SynDoc: A Hybrid Discriminative-Generative Framework for Enhancing Synthetic Domain-Adaptive Document Key Information Extraction
作者: Yihao Ding, Soyeon Caren Han, Yanbei Jiang, Yan Li, Zechuan Li, Yifan Peng
分类: cs.CV
发布日期: 2025-09-27
备注: Work in progress
💡 一句话要点
SynDoc:一种混合判别-生成框架,用于增强合成领域自适应文档关键信息提取。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 文档理解 关键信息提取 领域自适应 合成数据 判别模型 生成模型 递归推理 多模态学习
📋 核心要点
- 现有大型语言模型在领域特定文档理解中存在幻觉、领域适应性差和依赖大量标注数据的问题。
- SynDoc框架结合判别模型和生成模型,利用合成数据和递归推理,提升领域文档关键信息提取的准确性。
- SynDoc通过自适应指令调优和递归推理,实现了高效的领域自适应,并提升了文档理解的稳定性和准确性。
📝 摘要(中文)
领域特定的富视觉文档理解(VRDU)由于医学、金融和材料科学等领域文档的复杂性和敏感性而面临重大挑战。现有的大型(多模态)语言模型(LLM/MLLM)取得了可喜的成果,但面临幻觉、领域适应不足以及依赖大量微调数据集等限制。本文介绍了一种新颖的框架SynDoc,它结合了判别模型和生成模型来应对这些挑战。SynDoc采用强大的合成数据生成工作流程,利用结构信息提取和领域特定的查询生成来产生高质量的标注。通过自适应指令调优,SynDoc提高了判别模型提取领域特定知识的能力。同时,递归推理机制迭代地细化两个模型的输出,以实现稳定和准确的预测。该框架展示了可扩展、高效和精确的文档理解,并弥合了领域特定适应和通用世界知识之间的差距,用于文档关键信息提取任务。
🔬 方法详解
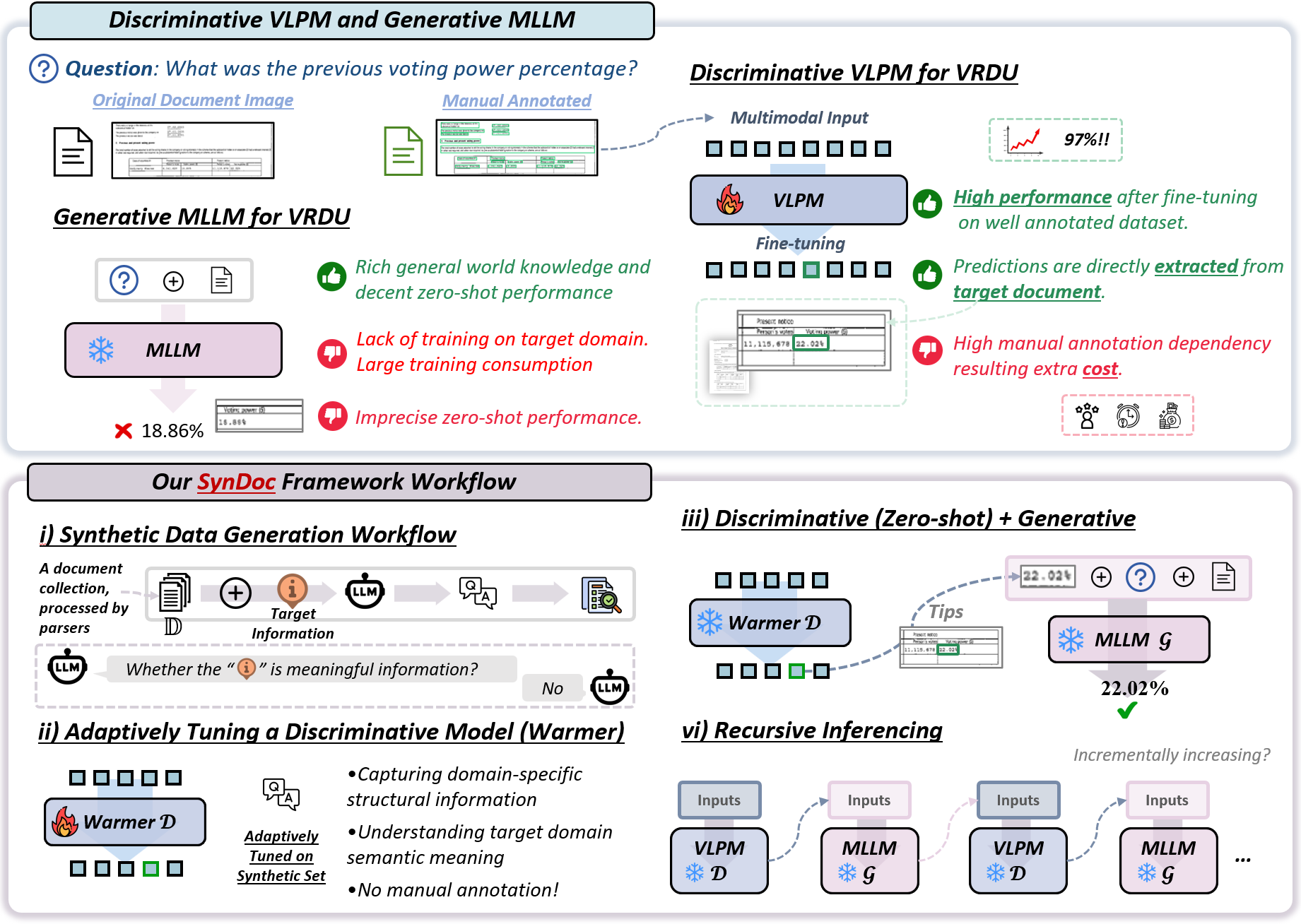
问题定义:论文旨在解决领域特定富视觉文档理解(VRDU)中,现有大型语言模型(LLM/MLLM)存在的幻觉问题、领域适应性不足以及对大量标注数据依赖的问题。现有方法在处理医学、金融等复杂文档时,难以保证提取信息的准确性和可靠性。
核心思路:SynDoc的核心思路是结合判别模型和生成模型,利用合成数据生成高质量的训练样本,并通过自适应指令调优和递归推理机制,迭代地提升模型在特定领域的文档理解能力。通过这种混合方法,可以有效减少对真实标注数据的依赖,并提高模型在复杂文档上的泛化能力。
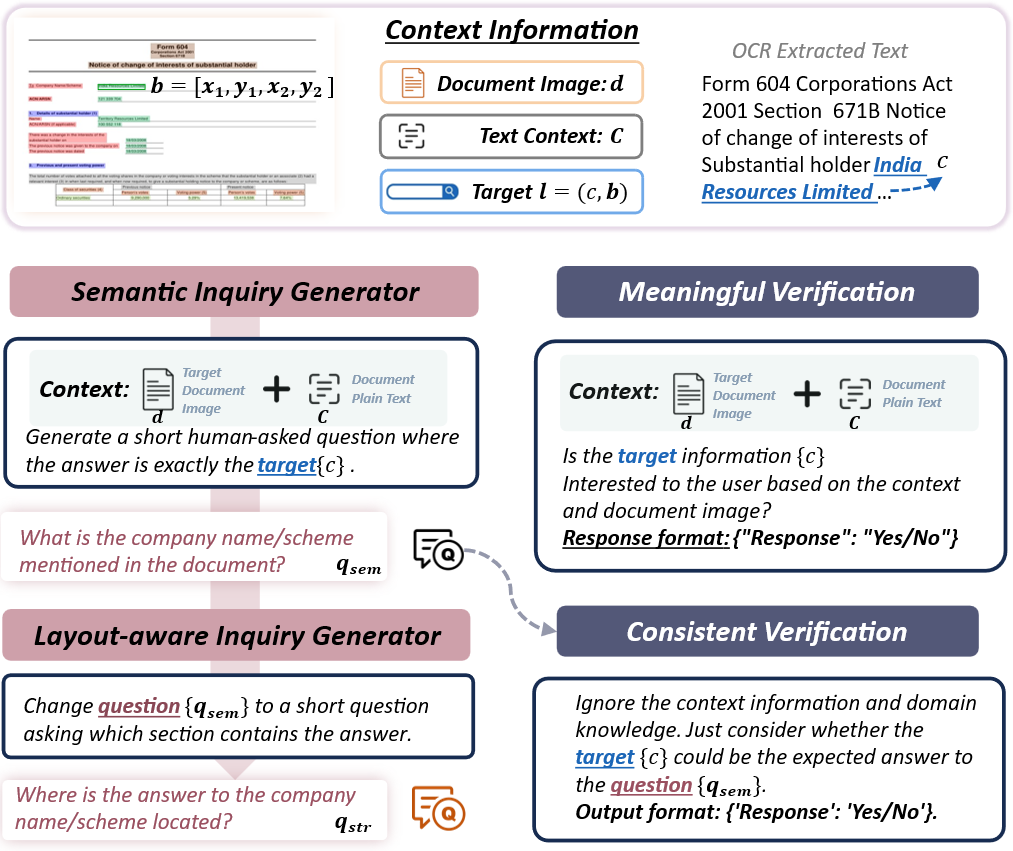
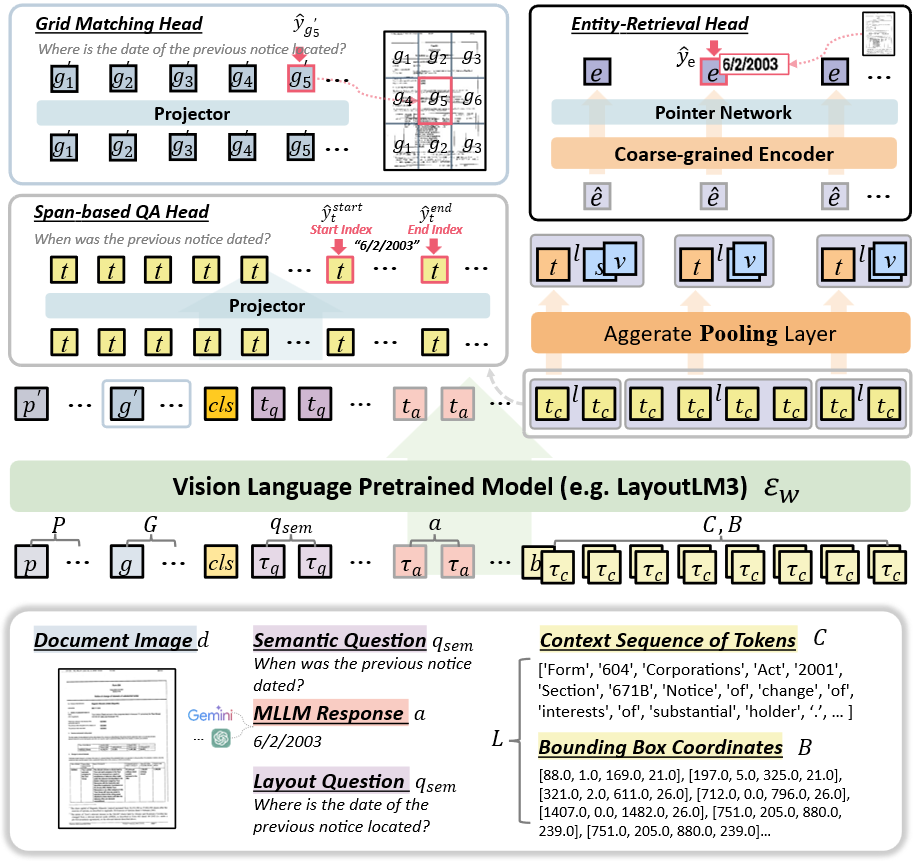
技术框架:SynDoc框架主要包含以下几个模块:1) 合成数据生成模块,利用结构信息提取和领域特定查询生成技术,生成高质量的合成数据;2) 判别模型,用于从文档中提取关键信息,并通过自适应指令调优进行领域适应;3) 生成模型,用于生成与文档相关的查询和答案,并与判别模型进行交互;4) 递归推理机制,迭代地细化判别模型和生成模型的输出,以提高预测的准确性和稳定性。
关键创新:SynDoc的关键创新在于其混合判别-生成框架,以及递归推理机制。传统的文档理解方法通常依赖于单一的判别模型或生成模型,而SynDoc将两者结合,充分利用了各自的优势。递归推理机制则通过迭代优化,进一步提升了模型的性能。此外,高质量的合成数据生成也是一个重要的创新点,它减少了对真实标注数据的需求。
关键设计:在合成数据生成方面,论文采用了结构信息提取技术,以保证生成数据的结构合理性。在自适应指令调优方面,论文设计了特定的指令模板,以引导判别模型学习领域特定知识。递归推理机制的具体实现细节(例如迭代次数、置信度阈值等)未知,但其核心思想是通过迭代优化,逐步提高模型的预测精度。
🖼️ 关键图片
📊 实验亮点
SynDoc框架通过结合判别模型和生成模型,并利用合成数据和递归推理,显著提升了领域特定文档关键信息提取的性能。具体实验数据未知,但论文强调了SynDoc在可扩展性、效率和精度方面的优势,并表明其能够有效弥合领域特定适应和通用世界知识之间的差距。
🎯 应用场景
SynDoc框架可应用于医疗、金融、材料科学等领域,提升领域特定文档的关键信息提取效率和准确性。该研究有助于降低对大量人工标注数据的依赖,加速领域知识的自动化提取和利用,并为智能文档处理提供更可靠的技术支持。未来可扩展到更多复杂文档场景,例如法律合同、技术专利等。
📄 摘要(原文)
Domain-specific Visually Rich Document Understanding (VRDU) presents significant challenges due to the complexity and sensitivity of documents in fields such as medicine, finance, and material science. Existing Large (Multimodal) Language Models (LLMs/MLLMs) achieve promising results but face limitations such as hallucinations, inadequate domain adaptation, and reliance on extensive fine-tuning datasets. This paper introduces SynDoc, a novel framework that combines discriminative and generative models to address these challenges. SynDoc employs a robust synthetic data generation workflow, using structural information extraction and domain-specific query generation to produce high-quality annotations. Through adaptive instruction tuning, SynDoc improves the discriminative model's ability to extract domain-specific knowledge. At the same time, a recursive inferencing mechanism iteratively refines the output of both models for stable and accurate predictions. This framework demonstrates scalable, efficient, and precise document understanding and bridges the gap between domain-specific adaptation and general world knowledge for document key information extraction tasks.