Sparse-Up: Learnable Sparse Upsampling for 3D Generation with High-Fidelity Textures
作者: Lu Xiao, Jiale Zhang, Yang Liu, Taicheng Huang, Xin Tian
分类: cs.CV
发布日期: 2025-09-28
💡 一句话要点
Sparse-Up:用于高保真纹理3D生成的可学习稀疏上采样
🎯 匹配领域: 支柱七:动作重定向 (Motion Retargeting)
关键词: 3D生成 纹理建模 稀疏体素 表面锚定 视角域划分 高保真 可学习上采样
📋 核心要点
- 现有3D生成方法在高保真纹理建模方面存在不足,难以兼顾跨视角一致性和高分辨率细节。
- Sparse-Up通过稀疏体素引导纹理重建,并引入表面锚定和视角域划分来突破分辨率限制,提升纹理质量。
- Sparse-Up通过表面锚定减少冗余体素,通过视角域划分降低内存消耗,实现了高效的高分辨率纹理建模。
📝 摘要(中文)
高保真3D资产的创建常常受限于“像素级痛点”:高频细节的丢失。现有方法通常顾此失彼:要么牺牲跨视角一致性,导致纹理撕裂或漂移,要么受限于显式体素的分辨率上限,放弃精细的纹理细节。本文提出了Sparse-Up,一种内存高效的高保真纹理建模框架,有效保留高频细节。我们使用稀疏体素来指导纹理重建并确保多视角一致性,同时利用表面锚定和视角域划分来突破分辨率约束。表面锚定采用可学习的上采样策略,将体素约束到网格表面,消除了传统体素上采样中超过70%的冗余体素。视角域划分引入了一种图像块引导的体素划分方案,仅对可见的局部块进行监督和反向传播梯度。通过这两种策略,我们可以在高分辨率体素训练期间显著降低内存消耗,同时不牺牲几何一致性,并保留纹理中的高频细节。
🔬 方法详解
问题定义:现有3D生成方法在生成高保真纹理时面临挑战。显式体素方法受限于内存消耗,难以达到高分辨率;而其他方法可能牺牲跨视角一致性,导致纹理出现撕裂或漂移等问题。因此,如何在保证跨视角一致性的前提下,生成具有丰富高频细节的高分辨率纹理是一个亟待解决的问题。
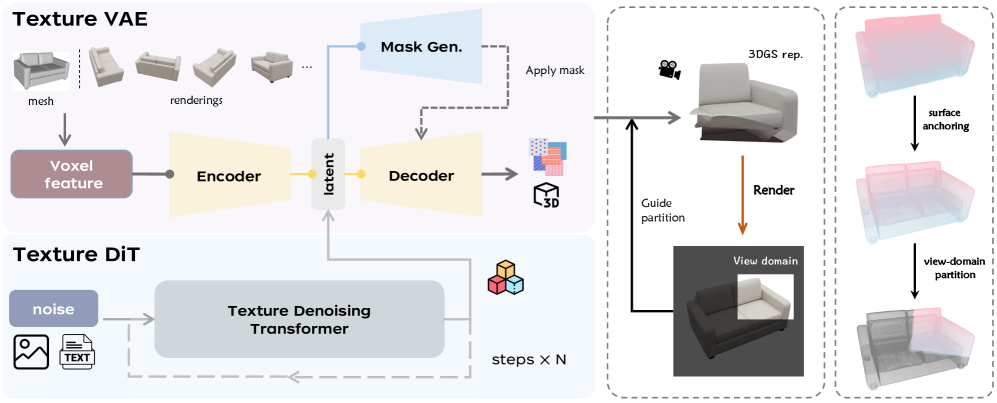
核心思路:Sparse-Up的核心思路是利用稀疏体素作为几何先验,指导纹理重建,并采用表面锚定和视角域划分两种策略来突破分辨率限制并降低内存消耗。表面锚定将体素约束在网格表面,减少冗余体素;视角域划分仅对可见局部区域进行监督,降低计算量。
技术框架:Sparse-Up框架主要包含以下几个阶段:1) 使用稀疏体素表示场景几何;2) 利用表面锚定策略,通过可学习的上采样方法将体素约束到网格表面;3) 采用视角域划分策略,根据图像块的可见性对体素进行划分;4) 使用划分后的体素进行纹理重建,并利用图像块进行监督训练。
关键创新:Sparse-Up的关键创新在于表面锚定和视角域划分两种策略。表面锚定通过可学习的上采样方法,有效地减少了冗余体素,降低了内存消耗。视角域划分则通过仅对可见区域进行监督,进一步降低了计算量,使得高分辨率纹理建模成为可能。与现有方法相比,Sparse-Up能够在保证跨视角一致性的前提下,生成具有更高分辨率和更丰富细节的纹理。
关键设计:表面锚定采用可学习的上采样模块,该模块通过学习到的权重将低分辨率体素特征映射到高分辨率体素特征。视角域划分则根据图像块的可见性,为每个体素分配一个权重,只有可见的体素才参与损失计算和梯度反向传播。损失函数包括纹理重建损失和几何一致性损失,用于保证纹理质量和几何结构的准确性。具体的网络结构和参数设置在论文中有详细描述。
🖼️ 关键图片


📊 实验亮点
论文提出的Sparse-Up方法在实验中取得了显著的效果。通过表面锚定,Sparse-Up能够消除超过70%的冗余体素,显著降低内存消耗。实验结果表明,Sparse-Up能够在保证几何一致性的前提下,生成具有更高分辨率和更丰富细节的纹理。与现有方法相比,Sparse-Up在纹理质量和渲染效果方面均有明显提升。
🎯 应用场景
Sparse-Up技术可广泛应用于游戏开发、电影制作、虚拟现实/增强现实等领域,用于生成高质量的3D资产。该技术能够显著提升3D模型的真实感和细节表现力,为用户带来更沉浸式的体验。未来,Sparse-Up有望应用于自动驾驶、机器人等领域,为环境感知和场景理解提供更精确的3D模型。
📄 摘要(原文)
The creation of high-fidelity 3D assets is often hindered by a 'pixel-level pain point': the loss of high-frequency details. Existing methods often trade off one aspect for another: either sacrificing cross-view consistency, resulting in torn or drifting textures, or remaining trapped by the resolution ceiling of explicit voxels, forfeiting fine texture detail. In this work, we propose Sparse-Up, a memory-efficient, high-fidelity texture modeling framework that effectively preserves high-frequency details. We use sparse voxels to guide texture reconstruction and ensure multi-view consistency, while leveraging surface anchoring and view-domain partitioning to break through resolution constraints. Surface anchoring employs a learnable upsampling strategy to constrain voxels to the mesh surface, eliminating over 70% of redundant voxels present in traditional voxel upsampling. View-domain partitioning introduces an image patch-guided voxel partitioning scheme, supervising and back-propagating gradients only on visible local patches. Through these two strategies, we can significantly reduce memory consumption during high-resolution voxel training without sacrificing geometric consistency, while preserving high-frequency details in textures.