LUQ: Layerwise Ultra-Low Bit Quantization for Multimodal Large Language Models
作者: Shubhang Bhatnagar, Andy Xu, Kar-Han Tan, Narendra Ahuja
分类: cs.CV, cs.AI, cs.LG, eess.IV
发布日期: 2025-09-28 (更新: 2025-10-26)
💡 一句话要点
提出LUQ:多模态大语言模型的分层超低比特量化方法,降低内存占用。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态大语言模型 超低比特量化 后训练量化 分层量化 视觉问答 模型压缩 LLaVA Qwen
📋 核心要点
- 多模态大语言模型部署成本高昂,现有后训练量化方法在压缩多模态LLM时效果不佳,尤其是在超低比特量化下。
- LUQ通过分析多模态tokens在不同层的激活分布,选择性地对更具弹性的层应用超低比特量化。
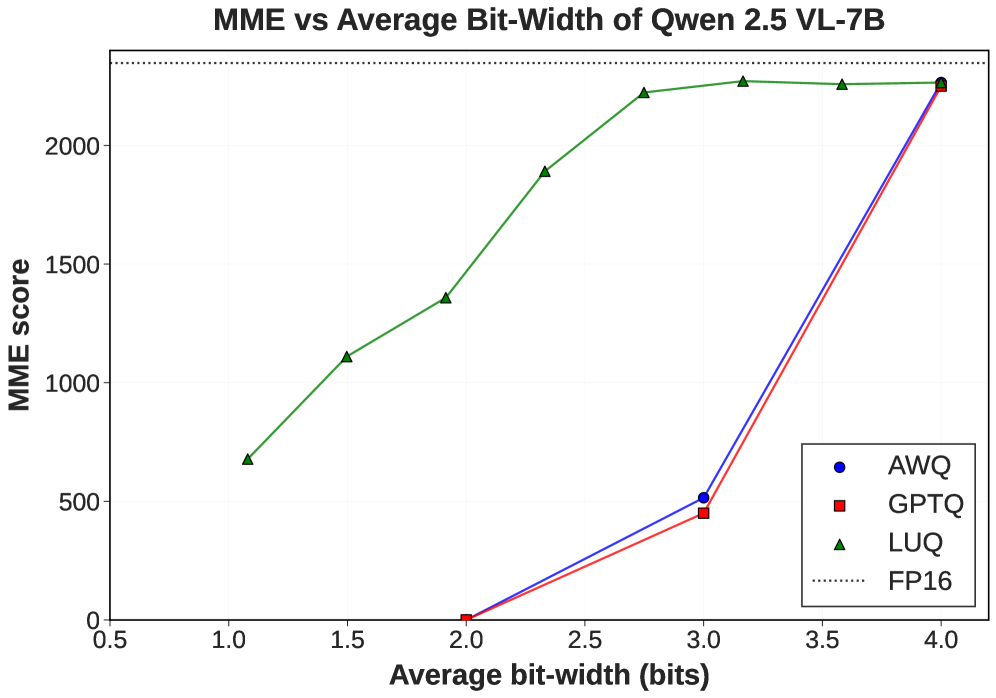
- 实验表明,LUQ在LLaVA-1.5和Qwen-2.5-VL上,显著降低内存占用,同时保持可接受的性能下降。
📝 摘要(中文)
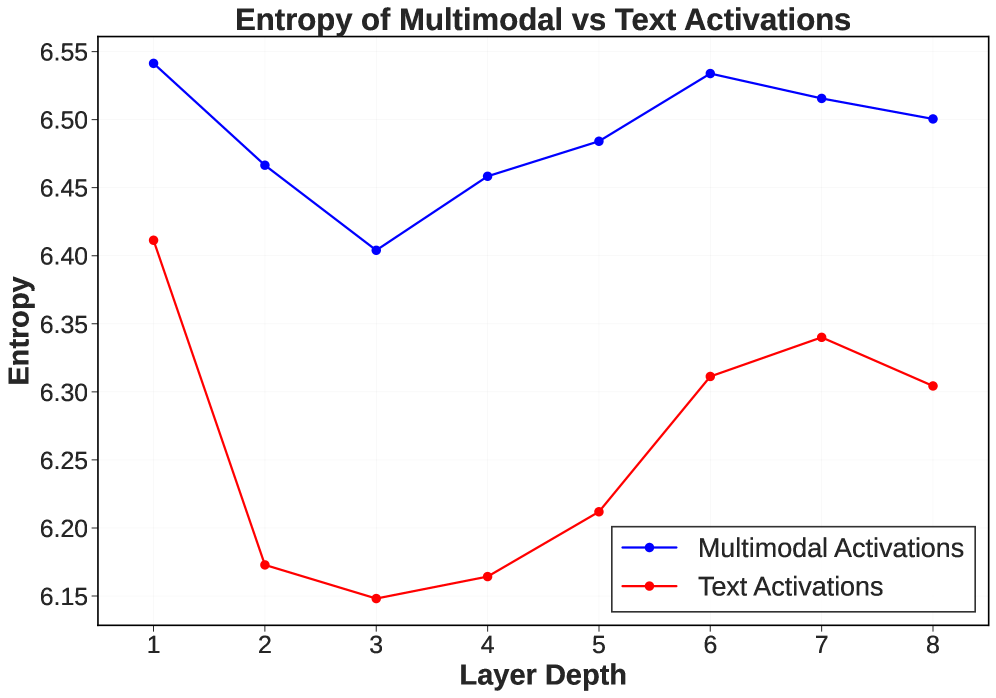
多模态大语言模型(MLLM)彻底改变了视觉-语言任务,但其部署通常需要巨大的内存和计算资源。虽然后训练量化(PTQ)已成功将语言模型压缩到低至1比特精度,而没有显著的性能损失,但其对多模态LLM(MLLM)的有效性仍未得到充分探索。本文首次研究了多模态LLM的超低比特(<4比特)量化。分析表明,与文本tokens相比,多模态tokens及其产生的中间层激活表现出明显更高的统计方差和熵,使其对超低比特量化的容忍度更低。然而,多模态tokens的激活分布在不同层之间差异很大,有些层的激活分布具有较低的熵。经验表明,这些模型中的此类层可以更好地容忍超低比特量化。基于这些见解,我们提出了一种新的MLLM量化策略LUQ:分层超低比特量化,它选择性地将超低比特量化应用于更具弹性的层。此外,我们还表明,在PTQ中使用多模态tokens(图像和文本)的混合可以提高超低比特状态下的VQA性能。我们在LLaVA-1.5和Qwen-2.5-VL上,跨9个流行的VQA基准评估了我们的方法。由此产生的LUQ模型分别比其4比特模型少使用40%和31%的内存,同时在MME基准上的性能下降小于10%。
🔬 方法详解
问题定义:论文旨在解决多模态大语言模型(MLLM)在部署时内存占用过大的问题。现有的后训练量化(PTQ)方法在压缩纯文本LLM时表现良好,但在MLLM上,特别是进行超低比特量化时,性能下降明显。这是因为多模态tokens的激活分布与文本tokens有显著差异,对量化更敏感。
核心思路:论文的核心思路是并非所有层都对超低比特量化同样敏感。通过分析不同层中多模态tokens的激活分布,可以识别出对量化更具鲁棒性的层。然后,选择性地对这些层应用超低比特量化,而对其他层使用更高的比特数,从而在压缩率和性能之间取得平衡。
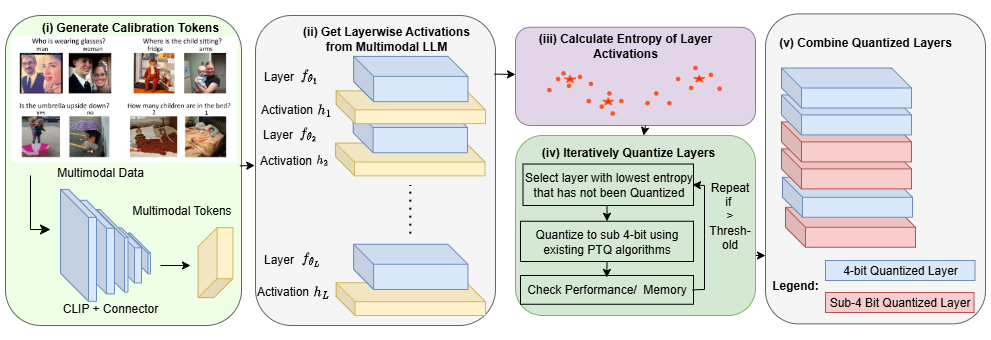
技术框架:LUQ方法主要包含以下几个阶段:1) 分析MLLM中各层的激活分布,特别是多模态tokens的激活分布,计算如熵等统计指标。2) 基于激活分布的分析结果,确定各层对超低比特量化的容忍度。3) 根据容忍度,选择性地对部分层应用超低比特量化(如1-bit或2-bit),而对其他层使用更高的比特数(如4-bit)。4) 使用混合的多模态tokens(图像和文本)进行后训练量化,以进一步提升VQA性能。
关键创新:LUQ的关键创新在于提出了分层量化的思想,即不是对整个模型采用统一的量化策略,而是根据各层的特性,采用不同的量化比特数。这种方法能够更有效地利用模型的冗余性,在保证性能的同时实现更高的压缩率。此外,使用混合的多模态tokens进行PTQ也是一个重要的改进,能够更好地适应视觉-语言任务。
关键设计:论文的关键设计包括:1) 使用熵作为衡量激活分布复杂度的指标,熵越低表示分布越集中,对量化越鲁棒。2) 设计了一种策略来自动或手动选择哪些层进行超低比特量化。3) 在PTQ过程中,使用图像和文本tokens的混合数据,以更好地适应VQA任务。具体的损失函数和网络结构与原始的MLLM保持一致,主要关注量化策略的优化。
🖼️ 关键图片
📊 实验亮点
实验结果表明,LUQ在LLaVA-1.5和Qwen-2.5-VL模型上,分别实现了40%和31%的内存减少,同时在MME基准上的性能下降小于10%。这表明LUQ能够在显著降低内存占用的同时,保持较好的性能水平。此外,使用混合的多模态tokens进行PTQ也显著提升了VQA性能。
🎯 应用场景
LUQ方法可应用于各种视觉-语言任务,例如图像描述、视觉问答、图像检索等。通过降低多模态大语言模型的内存占用,LUQ使得这些模型能够在资源受限的设备上部署,例如移动设备、嵌入式系统等。这有助于推动多模态人工智能技术在实际场景中的应用。
📄 摘要(原文)
Large Language Models (LLMs) with multimodal capabilities have revolutionized vision-language tasks, but their deployment often requires huge memory and computational resources. While post-training quantization (PTQ) has successfully compressed language models to as low as 1-bit precision without significant performance loss, its effectiveness for multimodal LLMs (MLLMs) remains relatively unexplored. In this paper, we present the first study on ultra-low bit (<4-bit) quantization for multimodal LLMs. Our analysis reveals that multimodal tokens and intermediate layer activations produced by them exhibit significantly higher statistical variance and entropy compared to text tokens, making them less tolerant to ultra-low bit quantization. However, the activation distributions of multimodal tokens varies significantly over different layers, with some layers having lower entropy activation distributions. We empirically show that such layers in these models can better tolerate ultra-low bit quantization. Building on these insights, we propose a novel strategy for MLLM quantization, LUQ: Layerwise Ultra-Low Bit Quantization, which selectively applies ultra-low bit quantization to layers that are more resilient to it. Additionally, we also show that using a mix of multimodal tokens (image and text) for PTQ boosts VQA performance in the ultra-low bit regime. We evaluate our method on LLaVA-1.5 and Qwen-2.5-VL across 9 popular VQA benchmarks. The resulting LUQ models use 40% and 31% less memory than their 4-bit counterparts, respectively, while exhibiting a performance degradation of less than 10% on the MME benchmark.