Self-Consistency as a Free Lunch: Reducing Hallucinations in Vision-Language Models via Self-Reflection
作者: Mingfei Han, Haihong Hao, Jinxing Zhou, Zhihui Li, Yuhui Zheng, Xueqing Deng, Linjie Yang, Xiaojun Chang
分类: cs.CV, cs.AI
发布日期: 2025-09-27
💡 一句话要点
提出基于自反思的自洽性方法,减少视觉-语言模型中的幻觉问题
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 视觉-语言模型 幻觉减少 自洽性 自监督学习 事实基础
📋 核心要点
- 现有视觉-语言模型易产生幻觉,缺乏可靠性,且依赖大量人工标注或外部模型监督。
- 论文提出利用模型自身在长回复和短答案间的自洽性,无需人工标注或外部监督,自动生成高质量训练数据。
- 实验表明,该方法在多个基准测试中显著提升了事实基础和可靠性,并保持了强大的指令遵循能力。
📝 摘要(中文)
视觉-语言模型经常产生幻觉,生成不存在的对象或不准确的属性,从而降低输出的可靠性。现有方法通常依赖大量人工标注或来自更强大模型的外部监督来解决这些问题。本文提出了一种新颖的框架,利用模型在长回复和短答案之间的自洽性来生成训练所需的偏好对。我们观察到,简短的二元问题往往产生高度可靠的回复,可用于查询目标模型,以评估和排序其生成的回复。具体来说,我们设计了一个自反思流程,将详细的模型回复与简洁的二元答案进行比较,并利用不一致信号自动生成高质量的训练数据,无需人工标注或基于外部模型的监督。通过仅依赖自洽性而非外部监督,我们的方法提供了一种可扩展且高效的解决方案,可有效减少使用未标记数据的幻觉。在多个基准测试(即AMBER、MultiObject-Hal (ROPE)、Object HalBench和MMHal-Bench)上的大量实验表明,在事实基础和可靠性方面取得了显著改进。此外,我们的方法保持了强大的指令遵循能力,LLaVA-Bench和MMBench上的性能提升证明了这一点。
🔬 方法详解
问题定义:视觉-语言模型在生成描述时容易出现“幻觉”现象,即生成不真实或不准确的内容,例如错误的对象属性或不存在的对象。现有方法通常需要大量的人工标注数据或者依赖更强大的外部模型进行监督,成本高昂且效率较低。
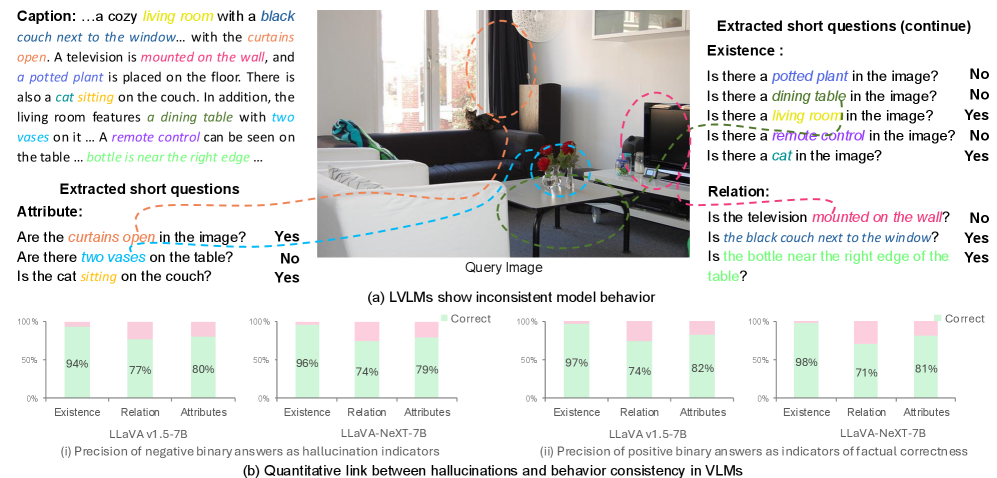
核心思路:论文的核心思路是利用模型自身的自洽性来减少幻觉。具体来说,如果模型对同一场景的长篇描述与对相关二元问题的回答不一致,则表明长篇描述可能存在幻觉。通过识别和纠正这些不一致性,可以提高模型的可靠性。
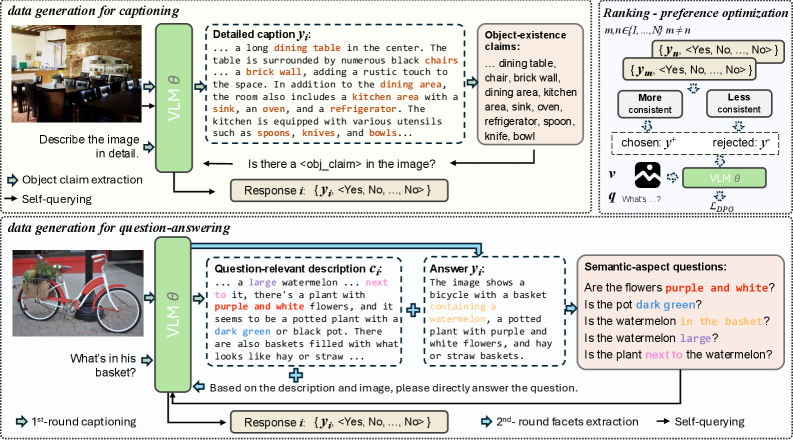
技术框架:该方法包含一个自反思流程。首先,模型生成对图像的长篇描述。然后,针对该图像提出一系列简短的二元问题,并由模型给出答案。接着,将长篇描述与二元答案进行比较,检测是否存在不一致性。如果存在不一致,则将该样本作为负例,用于训练模型减少幻觉。整个过程无需人工标注或外部模型监督。
关键创新:该方法最重要的创新点在于利用模型自身的自洽性作为监督信号,无需人工标注或外部模型。这种自监督的方式更具可扩展性和效率,可以有效利用大量的未标注数据来提升模型的性能。
关键设计:关键设计包括:1) 如何设计有效的二元问题,以充分覆盖图像中的对象和属性;2) 如何定义和检测长篇描述与二元答案之间的不一致性;3) 如何利用检测到的不一致性来训练模型。具体的技术细节(如损失函数、网络结构等)论文中可能未详细说明,需要查阅原文。
🖼️ 关键图片

📊 实验亮点
实验结果表明,该方法在AMBER、MultiObject-Hal (ROPE)、Object HalBench和MMHal-Bench等多个基准测试中显著提升了视觉-语言模型的事实基础和可靠性。同时,该方法在LLaVA-Bench和MMBench上保持了强大的指令遵循能力,表明其在减少幻觉的同时,没有损害模型的其他性能。
🎯 应用场景
该研究成果可广泛应用于需要高可靠性的视觉-语言任务中,例如自动驾驶、医疗诊断、智能客服等。通过减少模型幻觉,可以提高系统的安全性和可信度,并降低出错风险。未来,该方法可以进一步扩展到其他多模态任务,例如视频理解和语音识别。
📄 摘要(原文)
Vision-language models often hallucinate details, generating non-existent objects or inaccurate attributes that compromise output reliability. Existing methods typically address these issues via extensive human annotations or external supervision from more powerful models. In this work, we present a novel framework that leverages the model's self-consistency between long responses and short answers to generate preference pairs for training. We observe that short binary questions tend to yield highly reliable responses, which can be used to query the target model to evaluate and rank its generated responses. Specifically, we design a self-reflection pipeline where detailed model responses are compared against concise binary answers, and inconsistency signals are utilized to automatically curate high-quality training data without human annotations or external model-based supervision. By relying solely on self-consistency rather than external supervision, our method offers a scalable and efficient solution that effectively reduces hallucinations using unlabeled data. Extensive experiments on multiple benchmarks, i.e., AMBER, MultiObject-Hal (ROPE), Object HalBench, and MMHal-Bench, demonstrate significant improvements in factual grounding and reliability. Moreover, our approach maintains robust instruction-following ability, as evidenced by enhanced performance on LLaVA-Bench and MMBench.