Vid-Freeze: Protecting Images from Malicious Image-to-Video Generation via Temporal Freezing
作者: Rohit Chowdhury, Aniruddha Bala, Rohan Jaiswal, Siddharth Roheda
分类: cs.CV, cs.AI
发布日期: 2025-09-27
备注: Under Review at ICASSP 26 4 pages, 4 figures, 3 tables
💡 一句话要点
Vid-Freeze:通过时序冻结保护图像免受恶意图像到视频生成攻击
🎯 匹配领域: 支柱四:生成式动作 (Generative Motion) 支柱七:动作重定向 (Motion Retargeting) 支柱八:物理动画 (Physics-based Animation)
关键词: 图像到视频生成 对抗攻击 注意力机制 视频安全 恶意内容防御
📋 核心要点
- 现有图像到视频生成模型易被滥用,缺乏有效阻止恶意运动合成的防御机制。
- Vid-Freeze通过精心设计的对抗扰动,抑制I2V模型的注意力机制,从而冻结视频生成。
- 实验表明,Vid-Freeze能有效阻止恶意视频生成,为防御I2V模型滥用提供新思路。
📝 摘要(中文)
图像到视频(I2V)生成模型的快速发展带来了显著风险,它能够从静态图像合成视频,从而助长欺骗性或恶意内容的创建。虽然像I2VGuard这样的防御方法试图免疫图像,但有效且有原则地阻止运动的保护措施仍未得到充分探索。本文提出了Vid-Freeze,一种新颖的注意力抑制对抗攻击,它向图像添加精心制作的对抗扰动。我们的方法明确地针对I2V模型的注意力机制,完全破坏运动合成,同时保持输入图像的语义保真度。由此产生的免疫图像生成静止或近乎静态的视频,有效地阻止了恶意内容的创建。实验结果表明,该方法提供了令人印象深刻的保护,突出了注意力攻击作为一种有希望的方向,可以针对I2V生成模型的滥用提供强大而主动的防御。
🔬 方法详解
问题定义:论文旨在解决图像到视频(I2V)生成模型被恶意利用的问题。现有的防御方法,如I2VGuard,虽然尝试免疫图像,但未能有效阻止运动合成,使得攻击者仍然可以利用静态图像生成欺骗性或恶意视频。因此,如何设计一种有效且有原则的防御机制,阻止I2V模型生成动态视频,是本文要解决的核心问题。
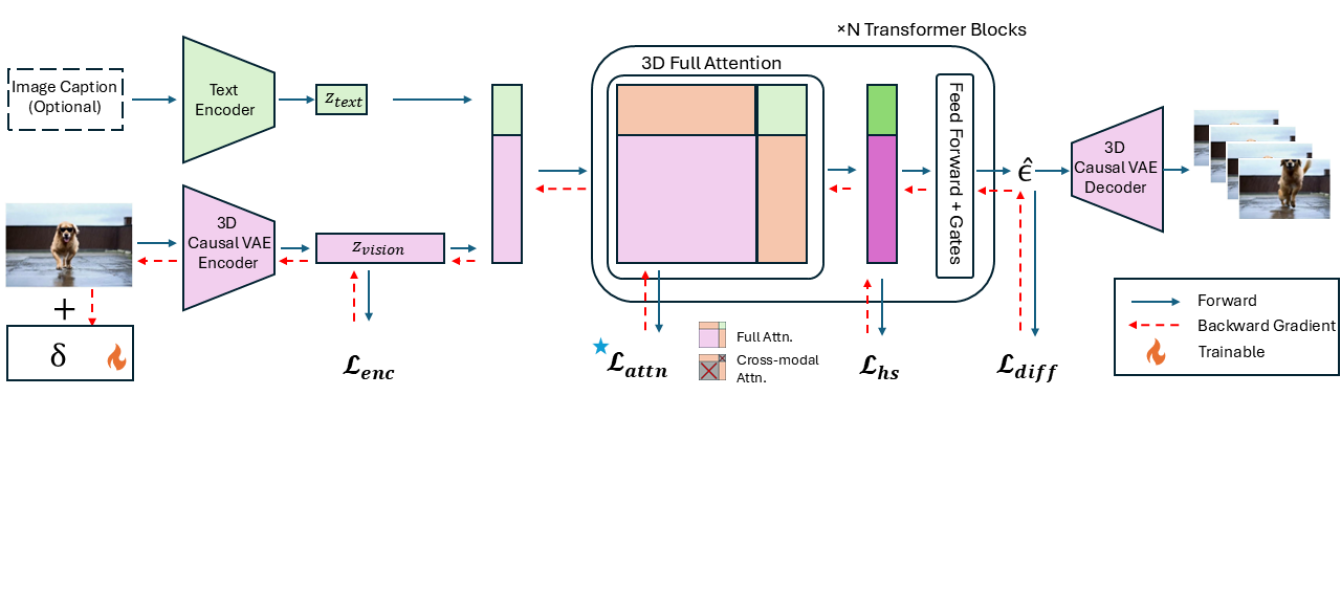
核心思路:Vid-Freeze的核心思路是通过对抗攻击,干扰I2V模型的注意力机制,从而阻止其生成动态视频。具体来说,该方法通过向输入图像添加精心设计的对抗扰动,使得I2V模型无法正确捕捉图像中的运动信息,从而生成静止或近乎静态的视频。这种方法直接针对I2V模型的内部机制,能够更有效地阻止恶意视频的生成。
技术框架:Vid-Freeze的技术框架主要包括以下几个步骤:1) 选择一个I2V生成模型作为攻击目标;2) 设计一个对抗扰动生成器,该生成器能够生成针对目标I2V模型的对抗扰动;3) 将生成的对抗扰动添加到输入图像中,得到免疫图像;4) 将免疫图像输入到目标I2V模型中,观察生成的视频是否为静止或近乎静态的。整个流程旨在通过对抗扰动干扰I2V模型的注意力机制,从而阻止其生成动态视频。
关键创新:Vid-Freeze最重要的技术创新点在于其针对I2V模型的注意力机制进行对抗攻击。与以往的防御方法不同,Vid-Freeze不是简单地对输入图像进行处理,而是深入分析了I2V模型的内部机制,并针对其注意力机制设计了对抗扰动。这种方法能够更有效地干扰I2V模型的运动合成过程,从而阻止恶意视频的生成。
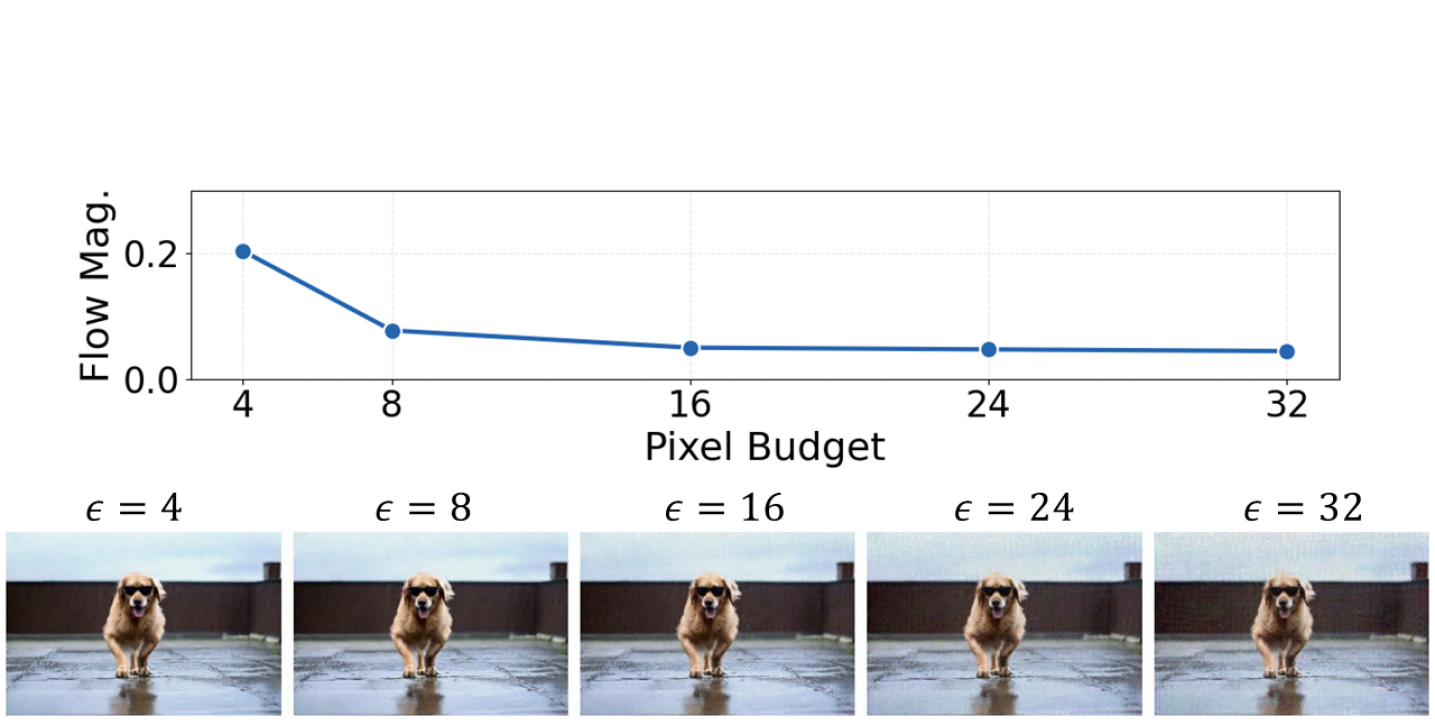
关键设计:Vid-Freeze的关键设计包括:1) 对抗扰动生成器的设计,该生成器需要能够生成针对目标I2V模型的有效对抗扰动;2) 损失函数的设计,该损失函数需要能够衡量生成的视频的动态程度,并引导对抗扰动生成器生成能够使视频尽可能静止的扰动;3) 对抗扰动的强度控制,需要找到一个合适的扰动强度,既能够有效地阻止视频生成,又不会过度影响图像的语义保真度。具体的网络结构和参数设置在论文中有详细描述,此处不再赘述。
🖼️ 关键图片

📊 实验亮点
实验结果表明,Vid-Freeze能够有效地阻止I2V模型生成动态视频,生成的视频几乎完全静止。与现有的防御方法相比,Vid-Freeze在阻止运动合成方面表现出更强的能力,同时保持了图像的语义保真度。具体的性能数据和对比基线在论文中有详细描述,证明了Vid-Freeze的有效性和优越性。
🎯 应用场景
Vid-Freeze技术可应用于保护个人隐私、防止虚假信息传播等领域。例如,可以用于保护个人照片不被恶意用于生成虚假视频,从而避免名誉损害。此外,该技术还可以用于检测和防御恶意视频生成攻击,维护网络安全和社会稳定。未来,该技术有望与水印技术、区块链技术等结合,构建更完善的图像和视频安全保护体系。
📄 摘要(原文)
The rapid progress of image-to-video (I2V) generation models has introduced significant risks, enabling video synthesis from static images and facilitating deceptive or malicious content creation. While prior defenses such as I2VGuard attempt to immunize images, effective and principled protection to block motion remains underexplored. In this work, we introduce Vid-Freeze - a novel attention-suppressing adversarial attack that adds carefully crafted adversarial perturbations to images. Our method explicitly targets the attention mechanism of I2V models, completely disrupting motion synthesis while preserving semantic fidelity of the input image. The resulting immunized images generate stand-still or near-static videos, effectively blocking malicious content creation. Our experiments demonstrate the impressive protection provided by the proposed approach, highlighting the importance of attention attacks as a promising direction for robust and proactive defenses against misuse of I2V generation models.