OVSeg3R: Learn Open-vocabulary Instance Segmentation from 2D via 3D Reconstruction
作者: Hongyang Li, Jinyuan Qu, Lei Zhang
分类: cs.CV
发布日期: 2025-09-28 (更新: 2026-01-05)
💡 一句话要点
OVSeg3R:通过3D重建从2D学习开放词汇实例分割
🎯 匹配领域: 支柱三:空间感知与语义 (Perception & Semantics)
关键词: 开放词汇分割 3D实例分割 3D重建 伪标签 跨模态学习 机器人视觉 场景理解
📋 核心要点
- 现有3D实例分割方法依赖于封闭词汇,且标注成本高昂,难以泛化到开放词汇场景。
- OVSeg3R利用2D开放词汇模型和3D重建技术,将2D的知识迁移到3D,自动生成3D实例分割的训练数据。
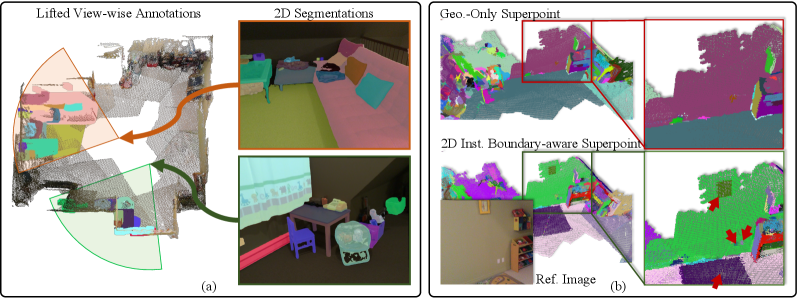
- 通过View-wise Instance Partition和2D Instance Boundary-aware Superpoint,有效解决了2D到3D投影带来的噪声和几何细节丢失问题,提升了分割精度。
📝 摘要(中文)
本文提出了一种名为OVSeg3R的训练方案,借助3D重建,从充分研究的2D感知模型中学习开放词汇3D实例分割。OVSeg3R直接采用从2D视频重建的场景作为输入,避免了昂贵的手动调整,同时使输入与实际应用对齐。通过利用3D重建模型提供的2D到3D的对应关系,OVSeg3R将每个视图的2D实例掩码预测(从开放词汇2D模型获得)投影到3D,从而为该视图对应的子场景生成注释。为了避免由于2D到3D的部分注释而错误地引入假阳性作为监督,我们提出了一种View-wise Instance Partition算法,该算法将预测划分到各自的视图以进行监督,从而稳定训练过程。此外,由于3D重建模型倾向于过度平滑几何细节,因此仅基于几何形状将重建的点聚类成代表性的超点(如主流3D分割方法中常见的做法)可能会忽略几何上不显著的对象。因此,我们引入了2D Instance Boundary-aware Superpoint,它利用2D掩码来约束超点聚类,防止超点违反实例边界。通过这些设计,OVSeg3R不仅将最先进的封闭词汇3D实例分割模型扩展到开放词汇,而且大大缩小了尾部类和头部类之间的性能差距,最终在ScanNet200基准测试上实现了+2.3 mAP的总体改进。此外,在标准开放词汇设置下,OVSeg3R超过了以前的方法约+7.1 mAP的新类别,进一步验证了其有效性。
🔬 方法详解
问题定义:现有的3D实例分割方法通常依赖于封闭词汇表,即模型只能识别预先定义的类别。此外,3D数据的标注成本非常高,限制了模型在开放词汇场景下的应用。因此,如何利用已有的2D开放词汇知识,高效地训练3D开放词汇实例分割模型是一个关键问题。
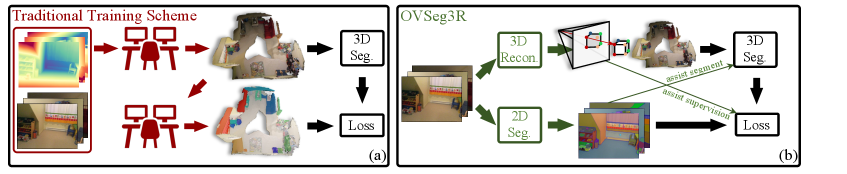
核心思路:OVSeg3R的核心思路是利用3D重建技术,将2D开放词汇实例分割模型的预测结果投影到3D空间,从而自动生成3D实例分割的训练数据。通过这种方式,可以避免手动标注3D数据的昂贵成本,并利用2D模型的泛化能力,实现3D开放词汇实例分割。
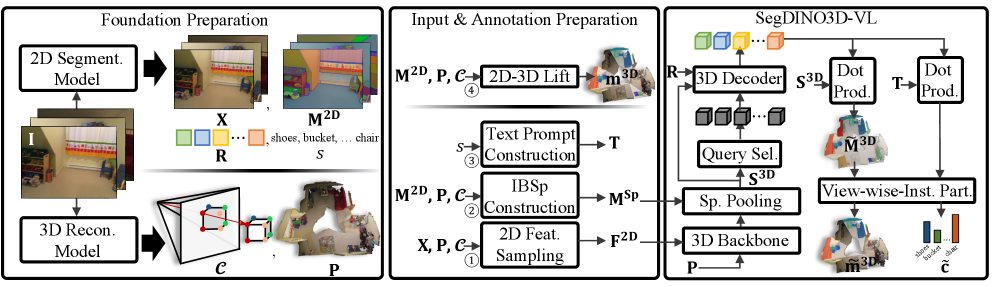
技术框架:OVSeg3R的整体框架包括以下几个主要阶段:1) 使用2D开放词汇实例分割模型对视频帧进行分割,得到2D实例掩码。2) 使用3D重建模型将视频帧重建为3D场景。3) 将2D实例掩码投影到3D空间,为3D场景生成伪标签。4) 使用View-wise Instance Partition算法,将预测划分到各自的视图以进行监督,稳定训练过程。5) 使用2D Instance Boundary-aware Superpoint算法,利用2D掩码来约束超点聚类,防止超点违反实例边界。6) 使用生成的伪标签训练3D实例分割模型。
关键创新:OVSeg3R的关键创新在于:1) 利用2D开放词汇模型和3D重建技术,自动生成3D实例分割的训练数据,避免了昂贵的手动标注。2) 提出了View-wise Instance Partition算法,解决了2D到3D投影带来的噪声问题。3) 提出了2D Instance Boundary-aware Superpoint算法,解决了3D重建模型过度平滑几何细节的问题。
关键设计:View-wise Instance Partition算法将每个3D点云划分到对应的2D视图,只使用该视图的2D预测结果作为监督信号,从而减少了噪声。2D Instance Boundary-aware Superpoint算法在超点聚类时,考虑了2D实例边界的信息,防止超点跨越不同的实例。损失函数包括分割损失和聚类损失,用于优化3D实例分割模型。
🖼️ 关键图片
📊 实验亮点
OVSeg3R在ScanNet200基准测试上取得了显著的性能提升。与之前的封闭词汇3D实例分割模型相比,OVSeg3R在总体mAP上提升了+2.3。在标准开放词汇设置下,OVSeg3R超过了以前的方法约+7.1 mAP的新类别,验证了其在开放词汇场景下的有效性。
🎯 应用场景
OVSeg3R在机器人导航、自动驾驶、场景理解等领域具有广泛的应用前景。它可以使机器人在未知的环境中识别和分割各种物体,从而实现更智能的交互和决策。此外,该方法还可以用于3D场景编辑、虚拟现实等领域,提高用户体验。
📄 摘要(原文)
In this paper, we propose a training scheme called OVSeg3R to learn open-vocabulary 3D instance segmentation from well-studied 2D perception models with the aid of 3D reconstruction. OVSeg3R directly adopts reconstructed scenes from 2D videos as input, avoiding costly manual adjustment while aligning input with real-world applications. By exploiting the 2D to 3D correspondences provided by 3D reconstruction models, OVSeg3R projects each view's 2D instance mask predictions, obtained from an open-vocabulary 2D model, onto 3D to generate annotations for the view's corresponding sub-scene. To avoid incorrectly introduced false positives as supervision due to partial annotations from 2D to 3D, we propose a View-wise Instance Partition algorithm, which partitions predictions to their respective views for supervision, stabilizing the training process. Furthermore, since 3D reconstruction models tend to over-smooth geometric details, clustering reconstructed points into representative super-points based solely on geometry, as commonly done in mainstream 3D segmentation methods, may overlook geometrically non-salient objects. We therefore introduce 2D Instance Boundary-aware Superpoint, which leverages 2D masks to constrain the superpoint clustering, preventing superpoints from violating instance boundaries. With these designs, OVSeg3R not only extends a state-of-the-art closed-vocabulary 3D instance segmentation model to open-vocabulary, but also substantially narrows the performance gap between tail and head classes, ultimately leading to an overall improvement of +2.3 mAP on the ScanNet200 benchmark. Furthermore, under the standard open-vocabulary setting, OVSeg3R surpasses previous methods by about +7.1 mAP on the novel classes, further validating its effectiveness.