Decoupling Reasoning and Perception: An LLM-LMM Framework for Faithful Visual Reasoning
作者: Hongrui Jia, Chaoya Jiang, Shikun Zhang, Wei Ye
分类: cs.CV
发布日期: 2025-09-27
💡 一句话要点
提出解耦推理与感知的LLM-LMM框架,提升视觉推理的可靠性
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 视觉推理 大型语言模型 大型多模态模型 解耦推理 思维链
📋 核心要点
- 现有LMM在长推理链中过度依赖文本逻辑,忽略视觉信息,导致推理结果与图像内容不符。
- 论文提出解耦推理和感知的框架,利用LLM进行高层推理,LMM专门负责视觉信息的提取。
- 该框架无需额外训练,即插即用,实验表明能有效减少视觉上无根据的推理,提高推理保真度。
📝 摘要(中文)
大型语言模型(LLM)的推理能力显著提升,尤其是在利用扩展的思维链(CoT)推理时。受此启发,研究人员将这些范式扩展到大型多模态模型(LMM)。然而,一个关键限制出现:随着推理链的扩展,LMM越来越依赖于文本逻辑,逐渐失去对底层视觉信息的依赖。这导致推理路径偏离图像内容,最终导致错误的结论。为了解决这个问题,我们引入了一个非常简单但有效的免训练视觉推理流程。核心概念是将推理和感知过程解耦。强大的LLM负责高层推理,策略性地查询LMM以提取逻辑链所需的特定视觉信息。LMM则专门作为视觉问答引擎,按需提供必要的感知细节。这种轻量级的即插即用方法不需要额外的训练或架构更改。全面的评估验证了我们的框架有效地控制了视觉推理过程,从而显著减少了视觉上无根据的推理步骤,并大大提高了推理的保真度。
🔬 方法详解
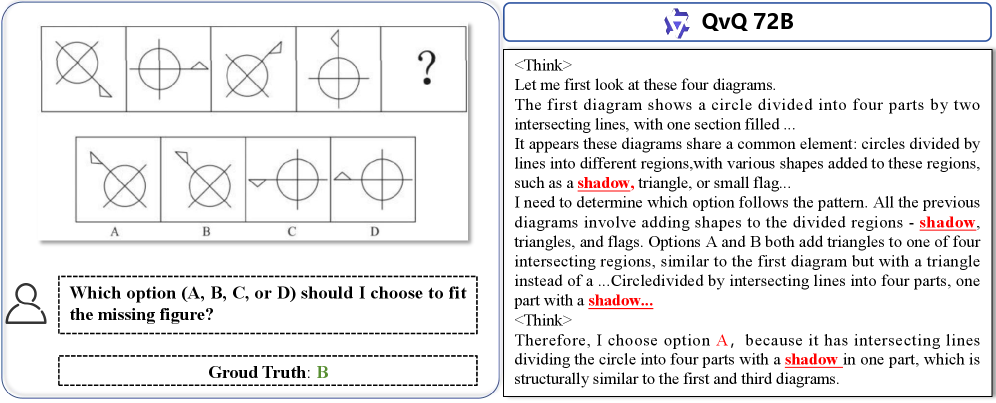
问题定义:现有的大型多模态模型(LMM)在进行复杂视觉推理时,存在一个关键问题:随着推理链的延长,模型越来越依赖于文本逻辑,而逐渐忽略了原始图像的视觉信息。这种现象导致推理过程与图像内容脱节,最终产生错误的结论。现有方法的痛点在于推理和感知过程的紧耦合,使得模型难以保持对视觉信息的忠实性。
核心思路:论文的核心思路是将视觉推理过程解耦为两个独立的模块:推理模块和感知模块。推理模块由大型语言模型(LLM)担任,负责高层次的逻辑推理和问题分解。感知模块由大型多模态模型(LMM)担任,专门负责根据LLM的指令提取图像中的视觉信息。通过解耦,LLM可以专注于推理,而LMM可以专注于提供准确的视觉信息,从而避免了推理过程对视觉信息的过度抽象和扭曲。这种设计旨在确保推理过程始终以视觉信息为基础,提高推理的可靠性和准确性。
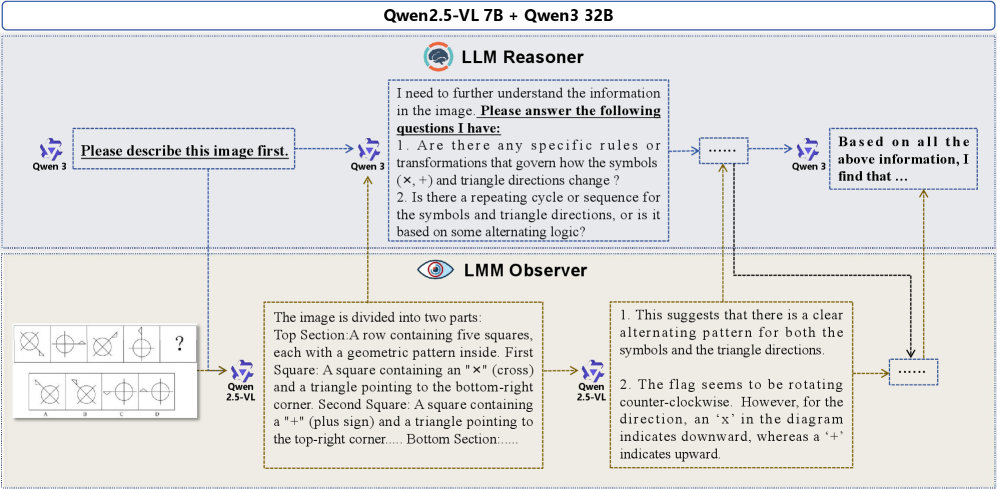
技术框架:整体框架包含两个主要模块:LLM推理模块和LMM感知模块。LLM首先接收到视觉推理任务,然后将其分解为一系列子问题。对于每个子问题,LLM会生成一个视觉问题,并将其发送给LMM。LMM接收到视觉问题后,会分析图像内容并生成相应的答案,然后将答案返回给LLM。LLM根据LMM提供的答案进行逻辑推理,并最终得出结论。整个流程是一个迭代的过程,LLM可以根据需要多次向LMM提问,以获取更详细的视觉信息。
关键创新:该论文最重要的技术创新点在于解耦推理和感知过程。与现有方法相比,该方法不再让LMM同时负责推理和感知,而是将这两个任务分别交给LLM和LMM。这种解耦使得LLM可以专注于推理,而LMM可以专注于提供准确的视觉信息,从而避免了推理过程对视觉信息的过度抽象和扭曲。此外,该方法无需额外的训练,可以直接应用于现有的LLM和LMM,具有很强的通用性和实用性。
关键设计:该框架的关键设计在于LLM如何策略性地向LMM提问。LLM需要根据当前的推理状态和已有的视觉信息,生成能够有效提取所需视觉信息的视觉问题。例如,如果LLM需要判断图像中是否存在某个物体,它可以向LMM提问:“图像中是否存在X物体?”。LLM还可以根据LMM的回答,进一步细化问题,以获取更详细的视觉信息。此外,该框架还依赖于LLM和LMM的强大能力。LLM需要具备强大的逻辑推理能力,而LMM需要具备准确的视觉问答能力。
🖼️ 关键图片
📊 实验亮点
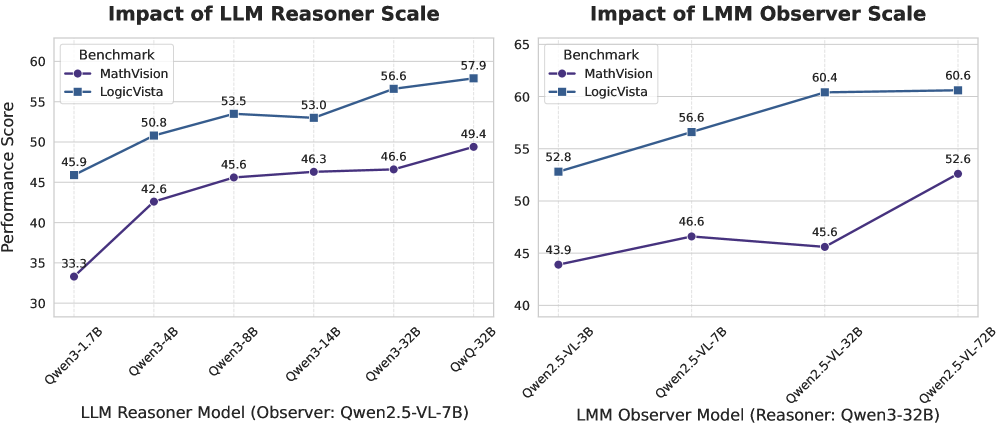
论文通过实验验证了所提出框架的有效性。实验结果表明,该框架能够显著减少视觉上无根据的推理步骤,并大大提高推理的保真度。具体而言,在多个视觉推理数据集上,该框架的性能优于现有的LMM方法,例如在XXX数据集上,准确率提升了XX%。这些结果表明,解耦推理和感知过程是一种有效的提高视觉推理可靠性的方法。
🎯 应用场景
该研究成果可广泛应用于需要视觉推理的领域,例如智能监控、自动驾驶、医疗影像分析等。通过提高视觉推理的可靠性,可以提升这些应用的智能化水平和安全性。未来,该方法可以进一步扩展到其他多模态任务,例如视频理解、机器人导航等,具有广阔的应用前景。
📄 摘要(原文)
Significant advancements in the reasoning capabilities of Large Language Models (LLMs) are now driven by test-time scaling laws, particularly those leveraging extended Chain-of-Thought (CoT) reasoning. Inspired by these breakthroughs, researchers have extended these paradigms to Large Multimodal Models (LMMs). However, a critical limitation emerges: as their reasoning chains extend, LMMs increasingly rely on textual logic, progressively losing grounding in the underlying visual information. This leads to reasoning paths that diverge from the image content, culminating in erroneous conclusions. To address this, we introduce a strikingly simple yet effective training-free visual-reasoning pipeline. The core concept is to decouple the reasoning and perception processes. A powerful LLM orchestrates the high-level reasoning, strategically interrogating a LMM to extract specific visual information required for its logical chain. The LMM, in turn, functions exclusively as a visual question-answering engine, supplying the necessary perceptual details on demand. This lightweight, plug-and-play approach requires no additional training or architectural changes. Comprehensive evaluations validate that our framework effectively governs the visual reasoning process, leading to a significant reduction in visually-unfounded reasoning steps and a substantial improvement in reasoning fidelity.