Culture In a Frame: C$^3$B as a Comic-Based Benchmark for Multimodal Culturally Awareness
作者: Yuchen Song, Andong Chen, Wenxin Zhu, Kehai Chen, Xuefeng Bai, Muyun Yang, Tiejun Zhao
分类: cs.CV, cs.AI
发布日期: 2025-09-27
💡 一句话要点
提出C$^3$B:一个基于漫画的多模态文化感知能力评测基准
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态学习 文化感知 评测基准 漫画图像 跨语言理解
📋 核心要点
- 现有文化感知评测基准难度不足,缺乏跨语言任务,且真实图像场景单一,限制了模型泛化能力。
- C$^3$B基准利用漫画场景,构建多文化、多任务、多语言数据集,递进式考察模型文化感知能力。
- 实验表明,现有MLLM在C$^3$B上表现与人类存在显著差距,验证了基准的挑战性与研究价值。
📝 摘要(中文)
文化感知能力已成为多模态大型语言模型(MLLM)的关键能力。然而,当前的评测基准在任务设计上缺乏难度递进,并且在跨语言任务方面存在不足。此外,现有基准通常使用真实世界的图像,每张图像通常只包含一种文化,这使得MLLM相对容易应对。基于此,我们提出了C$^3$B(漫画跨文化基准),这是一个新颖的多文化、多任务和多语言的文化感知能力评测基准。C$^3$B包含超过2000张图像和超过18000个问答对,构建于三个难度递进的任务之上,从基本的视觉识别到更高层次的文化冲突理解,最后到文化内容生成。我们对11个开源MLLM进行了评估,揭示了MLLM与人类表现之间存在显著的性能差距。这一差距表明C$^3$B对当前的MLLM提出了重大挑战,鼓励未来的研究推进MLLM的文化感知能力。
🔬 方法详解
问题定义:现有文化感知能力评测基准主要存在三个痛点:一是任务难度不足,无法有效区分模型间的文化理解能力差异;二是缺乏跨语言的评测,限制了模型在不同文化背景下的应用;三是使用真实世界图像,图像内容通常较为单一,不利于考察模型在复杂文化场景下的推理能力。
核心思路:论文的核心思路是构建一个更具挑战性和综合性的文化感知能力评测基准。通过使用漫画作为图像来源,可以创造包含多种文化元素和复杂交互的场景,从而提高评测的难度和区分度。同时,引入多语言的问答对,可以考察模型在不同语言文化背景下的理解能力。
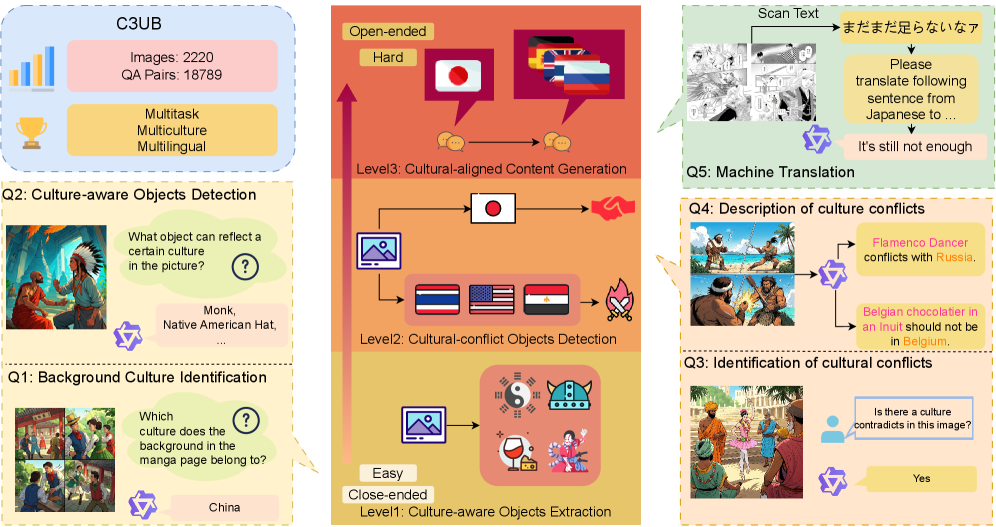
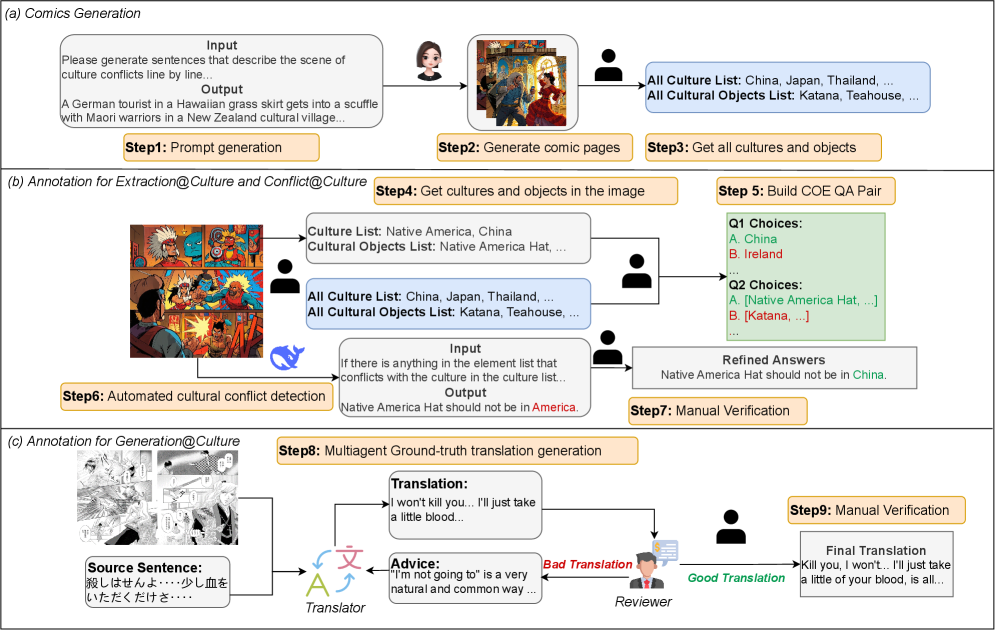
技术框架:C$^3$B基准包含三个主要任务:1) 基本视觉识别:考察模型对图像中文化元素的识别能力;2) 文化冲突理解:考察模型对图像中文化冲突的理解和推理能力;3) 文化内容生成:考察模型根据图像生成符合特定文化背景描述的能力。整个流程包括数据收集与标注、任务设计、模型评估和结果分析等环节。
关键创新:该论文的关键创新在于:1) 提出了使用漫画作为文化感知能力评测的图像来源,相较于真实图像,漫画可以更灵活地展现多文化融合和文化冲突场景;2) 构建了多语言的问答对,从而可以更全面地评估模型在不同文化背景下的理解能力;3) 设计了难度递进的三个任务,从基本的视觉识别到高层次的文化理解和生成,从而可以更细粒度地评估模型的文化感知能力。
关键设计:C$^3$B基准包含超过2000张漫画图像和超过18000个问答对。在数据标注方面,采用了多轮标注和专家审核的方式,以保证标注的准确性和一致性。在模型评估方面,采用了多种评价指标,包括准确率、F1值和BLEU等,以全面评估模型的性能。具体参数设置和网络结构取决于被评估的MLLM模型。
🖼️ 关键图片

📊 实验亮点
实验结果表明,现有11个开源MLLM在C$^3$B基准上的表现与人类水平存在显著差距,验证了该基准的挑战性。例如,在文化冲突理解任务上,模型的平均准确率仅为XX%,远低于人类的YY%。这表明当前MLLM在文化感知方面仍有很大的提升空间,C$^3$B可以作为未来研究的重要评测工具。
🎯 应用场景
该研究成果可应用于提升多模态大语言模型在跨文化交流、智能客服、内容创作等领域的表现。更强的文化感知能力有助于模型更好地理解用户意图,避免文化误解,并生成更符合特定文化背景的内容,从而提升用户体验和应用价值。未来,该基准可以促进相关算法的研发,推动人工智能技术在文化领域的应用。
📄 摘要(原文)
Cultural awareness capabilities has emerged as a critical capability for Multimodal Large Language Models (MLLMs). However, current benchmarks lack progressed difficulty in their task design and are deficient in cross-lingual tasks. Moreover, current benchmarks often use real-world images. Each real-world image typically contains one culture, making these benchmarks relatively easy for MLLMs. Based on this, we propose C$^3$B ($\textbf{C}$omics $\textbf{C}$ross-$\textbf{C}$ultural $\textbf{B}$enchmark), a novel multicultural, multitask and multilingual cultural awareness capabilities benchmark. C$^3$B comprises over 2000 images and over 18000 QA pairs, constructed on three tasks with progressed difficulties, from basic visual recognition to higher-level cultural conflict understanding, and finally to cultural content generation. We conducted evaluations on 11 open-source MLLMs, revealing a significant performance gap between MLLMs and human performance. The gap demonstrates that C$^3$B poses substantial challenges for current MLLMs, encouraging future research to advance the cultural awareness capabilities of MLLMs.