HIVTP: A Training-Free Method to Improve VLMs Efficiency via Hierarchical Visual Token Pruning Using Middle-Layer-Based Importance Score
作者: Jingqi Xu, Jingxi Lu, Chenghao Li, Sreetama Sarkar, Peter A. Beerel
分类: cs.CV
发布日期: 2025-09-28 (更新: 2025-10-09)
💡 一句话要点
提出HIVTP,一种免训练的分层视觉Token剪枝方法,提升VLM推理效率。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 视觉语言模型 Token剪枝 推理加速 注意力机制 分层剪枝
📋 核心要点
- 现有VLM模型推理效率受限于视觉编码器产生的大量视觉token,其中许多token重要性较低,存在冗余。
- HIVTP利用视觉编码器中间层的注意力图评估token重要性,并设计分层剪枝策略,保留全局和局部重要token。
- 实验表明,HIVTP在不牺牲甚至提升准确率的前提下,显著降低了TTFT并提高了token生成吞吐量,优于现有方法。
📝 摘要(中文)
视觉-语言模型(VLM)在各种多模态任务中表现出强大的能力。然而,视觉编码器输出的大量视觉token严重阻碍了推理效率,并且先前的研究表明,许多这些token并不重要,因此可以安全地进行剪枝。在这项工作中,我们提出HIVTP,一种免训练的方法,通过使用基于中间层重要性分数的层次视觉token剪枝来提高VLM的效率。具体来说,我们利用从视觉编码器的中间层提取的注意力图来估计视觉token的重要性,这些注意力图更好地反映了细粒度和对象级别的注意力。基于此,我们提出了一种分层视觉token剪枝方法,以保留全局和局部重要的视觉token。具体来说,我们将视觉编码器输出的1-D视觉token序列重塑为2-D空间布局。在全局保留阶段,我们将图像划分为区域,并保留每个区域中具有较高重要性分数的token;在局部保留阶段,我们然后将图像划分为小窗口,并保留每个局部窗口中最重要的token。实验结果表明,我们提出的方法HIVTP可以将LLaVA-v1.5-7B和LLaVA-Next-7B的time-to-first-token (TTFT) 分别降低高达50.0%和55.1%,并将token生成吞吐量提高高达60.9%和47.3%,而不会牺牲准确性,甚至在某些基准测试中实现了改进。与先前的工作相比,HIVTP在提供更高推理效率的同时,实现了更好的准确性。
🔬 方法详解
问题定义:VLM模型在推理时,视觉编码器产生大量的视觉token,这些token数量庞大,导致计算开销大,推理速度慢。现有方法无法有效区分重要和不重要的token,导致效率低下。因此,需要一种方法能够在不损失模型性能的前提下,减少视觉token的数量,提高推理效率。
核心思路:论文的核心思路是通过剪枝掉不重要的视觉token来减少计算量,从而提高VLM的推理效率。关键在于如何准确评估每个token的重要性,并设计有效的剪枝策略。论文选择使用视觉编码器中间层的注意力图来评估token的重要性,因为中间层能够更好地反映细粒度和对象级别的注意力。
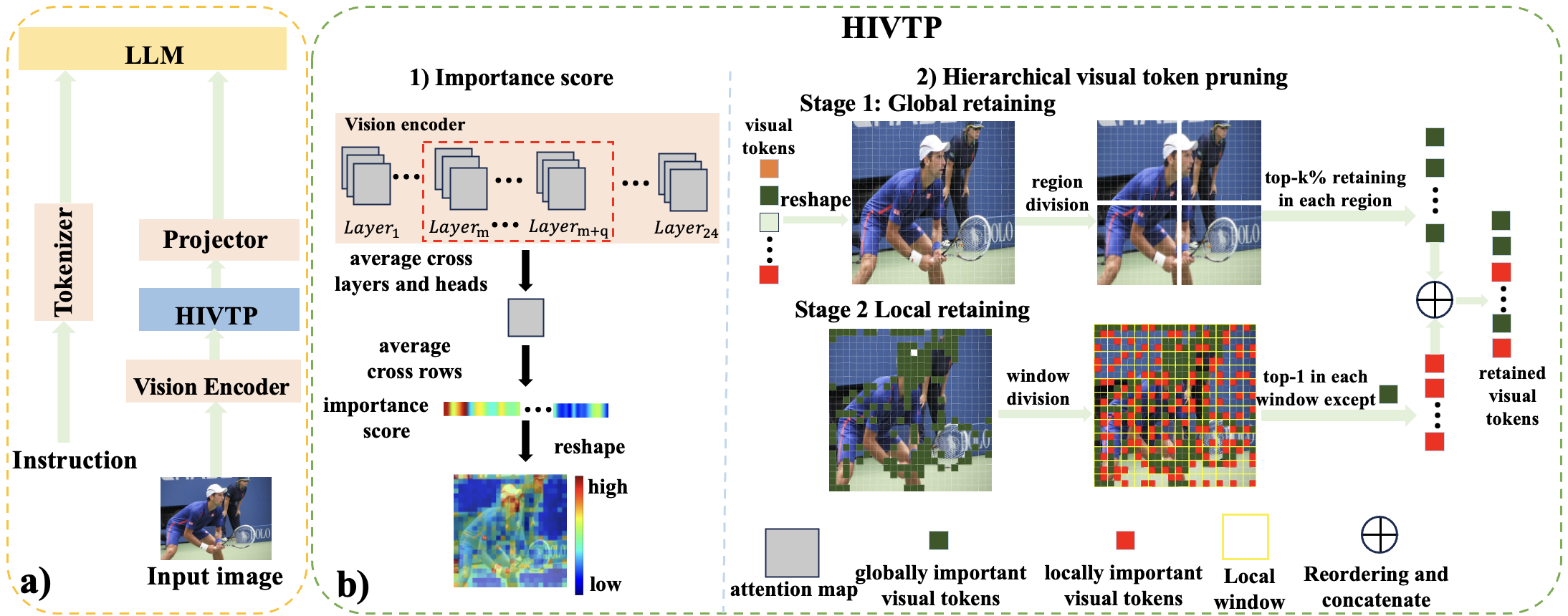
技术框架:HIVTP方法包含以下几个主要步骤:1) 从视觉编码器的中间层提取注意力图;2) 基于注意力图计算每个视觉token的重要性分数;3) 将1D的token序列reshape成2D空间布局;4) 进行分层剪枝,包括全局保留和局部保留两个阶段。全局保留阶段将图像划分为区域,保留每个区域中重要性分数较高的token。局部保留阶段将图像划分为小窗口,保留每个窗口中最重要的token。
关键创新:HIVTP的关键创新在于:1) 使用视觉编码器中间层的注意力图来评估token的重要性,相比于使用最后一层的注意力图,中间层能更好地捕捉细粒度的信息;2) 提出了分层剪枝策略,同时考虑了全局和局部的token重要性,保证了剪枝后的模型性能。3) 提出了一种免训练的剪枝方法,无需额外的训练开销。
关键设计:在全局保留阶段,图像被划分为大小相等的区域,每个区域保留的token数量是一个超参数。在局部保留阶段,图像被划分为大小相等的小窗口,每个窗口只保留一个token。具体区域和窗口的大小需要根据实际情况进行调整。重要性分数的计算方式是基于注意力图的加权平均,权重可以是固定的,也可以是可学习的。
🖼️ 关键图片


📊 实验亮点
实验结果表明,HIVTP方法在LLaVA-v1.5-7B和LLaVA-Next-7B模型上分别实现了高达50.0%和55.1%的TTFT降低,以及高达60.9%和47.3%的token生成吞吐量提升。更重要的是,在这些显著的效率提升的同时,模型的准确率并没有下降,甚至在某些基准测试中还略有提升。这表明HIVTP方法能够在不牺牲模型性能的前提下,有效地提高VLM的推理效率。
🎯 应用场景
HIVTP方法可以广泛应用于各种需要高效VLM推理的场景,例如移动设备上的图像描述、实时视频分析、以及资源受限环境下的多模态对话等。通过减少计算量,该方法可以降低硬件需求,并加速VLM的应用落地,具有重要的实际价值和广泛的应用前景。
📄 摘要(原文)
Vision-Language Models (VLMs) have shown strong capabilities on diverse multimodal tasks. However, the large number of visual tokens output by the vision encoder severely hinders inference efficiency, and prior studies have shown that many of these tokens are not important and can therefore be safely pruned. In this work, we propose HIVTP, a training-free method to improve VLMs efficiency via hierarchical visual token pruning using a novel middle-layer-based importance score. Specifically, we utilize attention maps extracted from the middle layers of the vision encoder, which better reflect fine-grained and object-level attention, to estimate visual token importance. Based on this, we propose a hierarchical visual token pruning method to retain both globally and locally important visual tokens. Specifically, we reshape the 1-D visual token sequence output by the vision encoder into a 2-D spatial layout. In the global retaining stage, we divide the image into regions and retain tokens with higher importance scores in each region; in the local retaining stage, we then divide the image into small windows and retain the most important token in each local window. Experimental results show that our proposed method, HIVTP, can reduce the time-to-first-token (TTFT) of LLaVA-v1.5-7B and LLaVA-Next-7B by up to 50.0% and 55.1%, respectively, and improve the token generation throughput by up to 60.9% and 47.3%, without sacrificing accuracy, and even achieving improvements on certain benchmarks. Compared with prior works, HIVTP achieves better accuracy while offering higher inference efficiency.