Revisit the Imbalance Optimization in Multi-task Learning: An Experimental Analysis
作者: Yihang Guo, Tianyuan Yu, Liang Bai, Yanming Guo, Yirun Ruan, William Li, Weishi Zheng
分类: cs.CV
发布日期: 2025-09-28
💡 一句话要点
通过梯度范数调整损失权重,解决多任务学习中的优化不平衡问题
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多任务学习 优化不平衡 梯度范数 损失缩放 视觉基础模型
📋 核心要点
- 多任务学习面临优化不平衡问题,导致性能低于单任务模型,现有方法依赖耗时网格搜索。
- 论文核心思想是根据任务特定梯度的范数来动态调整任务损失权重,从而平衡优化过程。
- 实验表明,基于梯度范数的损失缩放策略,性能可与计算代价高昂的网格搜索相媲美。
📝 摘要(中文)
多任务学习(MTL)旨在通过训练单个网络来联合执行多个任务,从而构建通用的视觉系统。然而,任务间的干扰常常导致“优化不平衡”,使得性能低于单任务模型。为了促进MTL的研究,本文对导致这一问题的因素进行了系统的实验分析。研究表明,现有优化方法在不同数据集上的表现不一致,并且先进的架构仍然依赖于代价高昂的网格搜索来确定损失权重。此外,尽管强大的视觉基础模型(VFMs)提供了良好的初始化,但它们并不能从根本上解决优化不平衡问题,并且增加数据量带来的收益有限。一个关键的发现是:优化不平衡与任务特定梯度的范数之间存在很强的相关性。我们证明了这一发现可以直接应用,即通过根据梯度范数缩放任务损失,可以实现与广泛且计算成本高的网格搜索相当的性能。我们的综合分析表明,理解和控制梯度动态是实现稳定MTL的更直接途径,而不是开发越来越复杂的方法。
🔬 方法详解
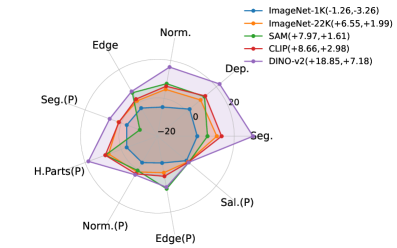
问题定义:多任务学习中,由于不同任务的学习难度、数据规模等差异,容易出现优化不平衡现象,即某些任务学习效果好,而另一些任务学习效果差。现有方法,如手动调整损失权重,通常需要大量的实验和计算资源进行网格搜索,效率低下。即使使用强大的视觉基础模型,也无法完全消除这种优化不平衡。
核心思路:论文的核心思路是观察到任务特定梯度的范数与优化不平衡之间存在强相关性。梯度范数可以反映任务的学习状态,范数越大,表明该任务的学习速度越快。因此,可以通过调整损失函数,使得梯度范数较小的任务得到更多的关注,从而平衡不同任务的学习进度。
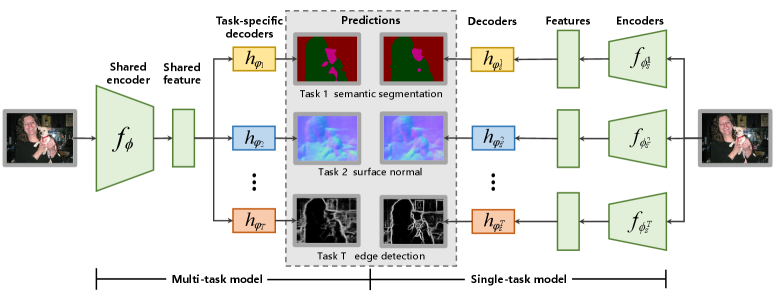
技术框架:论文主要通过实验分析来验证核心思路。首先,通过大量的实验,观察不同数据集、不同模型架构下,现有优化方法和视觉基础模型的表现。然后,分析任务特定梯度的范数与优化不平衡之间的关系。最后,提出基于梯度范数的损失缩放策略,并验证其有效性。整体框架是实验分析驱动的,旨在揭示多任务学习优化不平衡的本质原因,并提出简单的解决方案。
关键创新:最重要的技术创新点在于发现了任务特定梯度的范数与优化不平衡之间的强相关性。这一发现为解决多任务学习中的优化不平衡问题提供了一个新的视角,即可以通过控制梯度动态来实现更稳定的多任务学习。与现有方法相比,该方法更加直接,不需要复杂的模型设计或优化算法。
关键设计:关键设计在于基于梯度范数的损失缩放策略。具体来说,对于每个任务,计算其梯度范数,并根据梯度范数的大小来调整该任务的损失权重。梯度范数小的任务,损失权重增大;梯度范数大的任务,损失权重减小。具体的缩放函数可以根据实际情况进行调整,例如可以使用指数函数或线性函数。
🖼️ 关键图片

📊 实验亮点
实验结果表明,基于梯度范数的损失缩放策略可以有效地解决多任务学习中的优化不平衡问题,并且性能可以与计算代价高昂的网格搜索相媲美。该方法在多个数据集上都取得了显著的性能提升,证明了其有效性和通用性。此外,该研究还揭示了视觉基础模型并不能完全解决优化不平衡问题,为未来的研究方向提供了新的思路。
🎯 应用场景
该研究成果可应用于各种多任务学习场景,例如自动驾驶、医疗影像分析、机器人视觉等。通过平衡不同任务的学习进度,可以提高多任务学习模型的整体性能和泛化能力,降低模型部署和维护的成本。该研究为多任务学习的实际应用提供了有价值的指导。
📄 摘要(原文)
Multi-task learning (MTL) aims to build general-purpose vision systems by training a single network to perform multiple tasks jointly. While promising, its potential is often hindered by "unbalanced optimization", where task interference leads to subpar performance compared to single-task models. To facilitate research in MTL, this paper presents a systematic experimental analysis to dissect the factors contributing to this persistent problem. Our investigation confirms that the performance of existing optimization methods varies inconsistently across datasets, and advanced architectures still rely on costly grid-searched loss weights. Furthermore, we show that while powerful Vision Foundation Models (VFMs) provide strong initialization, they do not inherently resolve the optimization imbalance, and merely increasing data quantity offers limited benefits. A crucial finding emerges from our analysis: a strong correlation exists between the optimization imbalance and the norm of task-specific gradients. We demonstrate that this insight is directly applicable, showing that a straightforward strategy of scaling task losses according to their gradient norms can achieve performance comparable to that of an extensive and computationally expensive grid search. Our comprehensive analysis suggests that understanding and controlling gradient dynamics is a more direct path to stable MTL than developing increasingly complex methods.