GenView++: Unifying Adaptive Generative Augmentation and Quality-Driven Supervision for Contrastive Representation Learning
作者: Xiaojie Li, Bei Wang, Wei Liu, Jianlong Wu, Yue Yu, Liqiang Nie, Min Zhang
分类: cs.CV
发布日期: 2025-09-28 (更新: 2026-01-20)
备注: The code is available at \url{https://github.com/xiaojieli0903/GenViewPlusPlus}
💡 一句话要点
GenView++:融合自适应生成增强与质量驱动监督的对比表示学习框架
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 对比学习 数据增强 自适应生成 视觉表示学习 视觉语言学习
📋 核心要点
- 现有对比学习方法在正样本对构建上存在多样性不足和语义损坏的风险,影响表示学习效果。
- GenView++提出多源自适应视图生成机制,结合图像、文本等信息,动态生成多样且语义一致的视图。
- GenView++引入质量驱动的对比学习机制,评估样本对质量并动态调整权重,提升高质量样本对的贡献。
📝 摘要(中文)
对比学习的成功依赖于高质量正样本对的构建和利用。然而,现有方法在两个方面存在局限性:在构建方面,手工和生成式增强方法通常面临多样性有限和语义损坏的风险;在学习方面,缺乏质量评估机制导致次优监督,所有样本对都被同等对待。为了解决这些挑战,我们提出了GenView++,一个统一的框架,通过引入两个协同创新来解决这两个方面的问题。为了改进样本对构建,GenView++引入了一种多源自适应视图生成机制,通过动态调整图像条件、文本条件和图像-文本条件策略中的生成参数,来合成多样但语义一致的视图。其次,一种质量驱动的对比学习机制评估每个样本对的语义对齐和多样性,以动态地重新加权它们的训练贡献,优先考虑高质量的样本对,同时抑制冗余或未对齐的样本对。大量的实验表明了GenView++在视觉和视觉-语言任务中的有效性。对于视觉表示学习,它在ImageNet线性分类上将MoCov2提高了+2.5%。对于视觉-语言学习,它在十个数据集上将CLIP的平均零样本分类精度提高了+12.31%,将SLIP提高了+5.31%,并进一步将Flickr30k文本检索R@5提高了+3.2%。
🔬 方法详解
问题定义:对比学习依赖于高质量的正样本对,但现有方法,如手工设计的增强或生成式增强,常常面临多样性不足和语义损坏的风险。此外,现有方法通常对所有样本对一视同仁,忽略了样本对质量的差异,导致次优的监督信号。
核心思路:GenView++的核心思路是通过多源自适应视图生成来构建高质量的正样本对,并利用质量驱动的对比学习机制来优化训练过程。通过结合图像、文本等多种信息源,动态生成多样且语义一致的视图,从而提高正样本对的质量。同时,根据样本对的语义对齐和多样性,动态调整其训练贡献,从而优先考虑高质量的样本对。
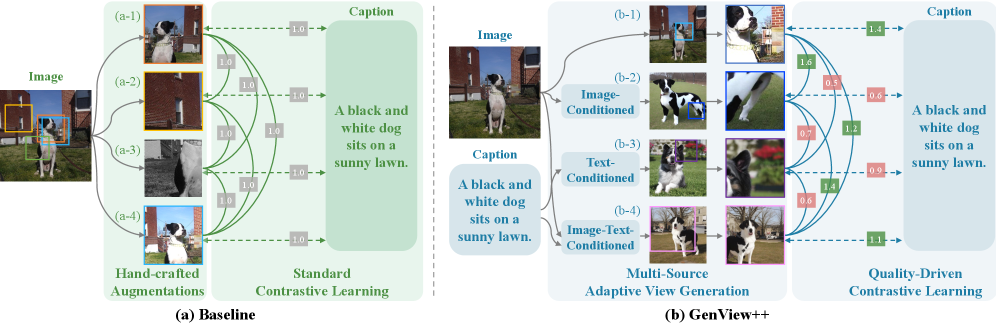
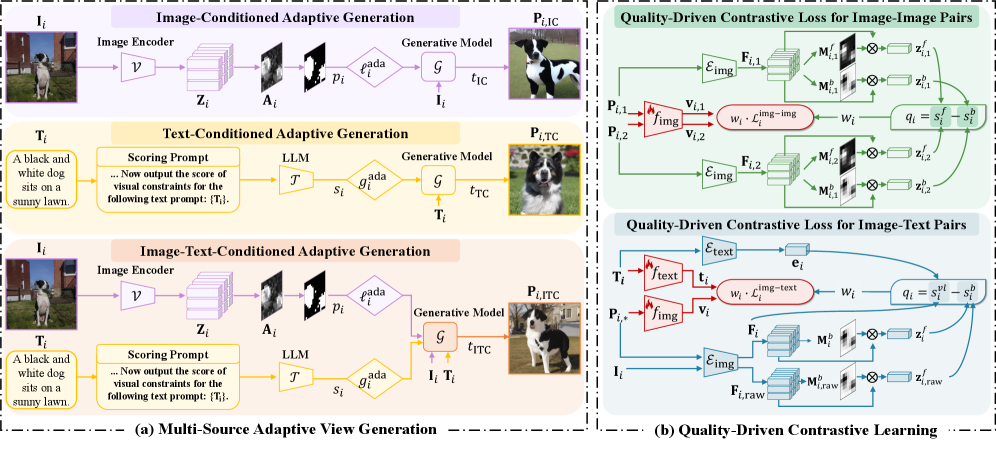
技术框架:GenView++包含两个主要模块:多源自适应视图生成模块和质量驱动的对比学习模块。多源自适应视图生成模块利用图像、文本以及图像-文本的组合信息,通过动态调整生成参数来生成不同的视图。质量驱动的对比学习模块评估每个样本对的语义对齐和多样性,并根据评估结果动态调整其在对比损失中的权重。整体流程是先通过多源自适应视图生成模块生成多个视图,然后利用质量驱动的对比学习模块对这些视图进行对比学习。
关键创新:GenView++的关键创新在于将多源自适应视图生成和质量驱动的对比学习相结合。多源自适应视图生成能够生成多样且语义一致的视图,从而提高正样本对的质量。质量驱动的对比学习能够根据样本对的质量动态调整其训练贡献,从而优化训练过程。这种结合使得GenView++能够有效地学习到高质量的表示。
关键设计:在多源自适应视图生成模块中,使用了图像条件、文本条件和图像-文本条件三种策略来生成视图。每种策略都包含多个可调节的生成参数,这些参数可以根据输入图像和文本进行动态调整。在质量驱动的对比学习模块中,使用了语义对齐和多样性两个指标来评估样本对的质量。语义对齐度量了两个视图之间的语义一致性,多样性度量了两个视图之间的差异程度。根据这两个指标,可以计算出一个权重,用于调整样本对在对比损失中的贡献。
🖼️ 关键图片

📊 实验亮点
GenView++在多个任务上取得了显著的性能提升。在ImageNet线性分类任务中,相比于MoCov2,GenView++提升了+2.5%。在视觉-语言学习任务中,GenView++在十个数据集上将CLIP的平均零样本分类精度提高了+12.31%,将SLIP提高了+5.31%。此外,GenView++还将Flickr30k文本检索R@5提高了+3.2%。这些结果表明GenView++在视觉和视觉-语言表示学习方面具有显著的优势。
🎯 应用场景
GenView++具有广泛的应用前景,可以应用于图像分类、图像检索、视觉语言理解等领域。其高质量的表示学习能力可以提升各种视觉和视觉语言任务的性能。例如,可以用于改进图像搜索引擎的检索精度,提高图像分类器的准确率,以及增强视觉语言模型的理解能力。未来,该方法可以进一步扩展到其他模态的数据,如视频、音频等,从而实现更强大的多模态表示学习。
📄 摘要(原文)
The success of contrastive learning depends on the construction and utilization of high-quality positive pairs. However, current methods face critical limitations on two fronts: on the construction side, both handcrafted and generative augmentations often suffer from limited diversity and risk semantic corruption; on the learning side, the absence of a quality assessment mechanism leads to suboptimal supervision where all pairs are treated equally. To tackle these challenges, we propose GenView++, a unified framework that addresses both fronts by introducing two synergistic innovations. To improve pair construction, GenView++ introduces a multi-source adaptive view generation mechanism to synthesize diverse yet semantically coherent views by dynamically modulating generative parameters across image-conditioned, text-conditioned, and image-text-conditioned strategies. Second, a quality-driven contrastive learning mechanism assesses each pair's semantic alignment and diversity to dynamically reweight their training contribution, prioritizing high-quality pairs while suppressing redundant or misaligned pairs. Extensive experiments demonstrate the effectiveness of GenView++ across both vision and vision-language tasks. For vision representation learning, it improves MoCov2 by +2.5% on ImageNet linear classification. For vision-language learning, it raises the average zero-shot classification accuracy by +12.31% over CLIP and +5.31% over SLIP across ten datasets, and further improves Flickr30k text retrieval R@5 by +3.2%.