InteractMove: Text-Controlled Human-Object Interaction Generation in 3D Scenes with Movable Objects
作者: Xinhao Cai, Minghang Zheng, Xin Jin, Yang Liu
分类: cs.CV, cs.AI
发布日期: 2025-09-28
💡 一句话要点
InteractMove:提出一种文本控制的3D场景中可移动物体人机交互生成方法
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱三:空间感知与语义 (Perception & Semantics) 支柱四:生成式动作 (Generative Motion) 支柱五:交互与反应 (Interaction & Reaction) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 人机交互 3D场景 可移动物体 文本控制 可供性学习
📋 核心要点
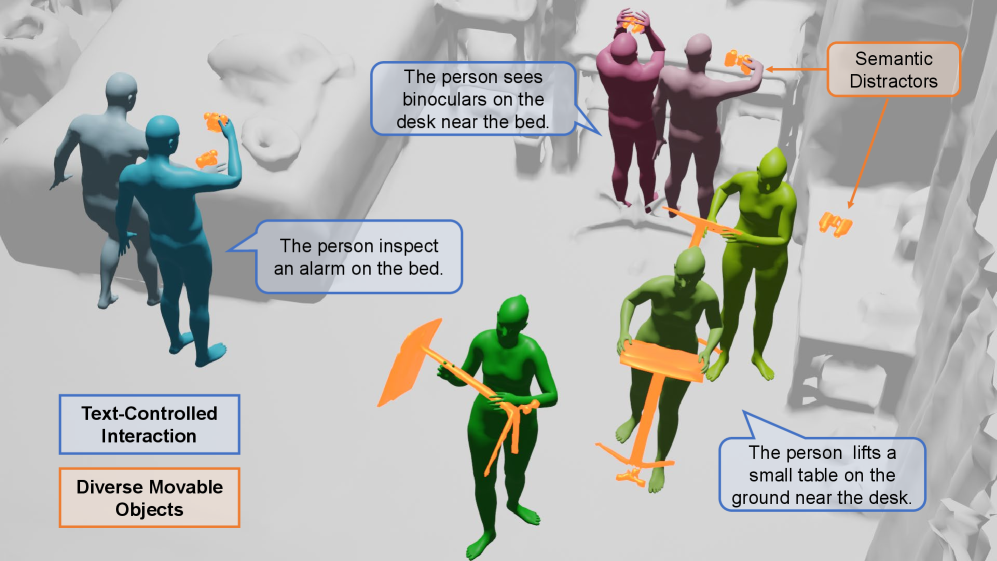
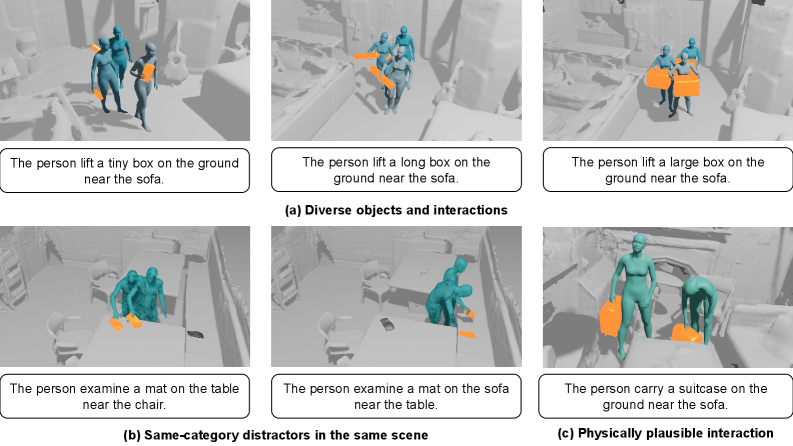
- 现有数据集缺乏对可移动物体人机交互的建模,限制了3D场景交互的真实性和多样性。
- 提出InteractMove数据集和一套包含3D视觉定位、可供性学习和碰撞避免的交互生成流程。
- 实验证明,该方法能生成更符合文本描述且物理上合理的交互,优于现有方法。
📝 摘要(中文)
本文提出了一项新的任务,即在具有可移动物体的3D场景中生成文本控制的人机交互。现有人机交互数据集存在交互类别不足的问题,并且通常只考虑与静态物体的交互(不改变物体位置),而收集此类包含可移动物体的数据集既困难又昂贵。为了解决这个问题,我们构建了InteractMove数据集,用于3D场景中可移动的人机交互,该数据集具有三个关键特征:1)包含多个可移动物体的场景,具有文本控制的交互规范(包括需要空间和3D场景上下文理解的同类别干扰物);2)具有不同交互模式(单手、双手等)的多样化的物体类型和尺寸;3)物理上合理的物体操作轨迹。由于引入了各种可移动物体,这项任务变得更具挑战性,因为模型需要准确识别要交互的物体,学习与不同尺寸和类别的物体进行交互,并避免可移动物体与场景之间的碰撞。为了应对这些挑战,我们提出了一种新的流水线解决方案。我们首先使用3D视觉定位模型来识别交互对象。然后,我们提出了一种手-物联合可供性学习方法,以预测不同手部关节和物体部位的接触区域,从而能够准确地抓取和操作各种物体。最后,我们通过局部场景建模和碰撞避免约束来优化交互,确保物理上合理的运动并避免物体与场景之间的碰撞。综合实验表明,与现有方法相比,我们的方法在生成物理上合理、符合文本描述的交互方面具有优越性。
🔬 方法详解
问题定义:现有的人机交互数据集主要关注静态物体,忽略了与可移动物体的交互,导致交互类型单一,无法模拟真实场景中复杂的交互行为。同时,收集包含可移动物体交互的数据集成本高昂,阻碍了相关研究的进展。因此,本文旨在解决在3D场景中,根据文本描述生成与可移动物体进行交互的问题。
核心思路:本文的核心思路是将人机交互生成任务分解为三个关键步骤:首先,通过3D视觉定位准确识别需要交互的物体;其次,通过手-物联合可供性学习预测手部与物体之间的接触区域,实现精确抓取和操作;最后,通过局部场景建模和碰撞避免约束,保证交互过程的物理合理性,避免物体与场景发生碰撞。
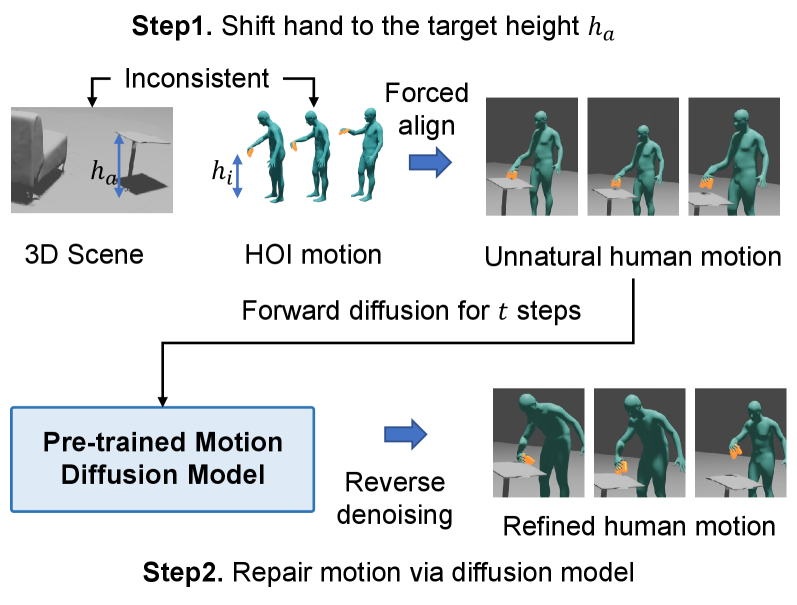
技术框架:该方法采用一个三阶段的流水线框架: 1. 3D视觉定位:利用3D视觉定位模型,根据文本描述,在场景中准确识别出需要交互的物体。 2. 手-物联合可供性学习:学习手部关节和物体部位之间的接触关系,预测最佳的抓取位置和姿态,实现对不同尺寸和类别的物体的精确操作。 3. 交互优化:通过局部场景建模和碰撞避免约束,优化交互轨迹,确保交互过程的物理合理性,避免物体与场景发生碰撞。
关键创新:该方法的主要创新在于: 1. InteractMove数据集:构建了一个包含可移动物体交互的3D场景数据集,弥补了现有数据集的不足。 2. 手-物联合可供性学习:提出了一种新的手-物联合可供性学习方法,能够更准确地预测手部与物体之间的接触区域,实现对不同物体的精确操作。 3. 局部场景建模和碰撞避免:通过局部场景建模和碰撞避免约束,保证了交互过程的物理合理性。
关键设计: 1. 3D视觉定位模型:具体采用的模型结构未知,但其作用是根据文本描述定位交互物体。 2. 手-物联合可供性学习:具体实现方式未知,但其目标是预测手部关节和物体部位的接触区域。 3. 局部场景建模:具体建模方法未知,但其目的是为了进行碰撞检测和避免。 4. 损失函数:可能包含用于优化可供性预测的损失函数,以及用于约束碰撞避免的损失函数。
🖼️ 关键图片
📊 实验亮点
实验结果表明,该方法在生成物理上合理、符合文本描述的交互方面优于现有方法。具体性能数据未知,但摘要强调了该方法在交互的物理合理性和文本一致性方面的优势。该方法能够更好地处理可移动物体,并避免物体与场景发生碰撞,从而生成更逼真的交互。
🎯 应用场景
该研究成果可应用于虚拟现实、增强现实、机器人操作等领域。例如,在VR/AR游戏中,可以根据玩家的指令,生成与虚拟环境中可移动物体的自然交互。在机器人操作中,可以使机器人能够根据指令,安全、高效地操作各种物体,完成复杂的任务。该研究有助于提升人机交互的自然性和智能化水平。
📄 摘要(原文)
We propose a novel task of text-controlled human object interaction generation in 3D scenes with movable objects. Existing human-scene interaction datasets suffer from insufficient interaction categories and typically only consider interactions with static objects (do not change object positions), and the collection of such datasets with movable objects is difficult and costly. To address this problem, we construct the InteractMove dataset for Movable Human-Object Interaction in 3D Scenes by aligning existing human object interaction data with scene contexts, featuring three key characteristics: 1) scenes containing multiple movable objects with text-controlled interaction specifications (including same-category distractors requiring spatial and 3D scene context understanding), 2) diverse object types and sizes with varied interaction patterns (one-hand, two-hand, etc.), and 3) physically plausible object manipulation trajectories. With the introduction of various movable objects, this task becomes more challenging, as the model needs to identify objects to be interacted with accurately, learn to interact with objects of different sizes and categories, and avoid collisions between movable objects and the scene. To tackle such challenges, we propose a novel pipeline solution. We first use 3D visual grounding models to identify the interaction object. Then, we propose a hand-object joint affordance learning to predict contact regions for different hand joints and object parts, enabling accurate grasping and manipulation of diverse objects. Finally, we optimize interactions with local-scene modeling and collision avoidance constraints, ensuring physically plausible motions and avoiding collisions between objects and the scene. Comprehensive experiments demonstrate our method's superiority in generating physically plausible, text-compliant interactions compared to existing approaches.