Poivre: Self-Refining Visual Pointing with Reinforcement Learning
作者: Wenjie Yang, Zengfeng Huang
分类: cs.CV, cs.AI
发布日期: 2025-09-28
💡 一句话要点
提出Poivre:基于强化学习的自精炼视觉指向方法
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 视觉指向 视觉语言模型 强化学习 自精炼 迭代优化
📋 核心要点
- 现有视觉语言模型在视觉指向任务中表现不佳,主要原因是它们通常需要一步到位,缺乏迭代修正能力。
- Poivre方法通过引入Point, Visualize, then Refine的自精炼流程,使模型能够迭代地修正指向位置。
- Poivre-7B模型在Point-Bench上取得了新的state-of-the-art,超越了多个专有和开源模型,性能提升显著。
📝 摘要(中文)
视觉指向旨在通过预测图像上的坐标来定位目标,是视觉语言模型(VLMs)中的一个重要问题。尽管应用广泛,但最新基准测试表明,当前VLMs在该任务上的表现远落后于人类。一个关键限制是VLMs通常需要一步完成指向任务,类似于要求人类在看不到自己手指的情况下指向物体。为了解决这个问题,我们提出了一种简单而有效的自精炼程序:Point, Visualize, then Refine (Poivre)。该程序使VLM能够首先标记其估计点,然后在必要时迭代地细化坐标。受到自然语言领域推理模型进展的启发,我们采用强化学习(RL)来激励这种自精炼能力。对于RL训练,我们设计了一个简洁的过程奖励,该奖励不仅在经验上有效,而且具有吸引人的特性。我们训练的模型Poivre-7B在Point-Bench上创造了新的state-of-the-art,优于Gemini-2.5-Pro等专有模型和Molmo-72B等大型开源模型超过3%。为了支持未来的研究,我们发布了我们的训练和推理代码、数据集以及Poivre-7B检查点。
🔬 方法详解
问题定义:论文旨在解决视觉语言模型(VLMs)在视觉指向任务中表现不佳的问题。现有方法通常采用单步预测,缺乏迭代修正机制,导致精度不足,尤其是在复杂场景下。这种单步预测的方式与人类的认知过程不符,人类通常会通过观察和调整来逐步精确地指向目标。
核心思路:论文的核心思路是引入一个自精炼的流程,使VLM能够像人类一样,先粗略地指向目标,然后通过观察和调整逐步提高精度。这种迭代修正的过程借鉴了自然语言处理中推理模型的设计思想,通过多次迭代来逐步逼近最优解。
技术框架:Poivre方法的整体框架包含三个主要步骤:Point(初始指向)、Visualize(可视化指向结果)和Refine(精炼指向)。首先,VLM根据输入图像和文本描述预测一个初始的指向坐标。然后,将该坐标在图像上可视化,例如用一个小的标记圈出该位置。最后,VLM基于原始图像、文本描述以及可视化结果,判断是否需要进一步精炼指向坐标,如果需要,则更新坐标,并重复Visualize和Refine步骤,直到达到预设的迭代次数或满足停止条件。
关键创新:该方法最重要的创新点在于引入了自精炼的迭代过程,并通过强化学习来训练模型具备这种能力。与传统的单步预测方法相比,Poivre方法能够更好地模拟人类的认知过程,通过逐步修正来提高指向精度。此外,使用强化学习来优化迭代策略,使得模型能够学习到更有效的精炼方式。
关键设计:在强化学习训练中,论文设计了一个关键的过程奖励函数。该奖励函数不仅考虑了最终指向的准确性,还考虑了每次迭代的改进程度。具体来说,如果一次迭代使得指向位置更接近目标,则给予正向奖励;反之,则给予负向奖励。这种奖励机制能够激励模型在每次迭代中都朝着正确的方向进行调整。此外,论文还探索了不同的网络结构和参数设置,以优化模型的性能。
🖼️ 关键图片


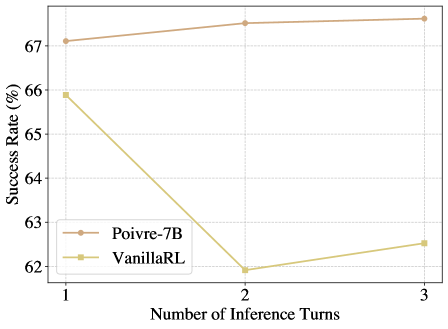
📊 实验亮点
Poivre-7B模型在Point-Bench基准测试中取得了显著的性能提升,超越了包括Gemini-2.5-Pro和Molmo-72B在内的多个先进模型,性能提升超过3%。这一结果表明,所提出的自精炼方法能够有效提高视觉指向的精度,并具有良好的泛化能力。
🎯 应用场景
该研究成果可应用于人机交互、机器人导航、图像编辑等领域。例如,在人机交互中,用户可以通过语音或文本指令引导机器人指向特定物体。在机器人导航中,机器人可以利用视觉指向能力来定位目标物体,从而实现自主导航。在图像编辑中,用户可以通过文本描述来精确地选择图像中的特定区域。
📄 摘要(原文)
Visual pointing, which aims to localize a target by predicting its coordinates on an image, has emerged as an important problem in the realm of vision-language models (VLMs). Despite its broad applicability, recent benchmarks show that current VLMs still fall far behind human performance on this task. A key limitation is that VLMs are typically required to complete the pointing task in a single step, akin to asking humans to point at an object without seeing their own fingers. To address this issue, we propose a simple yet effective self-refining procedure: Point, Visualize, then Refine (Poivre). This procedure enables a VLM to first mark its estimated point, then iteratively refine the coordinates if necessary. Inspired by advances of reasoning models in the natural language domain, we employ reinforcement learning (RL) to incentivize this self-refining ability. For the RL training, we design a neat process reward that is not only empirically effective but also grounded in appealing properties. Our trained model, Poivre-7B, sets a new state of the art on Point-Bench, outperforming both proprietary models such as Gemini-2.5-Pro and large open-source models such as Molmo-72B by over 3%. To support future research, we release our training and inference code, dataset, and the Poivre-7B checkpoint.