Token Merging via Spatiotemporal Information Mining for Surgical Video Understanding
作者: Xixi Jiang, Chen Yang, Dong Zhang, Pingcheng Dong, Xin Yang, Kwang-Ting Cheng
分类: cs.CV
发布日期: 2025-09-28
💡 一句话要点
提出STIM-TM,通过时空信息挖掘进行手术视频Token融合,提升效率。
🎯 匹配领域: 支柱八:物理动画 (Physics-based Animation)
关键词: 手术视频理解 Token融合 时空信息挖掘 Transformer 视频分析
📋 核心要点
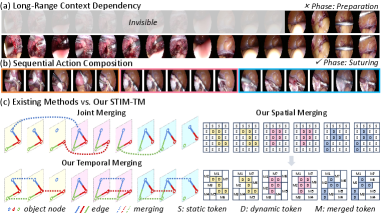
- 现有手术视频理解方法处理大量时空tokens导致计算成本高昂,限制了其在实际手术场景中的应用。
- STIM-TM通过解耦时空维度,分别进行token融合,在时间维度保留序列信息,在空间维度保护动态区域。
- 实验表明,STIM-TM在显著降低计算量的同时,保持了具有竞争力的准确性,并支持长序列视频训练。
📝 摘要(中文)
本文提出了一种时空信息挖掘Token融合(STIM-TM)方法,这是首个专门为手术视频理解设计的方案。现有方法在处理视频帧中大量的时空tokens时,计算成本过高。虽然之前的token融合工作提高了模型效率,但它们未能充分考虑视频数据的固有时空结构,并忽略了信息分布的异构性,导致性能欠佳。STIM-TM引入了一种解耦策略,独立地减少时间和空间维度上的token冗余。具体而言,时间组件使用显著性加权融合来自连续帧的空间对应tokens,保留关键的序列信息并保持连续性。同时,空间组件通过时间稳定性分析,优先融合静态tokens,保护包含重要手术信息的动态区域。STIM-TM以无训练方式运行,在全面的手术视频任务中实现了显著的效率提升,GFLOPs减少超过65%,同时保持了具有竞争力的准确性。该方法还支持长序列手术视频的有效训练,解决了手术应用中的计算瓶颈。
🔬 方法详解
问题定义:手术视频理解任务需要处理大量的时空tokens,导致计算复杂度极高,现有方法难以兼顾效率与精度。之前的token融合方法未能充分利用视频数据的时空结构,忽略了信息分布的异构性,导致性能下降。
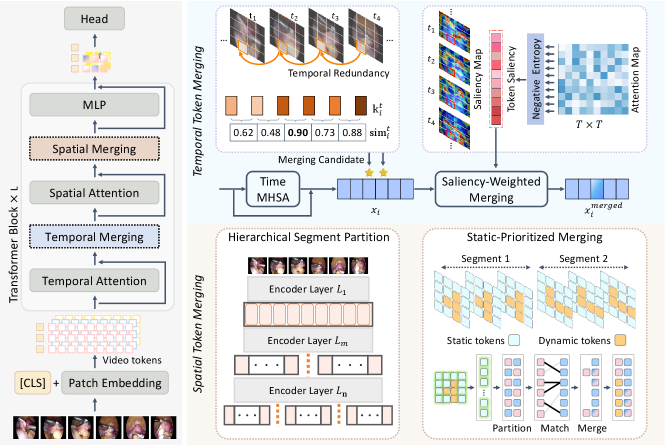
核心思路:本文的核心思路是解耦时间和空间维度,分别进行token融合。在时间维度上,通过显著性加权融合连续帧的对应tokens,保留关键的序列信息。在空间维度上,通过时间稳定性分析,优先融合静态tokens,保护包含重要手术信息的动态区域。这种解耦策略能够更有效地减少冗余,同时保留重要信息。
技术框架:STIM-TM方法包含两个主要组件:时间组件和空间组件。时间组件负责在时间维度上进行token融合,空间组件负责在空间维度上进行token融合。这两个组件独立运行,共同减少整体的token数量。整个过程无需训练,可以直接应用于现有的Transformer模型。
关键创新:STIM-TM的关键创新在于其解耦的时空信息挖掘策略。与之前的token融合方法不同,STIM-TM充分考虑了视频数据的时空结构,并根据不同维度的信息重要性进行差异化处理。这种方法能够更有效地减少冗余,同时保留关键信息,从而在降低计算量的同时保持甚至提升性能。
关键设计:在时间组件中,使用显著性加权来融合连续帧的对应tokens,显著性权重可以基于注意力机制或其他方法计算。在空间组件中,使用时间稳定性分析来判断tokens的静态程度,稳定性可以通过计算连续帧之间token特征的差异来衡量。具体的参数设置和网络结构可以根据具体的任务和数据集进行调整。
🖼️ 关键图片

📊 实验亮点
STIM-TM方法在手术视频任务中实现了超过65%的GFLOPs减少,同时保持了具有竞争力的准确性。实验结果表明,该方法能够显著降低计算成本,并支持长序列手术视频的有效训练。与现有token融合方法相比,STIM-TM在效率和精度上都取得了更好的平衡。
🎯 应用场景
该研究成果可应用于手术机器人辅助、手术导航、术后分析等领域。通过降低手术视频理解的计算成本,可以实现更快速、更准确的手术过程分析和决策支持,提升手术效率和安全性。未来,该方法有望推广到其他长序列视频理解任务中,例如自动驾驶、监控视频分析等。
📄 摘要(原文)
Vision Transformer models have shown impressive effectiveness in the surgical video understanding tasks through long-range dependency modeling. However, current methods suffer from prohibitive computational costs due to processing massive spatiotemporal tokens across video frames. While prior work on token merging has advanced model efficiency, they fail to adequately consider the inherent spatiotemporal structure of video data and overlook the heterogeneous nature of information distribution, leading to suboptimal performance. In this paper, we propose a spatiotemporal information mining token merging (STIM-TM) method, representing the first dedicated approach for surgical video understanding. STIM-TM introduces a decoupled strategy that reduces token redundancy along temporal and spatial dimensions independently. Specifically, the temporal component merges spatially corresponding tokens from consecutive frames using saliency weighting, preserving critical sequential information and maintaining continuity. Meanwhile, the spatial component prioritizes merging static tokens through temporal stability analysis, protecting dynamic regions containing essential surgical information. Operating in a training-free manner, STIM-TM achieves significant efficiency gains with over $65\%$ GFLOPs reduction while preserving competitive accuracy across comprehensive surgical video tasks. Our method also supports efficient training of long-sequence surgical videos, addressing computational bottlenecks in surgical applications.