StolenLoRA: Exploring LoRA Extraction Attacks via Synthetic Data
作者: Yixu Wang, Yan Teng, Yingchun Wang, Xingjun Ma
分类: cs.CR, cs.CV
发布日期: 2025-09-28
备注: ICCV 2025
💡 一句话要点
StolenLoRA:提出基于合成数据的LoRA提取攻击方法
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: LoRA提取攻击 模型提取 合成数据 参数高效微调 半监督学习
📋 核心要点
- 现有模型提取攻击难以有效针对参数高效微调的LoRA模型进行攻击。
- StolenLoRA利用LLM生成合成数据,并结合分歧半监督学习,高效提取LoRA模型功能。
- 实验表明,StolenLoRA在有限查询下实现了高攻击成功率,揭示了LoRA模型的脆弱性。
📝 摘要(中文)
参数高效微调(PEFT)方法如LoRA已经改变了视觉模型的适配方式,实现了定制模型的快速部署。然而,LoRA适配的紧凑性引入了新的安全问题,特别是它们容易受到模型提取攻击。本文提出了一种新的模型提取攻击,名为LoRA提取,它基于公共预训练模型提取LoRA自适应模型。然后,我们提出了一种新的提取方法,称为StolenLoRA,它训练一个替代模型,利用合成数据提取LoRA适配模型的功能。StolenLoRA利用大型语言模型来制作有效的数据生成提示,并结合基于分歧的半监督学习(DSL)策略,以最大限度地从有限的查询中获取信息。我们的实验表明了StolenLoRA的有效性,即使在攻击者和受害者模型使用不同的预训练骨干网络的跨骨干场景中,仅使用1万次查询即可达到高达96.60%的攻击成功率。这些发现揭示了LoRA适配模型对此类提取的特定脆弱性,并强调了迫切需要针对PEFT方法的强大防御机制。我们还探索了一种基于多样化LoRA部署的初步防御策略,突出了其减轻此类攻击的潜力。
🔬 方法详解
问题定义:论文旨在解决LoRA适配模型的提取攻击问题。现有的模型提取方法通常针对完整模型,而LoRA作为一种参数高效微调方法,其参数量小,直接应用现有方法效果不佳。此外,LoRA的特性使得攻击者难以通过少量查询就获得足够的信息来重建模型功能。
核心思路:论文的核心思路是利用合成数据训练一个替代模型,使其能够模仿LoRA适配模型的功能。通过精心设计的提示词,利用大型语言模型生成高质量的合成数据,并结合半监督学习策略,最大限度地利用有限的查询次数,从而高效地提取LoRA模型的功能。
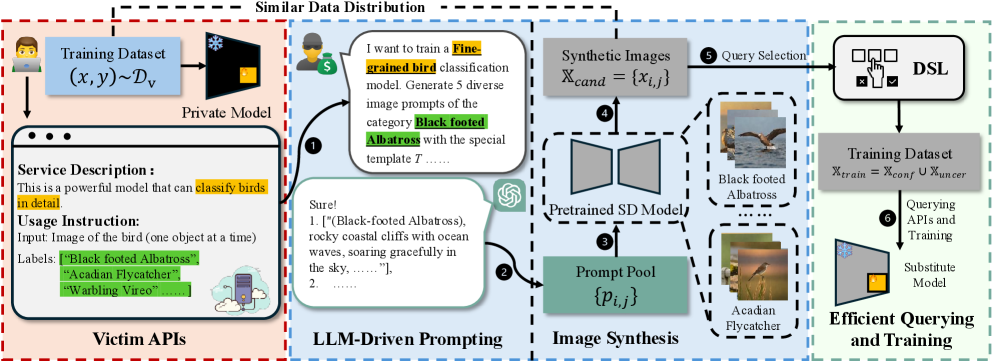
技术框架:StolenLoRA的整体框架包括以下几个主要阶段:1) 提示词生成:利用大型语言模型(LLM)生成用于合成数据的提示词。2) 数据合成:使用生成的提示词,通过查询目标LoRA模型生成合成数据。3) 替代模型训练:使用合成数据训练一个替代模型,使其模仿目标LoRA模型的功能。4) 分歧半监督学习(DSL):利用DSL策略,从未标记的数据中挖掘信息,进一步提升替代模型的性能。
关键创新:StolenLoRA的关键创新在于:1) 针对LoRA适配模型的特性,提出了基于合成数据的提取攻击方法。2) 利用大型语言模型生成高质量的提示词,提高了数据合成的效率和质量。3) 引入分歧半监督学习策略,最大限度地利用有限的查询次数,提升了攻击效率。
关键设计:在提示词生成方面,论文设计了特定的提示词模板,并利用LLM进行填充,以生成多样化的提示词。在分歧半监督学习方面,论文采用了基于模型预测差异的策略,选择差异较大的未标记数据进行标注,并将其用于替代模型的训练。损失函数方面,使用了交叉熵损失函数来衡量替代模型的预测结果与目标LoRA模型的预测结果之间的差异。
🖼️ 关键图片
📊 实验亮点
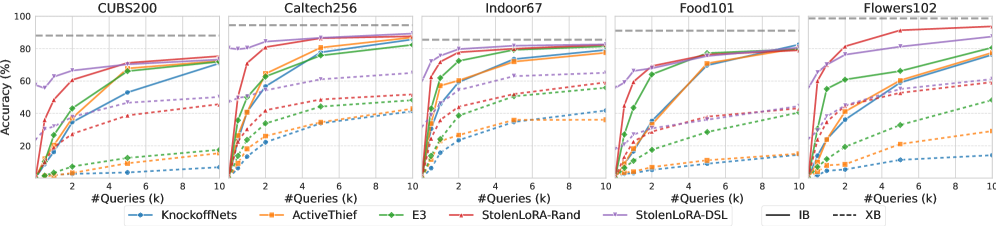
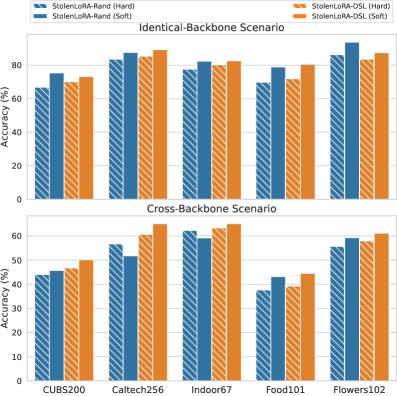
StolenLoRA在实验中表现出强大的攻击能力,即使在跨骨干网络的情况下,仅使用1万次查询即可达到高达96.60%的攻击成功率。相较于其他模型提取方法,StolenLoRA在LoRA提取任务上具有显著优势,证明了其针对LoRA适配模型的有效性。此外,论文还初步探索了基于多样化LoRA部署的防御策略,并验证了其缓解攻击的潜力。
🎯 应用场景
该研究成果可应用于评估和提升参数高效微调模型的安全性,尤其是在模型共享和部署场景下。通过模拟攻击,可以发现LoRA模型的潜在漏洞,并开发相应的防御机制,从而保护模型的知识产权和敏感信息。此外,该研究也为其他PEFT方法的安全性评估提供了借鉴。
📄 摘要(原文)
Parameter-Efficient Fine-Tuning (PEFT) methods like LoRA have transformed vision model adaptation, enabling the rapid deployment of customized models. However, the compactness of LoRA adaptations introduces new safety concerns, particularly their vulnerability to model extraction attacks. This paper introduces a new focus of model extraction attacks named LoRA extraction that extracts LoRA-adaptive models based on a public pre-trained model. We then propose a novel extraction method called StolenLoRA which trains a substitute model to extract the functionality of a LoRA-adapted model using synthetic data. StolenLoRA leverages a Large Language Model to craft effective prompts for data generation, and it incorporates a Disagreement-based Semi-supervised Learning (DSL) strategy to maximize information gain from limited queries. Our experiments demonstrate the effectiveness of StolenLoRA, achieving up to a 96.60% attack success rate with only 10k queries, even in cross-backbone scenarios where the attacker and victim models utilize different pre-trained backbones. These findings reveal the specific vulnerability of LoRA-adapted models to this type of extraction and underscore the urgent need for robust defense mechanisms tailored to PEFT methods. We also explore a preliminary defense strategy based on diversified LoRA deployments, highlighting its potential to mitigate such attacks.