Uncovering Intrinsic Capabilities: A Paradigm for Data Curation in Vision-Language Models
作者: Junjie Li, Ziao Wang, Jianghong Ma, Xiaofeng Zhang
分类: cs.CV, cs.AI
发布日期: 2025-09-27 (更新: 2026-01-14)
💡 一句话要点
提出能力归因数据精选框架CADC,提升视觉-语言模型指令调优效率。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 视觉-语言模型 指令调优 数据精选 内在能力 梯度分析
📋 核心要点
- 现有指令调优方法依赖启发式策略,忽略了视觉-语言模型内在能力,导致数据精简时性能下降。
- CADC框架通过分析梯度学习轨迹,无监督地发现模型内在能力,并将训练数据归因于这些能力。
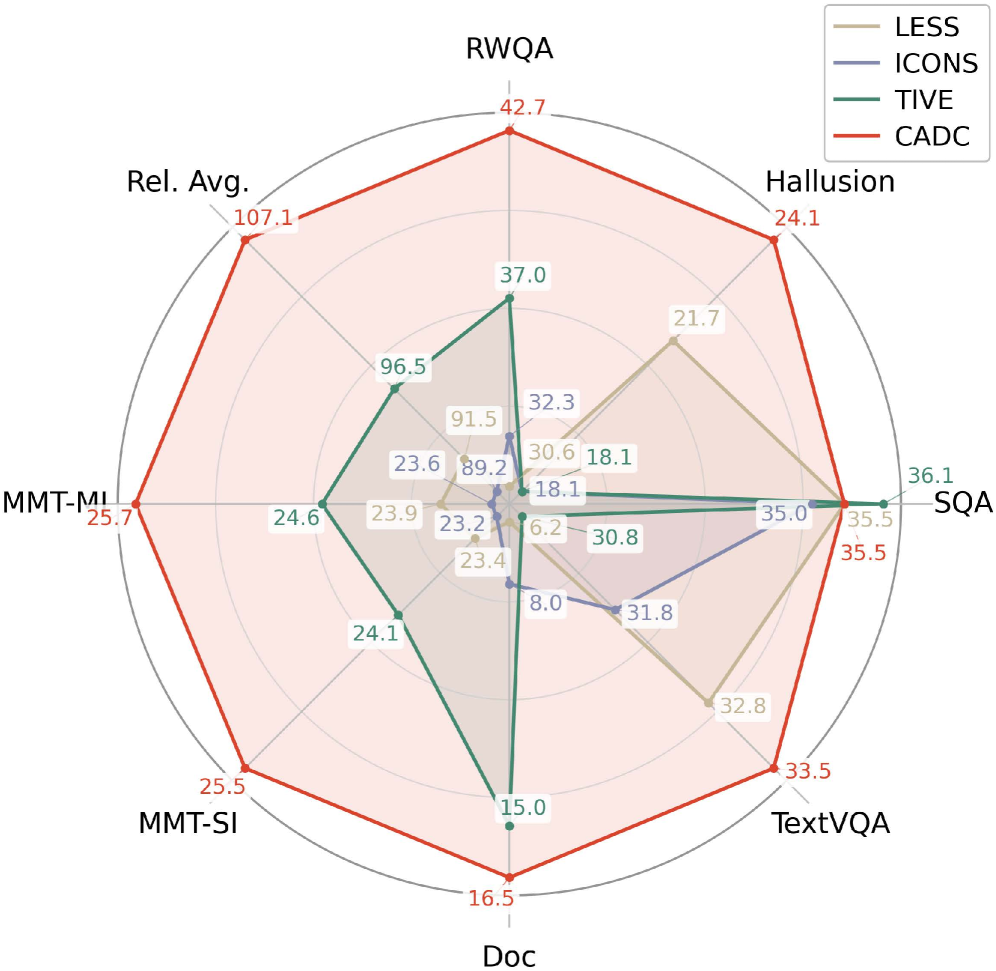
- 实验表明,CADC仅使用5%的数据即可超越全数据训练,验证了内在能力在模型学习中的作用。
📝 摘要(中文)
大型视觉-语言模型(VLMs)在基准测试中表现出色,但通过指令调优控制其行为仍然困难。减少指令调优数据集的规模通常会导致性能下降,因为启发式策略将模型视为黑盒,忽略了潜在的能力。本文提出了一种能力归因数据精选(CADC)框架,该框架将数据精选从特定于任务的启发式方法转变为内在能力分析。CADC以无监督的方式从基于梯度的学习轨迹中发现内在能力,通过影响估计将训练数据归因于这些能力,并通过平衡选择和分阶段排序来精选能力感知的课程。这会将黑盒指令调优转变为可控的、能力驱动的过程。仅使用原始数据的5%,CADC在多模态基准测试中就超过了全数据训练的性能。这些结果验证了内在能力作为模型学习的基本构建块,并将CADC确立为指令数据精选的主要范例。
🔬 方法详解
问题定义:现有视觉-语言模型指令调优方法通常将模型视为黑盒,采用启发式数据选择策略。这种方法忽略了模型内在的学习能力,导致在减少训练数据量时性能显著下降。因此,如何有效地利用少量数据进行指令调优,同时保持甚至提升模型性能,是一个关键问题。
核心思路:本文的核心思路是揭示并利用视觉-语言模型内在的学习能力。通过分析模型在训练过程中的梯度变化,可以发现模型正在学习哪些内在能力。然后,将训练数据与这些内在能力关联起来,选择那些对模型学习特定能力贡献最大的数据,从而构建一个高效的训练数据集。
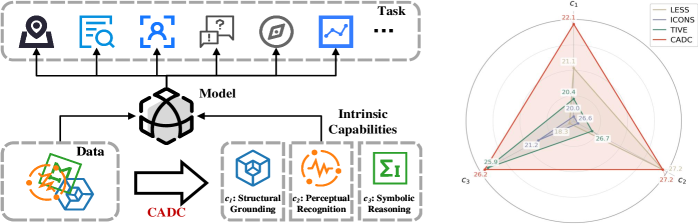
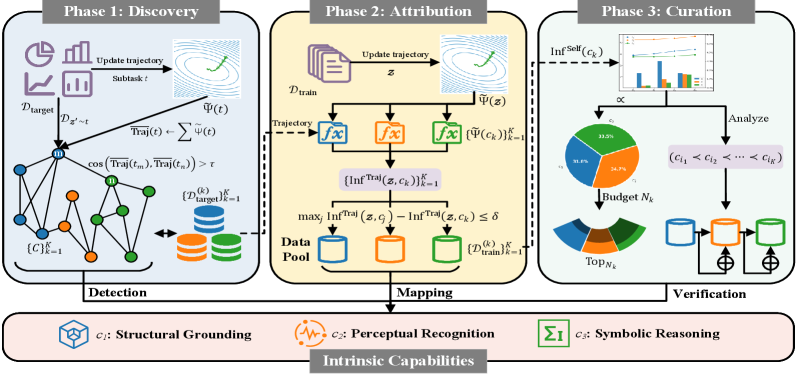
技术框架:CADC框架包含三个主要阶段:1) 内在能力发现:通过分析模型训练过程中的梯度信息,使用无监督学习方法(具体方法未知)发现模型正在学习的内在能力。2) 数据能力归因:使用影响函数估计(influence estimation)将训练数据与发现的内在能力关联起来,确定每个数据样本对学习特定能力的贡献程度。3) 能力感知数据精选:基于数据与能力的关联性,采用平衡选择和分阶段排序策略,构建一个能力感知的训练课程,从而高效地训练模型。
关键创新:CADC的关键创新在于将数据精选从任务特定的启发式方法转变为内在能力分析。与以往将模型视为黑盒的方法不同,CADC深入挖掘模型内部的学习机制,通过理解模型正在学习什么,来指导数据选择,从而实现更高效的指令调优。
关键设计:论文中提到使用梯度信息进行内在能力发现,并使用影响函数估计进行数据能力归因,但具体的梯度分析方法、无监督学习算法、影响函数估计的具体公式以及平衡选择和分阶段排序的具体策略等技术细节未知。这些细节将直接影响CADC的性能。
🖼️ 关键图片
📊 实验亮点
CADC框架在多模态基准测试中表现出色,仅使用原始数据的5%就超越了全数据训练的性能。这一结果表明,通过能力归因进行数据精选能够显著提高指令调优的效率,并验证了内在能力是模型学习的关键。
🎯 应用场景
CADC框架可应用于各种视觉-语言模型的指令调优,尤其是在数据资源有限的情况下。该方法能够有效降低训练成本,提高模型性能,并为理解和控制视觉-语言模型的行为提供新的视角。未来,CADC可以扩展到其他多模态模型和任务中,促进人工智能的可解释性和可控性。
📄 摘要(原文)
Large vision-language models (VLMs) achieve strong benchmark performance, but controlling their behavior through instruction tuning remains difficult. Reducing the budget of instruction tuning dataset often causes regressions, as heuristic strategies treat models as black boxes and overlook the latent capabilities that govern learning. We introduce Capability-Attributed Data Curation (CADC), a framework that shifts curation from task-specific heuristics to intrinsic capability analysis. CADC discovers intrinsic capabilities in an unsupervised manner from gradient-based learning trajectories, attributes training data to these capabilities via influence estimation, and curates capability-aware curricula through balanced selection and staged sequencing. This transforms black-box instruction tuning into a controllable, capability-driven process. With as little as 5% of the original data, CADC surpasses full-data training on multimodal benchmarks. These results validate intrinsic capabilities as the fundamental building blocks of model learning and establish CADC as a principle paradigm for instruction data curation.