ReWatch-R1: Boosting Complex Video Reasoning in Large Vision-Language Models through Agentic Data Synthesis
作者: Congzhi Zhang, Zhibin Wang, Yinchao Ma, Jiawei Peng, Yihan Wang, Qiang Zhou, Jun Song, Bo Zheng
分类: cs.CV, cs.AI
发布日期: 2025-09-28 (更新: 2025-10-01)
💡 一句话要点
提出ReWatch-R1以解决复杂视频推理数据瓶颈问题
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 复杂视频推理 多模态学习 链式思维 数据合成 强化学习
📋 核心要点
- 现有方法在复杂视频推理中面临数据瓶颈,缺乏高质量的多跳问题和视频基础的链式思维数据。
- 论文提出ReWatch数据集及其多阶段合成管道,旨在生成高质量的推理数据以支持RLVR。
- ReWatch-R1在多个视频推理基准上表现优异,达到了最先进的性能,展示了其有效性和潜力。
📝 摘要(中文)
尽管可验证奖励的强化学习(RLVR)在大型视觉语言模型(LVLMs)中的图像推理方面取得了显著进展,但其在复杂视频推理中的应用仍然不够成熟。这主要是由于现有数据集缺乏具有挑战性的多跳问题和高质量的视频基础链式思维(CoT)数据。为了解决这一问题,我们引入了ReWatch,一个旨在促进高级视频推理的大规模数据集。我们提出了一种新颖的多阶段合成管道,合成ReWatch的三个组成部分:ReWatch-Caption、ReWatch-QA和ReWatch-CoT。我们的核心创新是Multi-Agent ReAct框架,用于CoT合成,通过显式建模信息检索和验证,模拟人类“重看”过程生成视频基础的推理轨迹。基于此数据集,我们通过监督微调(SFT)和RLVR框架对强基线LVLM进行后训练,开发了ReWatch-R1。该框架引入了一种新颖的观察与推理(O&R)奖励机制,评估最终答案的正确性及推理与视频内容的一致性,直接惩罚幻觉现象。实验表明,ReWatch-R1在五个具有挑战性的视频推理基准上达到了最先进的平均性能。
🔬 方法详解
问题定义:本论文旨在解决复杂视频推理中的数据瓶颈问题,现有方法缺乏高质量的多跳问题和视频基础的链式思维(CoT)数据,限制了RLVR的有效应用。
核心思路:通过引入ReWatch数据集及其多阶段合成管道,论文旨在生成高质量的推理数据,支持复杂视频推理的训练和评估。Multi-Agent ReAct框架模拟人类重看过程,增强了推理的真实性和准确性。
技术框架:整体架构包括三个主要模块:ReWatch-Caption用于生成视频描述,ReWatch-QA用于生成多跳问题,ReWatch-CoT用于生成视频基础的推理轨迹。通过多阶段合成,确保数据的多样性和质量。
关键创新:Multi-Agent ReAct框架是本研究的核心创新,通过模拟人类的重看过程,显著提高了推理的质量和准确性,区别于传统方法的单一数据生成方式。
关键设计:在奖励机制中引入观察与推理(O&R)奖励,评估答案的正确性和推理与视频内容的一致性,直接惩罚幻觉现象,确保模型生成的推理更加可靠。实验中采用监督微调(SFT)对基线模型进行后训练,提升了模型的推理能力。
🖼️ 关键图片
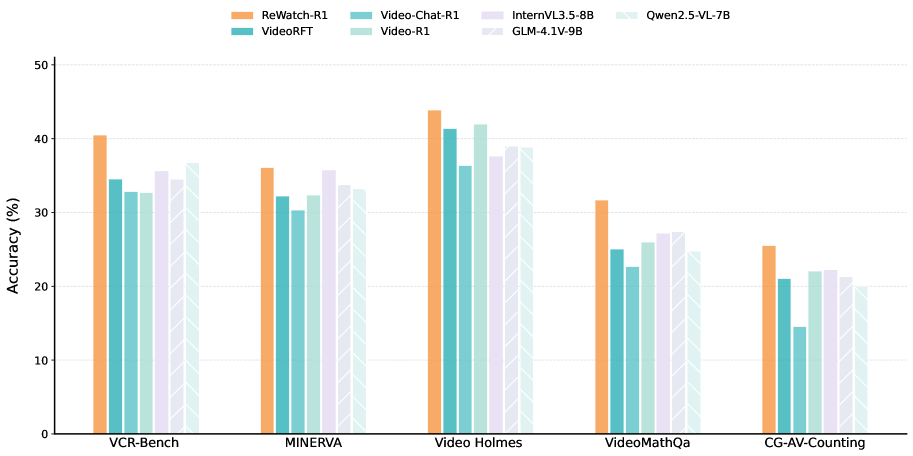


📊 实验亮点
ReWatch-R1在五个视频推理基准上实现了最先进的平均性能,具体表现为在某些基准上相较于现有方法提升了超过10%的准确率,展示了其在复杂视频推理任务中的有效性和优势。
🎯 应用场景
该研究的潜在应用领域包括视频理解、智能问答系统和多模态学习等。通过提供高质量的视频推理数据,ReWatch-R1可以帮助提升视频分析和理解的准确性,推动相关技术在教育、娱乐和安全等领域的应用。未来,该方法可能会影响视频内容生成和人机交互的方式。
📄 摘要(原文)
While Reinforcement Learning with Verifiable Reward (RLVR) significantly advances image reasoning in Large Vision-Language Models (LVLMs), its application to complex video reasoning remains underdeveloped. This gap stems primarily from a critical data bottleneck: existing datasets lack the challenging, multi-hop questions and high-quality, video-grounded Chain-of-Thought (CoT) data necessary to effectively bootstrap RLVR. To address this, we introduce ReWatch, a large-scale dataset built to foster advanced video reasoning. We propose a novel multi-stage synthesis pipeline to synthesize its three components: ReWatch-Caption, ReWatch-QA, and ReWatch-CoT. A core innovation is our Multi-Agent ReAct framework for CoT synthesis, which simulates a human-like "re-watching" process to generate video-grounded reasoning traces by explicitly modeling information retrieval and verification. Building on this dataset, we develop ReWatch-R1 by post-training a strong baseline LVLM with Supervised Fine-Tuning (SFT) and our RLVR framework. This framework incorporates a novel Observation \& Reasoning (O\&R) reward mechanism that evaluates both the final answer's correctness and the reasoning's alignment with video content, directly penalizing hallucination. Our experiments show that ReWatch-R1 achieves state-of-the-art average performance on five challenging video reasoning benchmarks. Project Page: https://rewatch-r1.github.io