LLaVA-OneVision-1.5: Fully Open Framework for Democratized Multimodal Training
作者: Xiang An, Yin Xie, Kaicheng Yang, Wenkang Zhang, Xiuwei Zhao, Zheng Cheng, Yirui Wang, Songcen Xu, Changrui Chen, Didi Zhu, Chunsheng Wu, Huajie Tan, Chunyuan Li, Jing Yang, Jie Yu, Xiyao Wang, Bin Qin, Yumeng Wang, Zizhen Yan, Ziyong Feng, Ziwei Liu, Bo Li, Jiankang Deng
分类: cs.CV
发布日期: 2025-09-28 (更新: 2025-12-14)
备注: LLaVA-OneVision-1.5 Technical Report
💡 一句话要点
LLaVA-OneVision-1.5:全开放多模态训练框架,降低训练成本并提升性能
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态学习 视觉语言模型 开放框架 高效训练 强化学习 指令学习 数据集构建
📋 核心要点
- 现有大型多模态模型训练成本高昂,且缺乏完全开放的、可复现的训练框架,限制了研究的民主化。
- LLaVA-OneVision-1.5 通过构建大规模数据集、设计高效训练框架和引入强化学习后训练,降低训练成本并提升性能。
- 实验表明,LLaVA-OneVision-1.5 在多个基准测试中超越了 Qwen2.5-VL 系列模型,展现了卓越的性能。
📝 摘要(中文)
LLaVA-OneVision-1.5 是一系列新型大型多模态模型(LMM),它以显著降低的计算和财务成本实现了最先进的性能。与现有工作不同,LLaVA-OneVision-1.5 提供了一个开放、高效且可复现的框架,用于从头开始构建高质量的视觉-语言模型。LLaVA-OneVision-1.5 的发布包含三个主要组成部分:(1)大规模精选数据集:我们构建了一个 8500 万概念平衡的预训练数据集 LLaVA-OneVision-1.5-Mid-Traning 和一个精心策划的 2200 万指令数据集 LLaVA-OneVision-1.5-Instruct。(2)高效训练框架:我们开发了一个完整的端到端高效训练框架,利用离线并行数据打包策略,以促进在 16,000 美元预算内训练 LLaVA-OneVision-1.5。(3)最先进的性能:实验结果表明,LLaVA-OneVision-1.5 在广泛的下游任务中产生了极具竞争力的性能。具体而言,LLaVA-OneVision-1.5-8B 在 27 个基准测试中的 18 个上优于 Qwen2.5-VL-7B,而 LLaVA-OneVision-1.5-4B 在所有 27 个基准测试上都超过了 Qwen2.5-VL-3B。(4)基于强化学习的后训练:我们通过轻量级的强化学习阶段释放了模型的潜在能力,有效地引发了强大的思维链推理,从而显著提高了复杂多模态推理任务的性能。
🔬 方法详解
问题定义:论文旨在解决大型多模态模型训练成本高昂,以及缺乏完全开放、高效且可复现的训练框架的问题。现有方法通常需要大量的计算资源和资金投入,并且训练流程不透明,难以复现和改进。
核心思路:论文的核心思路是构建一个完全开放的、低成本的训练框架,通过精心策划的数据集、高效的训练策略和强化学习后训练,在有限的资源下训练出具有竞争力的多模态模型。这种设计旨在降低多模态模型研究的门槛,促进更广泛的研究和应用。
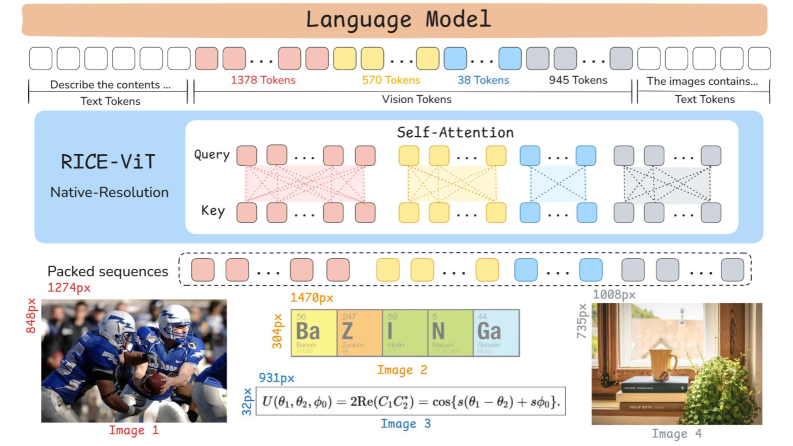
技术框架:LLaVA-OneVision-1.5 的整体框架包含三个主要阶段:(1) 数据准备阶段:构建大规模的概念平衡预训练数据集 LLaVA-OneVision-1.5-Mid-Traning 和精心策划的指令数据集 LLaVA-OneVision-1.5-Instruct。(2) 高效训练阶段:利用离线并行数据打包策略,在有限的计算资源下进行模型训练。(3) 强化学习后训练阶段:通过强化学习进一步提升模型在复杂多模态推理任务上的性能。
关键创新:论文的关键创新在于提供了一个完全开放且低成本的多模态模型训练框架。具体体现在:(1) 数据集的构建过程完全公开,方便研究者复现和改进。(2) 训练框架的设计注重效率,能够在有限的资源下训练出高性能的模型。(3) 引入强化学习后训练,进一步提升了模型在复杂任务上的推理能力。与现有方法相比,LLaVA-OneVision-1.5 更加注重开放性和可复现性,降低了研究门槛。
关键设计:论文的关键设计包括:(1) 概念平衡的预训练数据集,旨在提高模型的泛化能力。(2) 离线并行数据打包策略,旨在提高训练效率。(3) 基于强化学习的后训练方法,旨在提升模型的推理能力。具体的参数设置、损失函数和网络结构等技术细节在论文中进行了详细描述,此处未知。
🖼️ 关键图片
📊 实验亮点
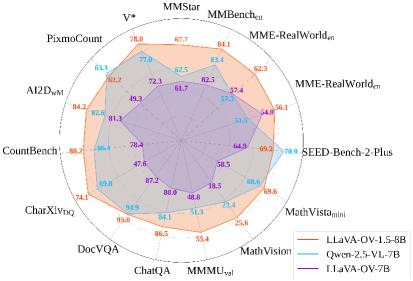
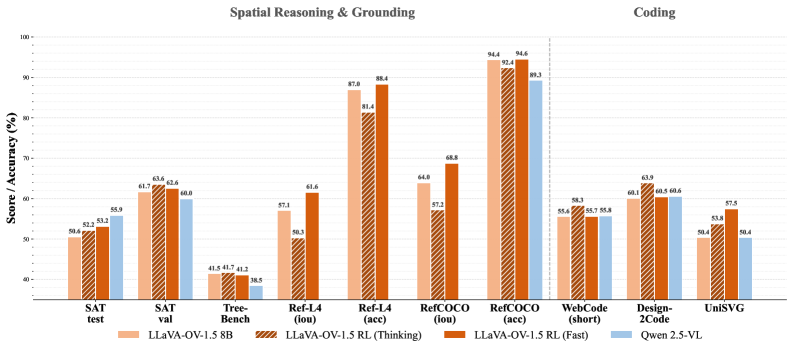
LLaVA-OneVision-1.5-8B 在 27 个基准测试中的 18 个上优于 Qwen2.5-VL-7B,而 LLaVA-OneVision-1.5-4B 在所有 27 个基准测试上都超过了 Qwen2.5-VL-3B。此外,通过强化学习后训练,模型在复杂多模态推理任务上的性能得到了显著提升,表明了该框架的有效性。
🎯 应用场景
LLaVA-OneVision-1.5 可应用于智能问答、图像理解、视觉推理、机器人导航等领域。其低成本和高性能的特点使其在资源受限的环境下也能发挥重要作用,例如在移动设备或嵌入式系统中部署智能视觉应用。该研究的开放性也将促进多模态模型在更广泛领域的应用和发展。
📄 摘要(原文)
We present LLaVA-OneVision-1.5, a novel family of Large Multimodal Models (LMMs) that achieve state-of-the-art performance with significantly reduced computational and financial costs. Different from the existing works, LLaVA-OneVision-1.5 provides an open, efficient, and reproducible framework for building high-quality vision-language models entirely from scratch. The LLaVA-OneVision-1.5 release comprises three primary components: (1) Large-Scale Curated Datasets: We construct an 85M concept-balanced pretraining dataset LLaVA-OneVision-1.5-Mid-Traning and a meticulously curated 22M instruction dataset LLaVA-OneVision-1.5-Instruct. (2) Efficient Training Framework: We develop a complete end-to-end efficient training framework leveraging an offline parallel data packing strategy to facilitate the training of LLaVA-OneVision-1.5 within a $16,000 budget. (3) State-of-the-art Performance: Experimental results demonstrate that LLaVA-OneVision-1.5 yields exceptionally competitive performance across a broad range of downstream tasks. Specifically, LLaVA-OneVision-1.5-8B outperforms Qwen2.5-VL-7B on 18 of 27 benchmarks, and LLaVA-OneVision-1.5-4B surpasses Qwen2.5-VL-3B on all 27 benchmarks. (4) RL-based Post-training: We unlock the model's latent potential through a lightweight RL stage, effectively eliciting robust chain-of-thought reasoning to significantly boost performance on complex multimodal reasoning tasks.