构设计、原生的思维链模式、渐进式模型预训练、积极的模型后训练以及支持大规模训练和推理的高效基础设施。通过这些进步,我们成功训练了一个包含超过800亿参数的混合专家(MoE)模型,在推理期间每个token激活130亿个参数,使其成为迄今为止最大、最强大的开源图像生成模型。我们进行了广泛的实验,自动和人工评估文本-图像对齐和视觉质量的结果表明,HunyuanImage 3.0可以与以前最先进的模型相媲美。通过发布HunyuanImage 3.0的代码和权重,我们旨在使社区能够使用最先进的基础模型探索新想法,从而促进动态和充满活力的多模态生态系统。所有开源资产都可以在https://github.com/Tencent-Hunyuan/HunyuanImage-3.0上公开获得。
🔬 方法详解
问题定义:现有图像生成模型通常难以同时兼顾多模态理解和生成能力,并且在模型规模扩展时面临训练和推理效率的挑战。现有方法在数据质量、模型架构和训练策略等方面存在改进空间。
核心思路:HunyuanImage 3.0的核心思路是采用一个统一的自回归框架,将多模态理解和生成任务整合在一起。通过引入混合专家(MoE)架构,可以在不显著增加推理成本的情况下扩展模型规模,从而提升生成质量。此外,论文还强调了数据质量和训练策略的重要性。
技术框架:HunyuanImage 3.0的整体架构是一个自回归模型,它接收文本和图像作为输入,并生成图像。该模型包含一个多模态编码器,用于将文本和图像转换为统一的表示。然后,一个自回归解码器使用该表示生成图像。MoE层被集成到解码器中,以增加模型容量。训练过程包括预训练和后训练两个阶段。
关键创新:HunyuanImage 3.0的关键创新在于其统一的多模态自回归框架和MoE架构的应用。该框架能够同时处理多模态理解和生成任务,而MoE架构则允许模型在不显著增加推理成本的情况下扩展到更大的规模。此外,论文还强调了数据管理和训练策略的重要性,这些因素对模型的性能至关重要。
关键设计:HunyuanImage 3.0的关键设计包括:1) 细致的数据管理流程,确保训练数据的质量和多样性;2) 先进的架构设计,包括多模态编码器、自回归解码器和MoE层;3) 原生的思维链模式,用于提高模型的推理能力;4) 渐进式模型预训练和积极的模型后训练策略,用于优化模型性能;5) 高效的基础设施,支持大规模训练和推理。MoE模型包含超过800亿参数,推理时每个token激活130亿参数。
🖼️ 关键图片

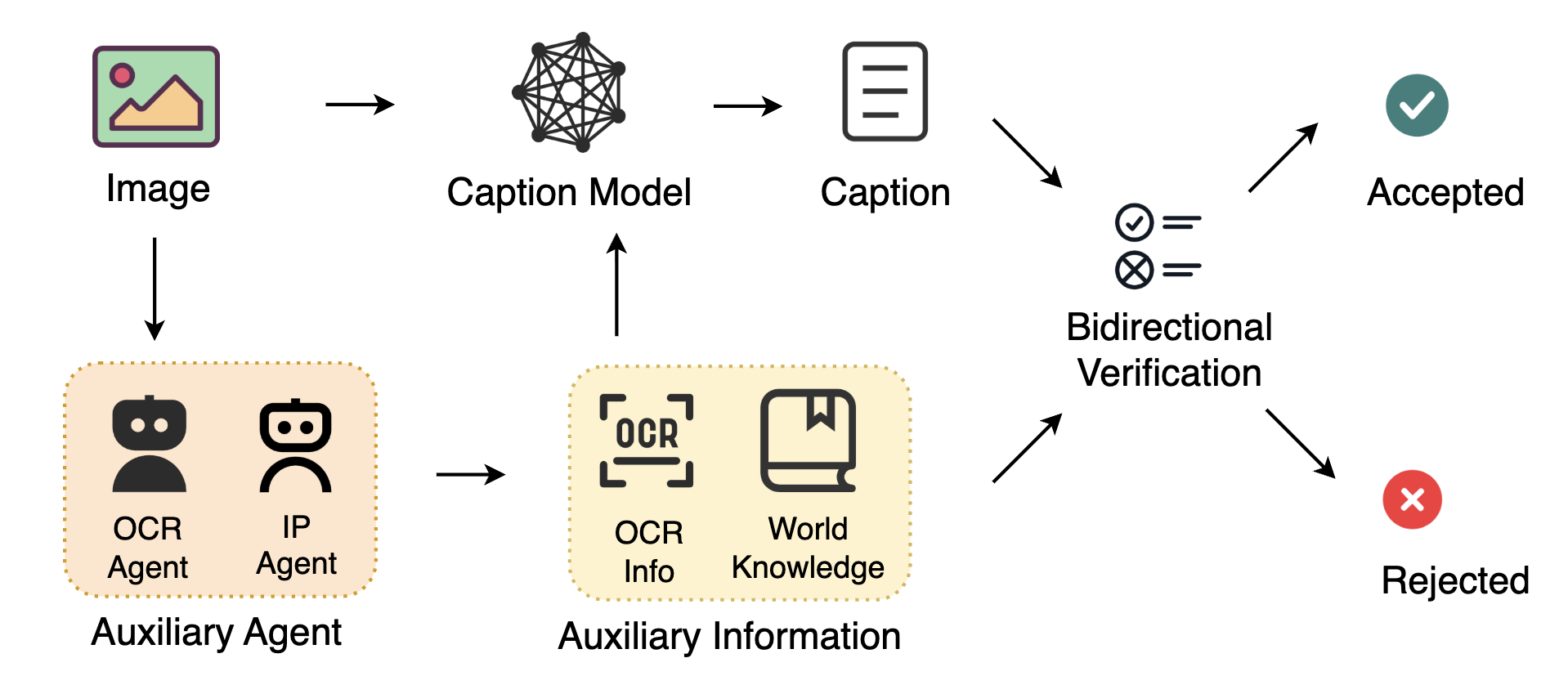
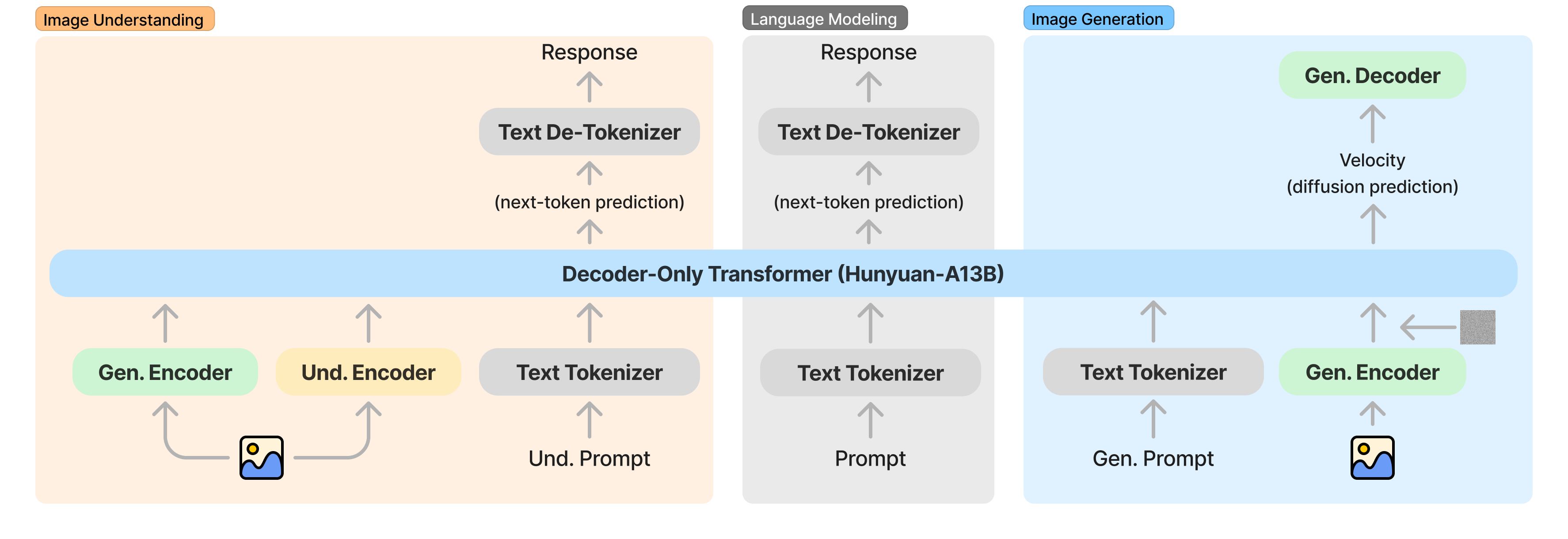
📊 实验亮点
HunyuanImage 3.0是一个包含超过800亿参数的混合专家(MoE)模型,在推理期间每个token激活130亿个参数,是目前最大的开源图像生成模型。自动和人工评估结果表明,该模型在文本-图像对齐和视觉质量方面与现有最佳模型具有竞争力,证明了其强大的生成能力。
🎯 应用场景
HunyuanImage 3.0具有广泛的应用前景,包括图像编辑、图像生成、视觉内容创作、广告设计、游戏开发等领域。该模型可以用于生成高质量的图像,并根据文本描述对图像进行编辑和修改。开源发布有助于促进多模态研究和应用的发展,为相关领域带来创新。
📄 摘要(原文)
We present HunyuanImage 3.0, a native multimodal model that unifies multimodal understanding and generation within an autoregressive framework, with its image generation module publicly available. The achievement of HunyuanImage 3.0 relies on several key components, including meticulous data curation, advanced architecture design, a native Chain-of-Thoughts schema, progressive model pre-training, aggressive model post-training, and an efficient infrastructure that enables large-scale training and inference. With these advancements, we successfully trained a Mixture-of-Experts (MoE) model comprising over 80 billion parameters in total, with 13 billion parameters activated per token during inference, making it the largest and most powerful open-source image generative model to date. We conducted extensive experiments and the results of automatic and human evaluation of text-image alignment and visual quality demonstrate that HunyuanImage 3.0 rivals previous state-of-the-art models. By releasing the code and weights of HunyuanImage 3.0, we aim to enable the community to explore new ideas with a state-of-the-art foundation model, fostering a dynamic and vibrant multimodal ecosystem. All open source assets are publicly available at https://github.com/Tencent-Hunyuan/HunyuanImage-3.0