GeLoc3r: Enhancing Relative Camera Pose Regression with Geometric Consistency Regularization
作者: Jingxing Li, Yongjae Lee, Deliang Fan
分类: cs.CV, cs.AI
发布日期: 2025-09-27 (更新: 2026-01-20)
💡 一句话要点
GeLoc3r:通过几何一致性正则化增强相对相机位姿回归
🎯 匹配领域: 支柱七:动作重定向 (Motion Retargeting)
关键词: 相对位姿估计 几何一致性 相机重定位 深度学习 RANSAC
📋 核心要点
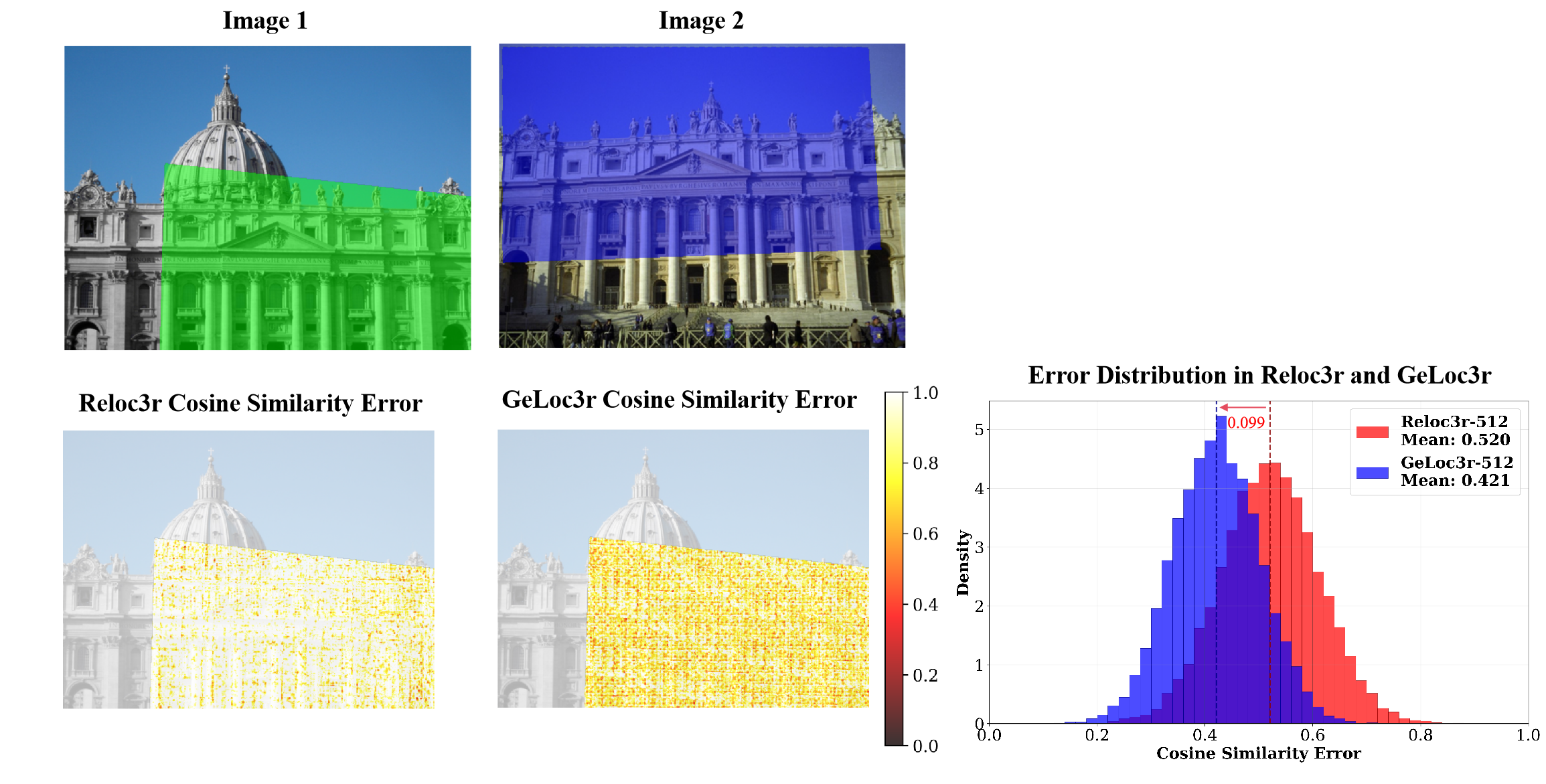
- 现有ReLoc3R方法在相对位姿回归中存在几何不一致性,限制了其精度提升。
- GeLoc3r通过几何一致性正则化,在训练阶段将几何知识融入回归网络,提升位姿估计的准确性。
- 实验表明,GeLoc3r在多个数据集上显著优于ReLoc3R,在CO3Dv2上AUC@5°提升了16%。
📝 摘要(中文)
ReLoc3R虽然实现了快速推理(25ms)和最先进的回归精度,但其内部表示存在细微的几何不一致性,阻碍了其达到基于对应关系的方法(如MASt3R,每个pair需要300ms)的精度上限。本文提出了GeLoc3r,一种通过几何一致性正则化(GCR)增强位姿回归方法的相对相机位姿估计新方法。GeLoc3r通过训练回归网络以产生几何一致的位姿,而无需推理时的几何计算,从而克服了速度-精度困境。在训练期间,GeLoc3r利用ground-truth深度生成密集的3D-2D对应关系,使用FusionTransformer对它们进行加权以学习对应关系的重要性,并通过加权RANSAC计算几何一致的位姿。这创建了一个一致性损失,将几何知识转移到回归网络中。与需要在推理时进行回归和几何求解的FAR方法不同,GeLoc3r仅在测试时使用增强的回归头,保持了ReLoc3R的快速速度并接近MASt3R的高精度。在具有挑战性的基准测试中,GeLoc3r始终优于ReLoc3R,实现了显着改进,包括在CO3Dv2数据集上AUC@5°从34.85%提高到40.45%(相对改进16%),在RealEstate10K上从66.70%提高到68.66%,在MegaDepth1500上从49.60%提高到50.45%。通过在训练期间教授几何一致性而不是在推理时强制执行它,GeLoc3r代表了神经网络学习相机几何的新范式,实现了回归的速度和对应方法的几何理解。
🔬 方法详解
问题定义:论文旨在解决相对相机位姿估计问题,现有ReLoc3R方法虽然速度快,但由于内部表示的几何不一致性,精度受限,无法达到基于对应关系的方法的精度水平。现有方法要么速度慢(基于对应关系),要么精度低(回归方法)。
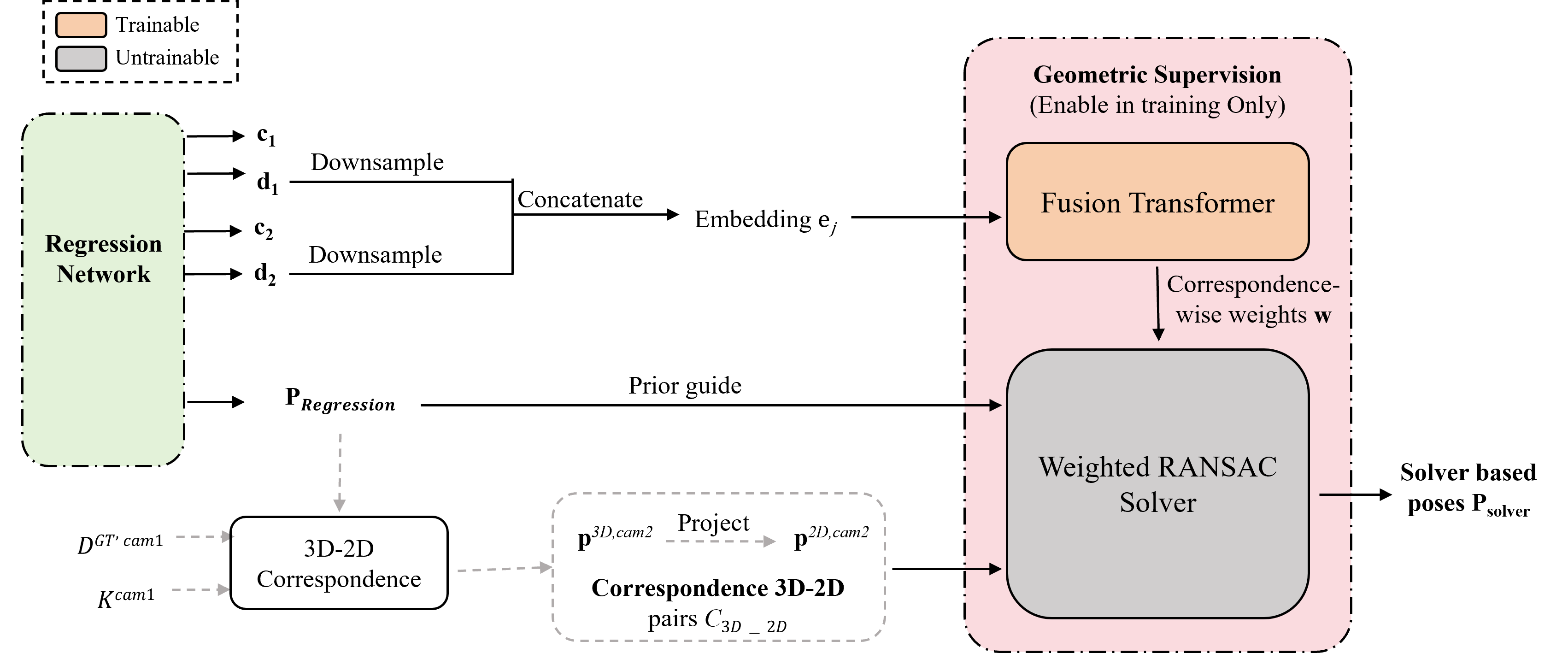
核心思路:核心思想是在训练阶段,通过引入几何一致性正则化(GCR),让回归网络学习到几何知识,从而在推理阶段仅使用回归网络就能获得高精度和高速度。通过在训练时利用深度信息构建3D-2D对应关系,并使用RANSAC计算几何一致的位姿,以此来指导回归网络的学习。
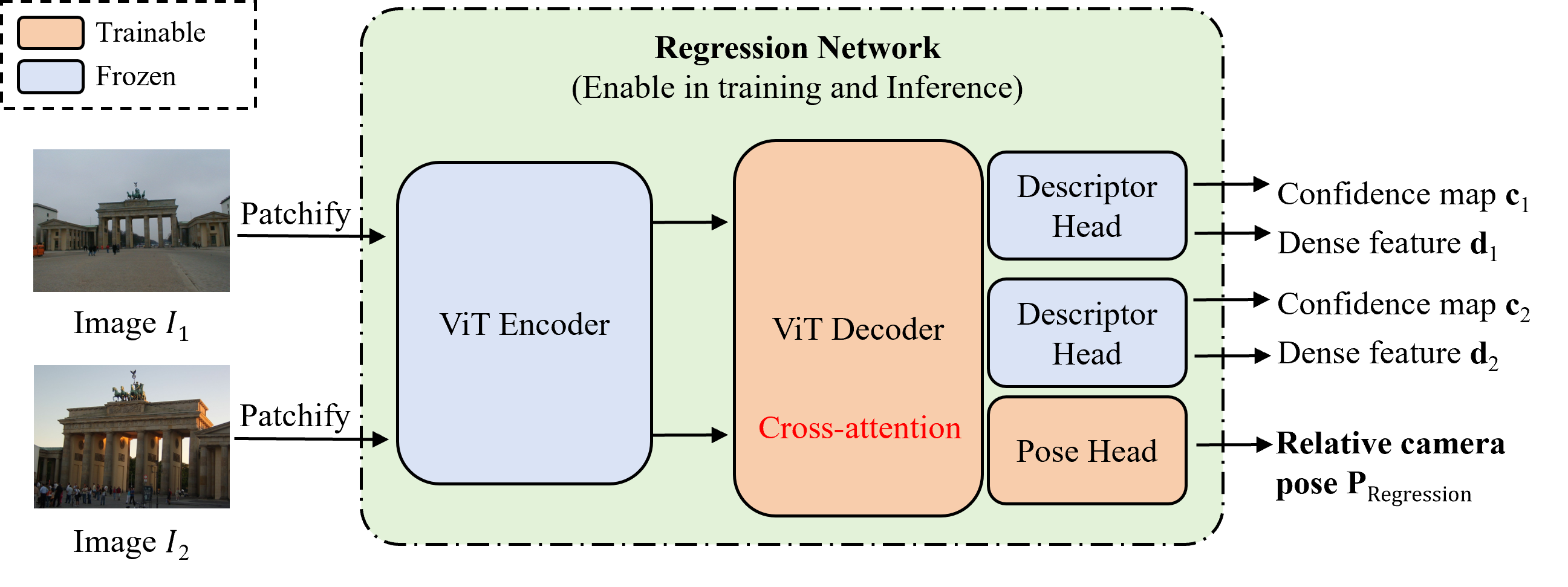
技术框架:GeLoc3r的整体框架包括以下几个主要模块:1) 3D-2D对应关系生成模块:利用ground-truth深度信息生成密集的3D-2D对应关系。2) FusionTransformer模块:学习每个对应关系的重要性权重。3) 位姿计算模块:使用加权RANSAC算法,根据3D-2D对应关系计算几何一致的位姿。4) 一致性损失计算模块:计算回归网络预测的位姿与几何一致位姿之间的损失,用于指导网络训练。
关键创新:最关键的创新点在于将几何一致性学习融入到训练过程中,而不是像传统方法那样在推理时进行几何计算。这使得GeLoc3r能够在保持回归方法速度的同时,获得接近基于对应关系方法的高精度。与FAR方法不同,GeLoc3r在推理时不需要进行几何求解,因此速度更快。
关键设计:FusionTransformer用于学习对应关系的重要性权重,其具体结构未知。一致性损失函数的设计是关键,需要平衡回归损失和几何一致性损失。加权RANSAC算法中的权重由FusionTransformer提供。具体损失函数的形式和权重比例未知。
🖼️ 关键图片
📊 实验亮点
GeLoc3r在CO3Dv2数据集上AUC@5°达到40.45%,相比ReLoc3R的34.85%有显著提升(相对提升16%)。在RealEstate10K和MegaDepth1500数据集上也取得了优于ReLoc3R的性能。GeLoc3r在保持ReLoc3R快速推理速度的同时,精度接近MASt3R,克服了速度-精度困境。
🎯 应用场景
GeLoc3r可应用于机器人导航、增强现实、三维重建等领域。在机器人导航中,可以帮助机器人更准确地估计自身位姿,从而实现更可靠的自主导航。在增强现实中,可以提高虚拟物体与真实场景的对齐精度,提升用户体验。在三维重建中,可以提高重建模型的精度和完整性。
📄 摘要(原文)
Prior ReLoc3R achieves breakthrough performance with fast 25ms inference and state-of-the-art regression accuracy, yet our analysis reveals subtle geometric inconsistencies in its internal representations that prevent reaching the precision ceiling of correspondence-based methods like MASt3R (which require 300ms per pair). In this work, we present GeLoc3r, a novel approach to relative camera pose estimation that enhances pose regression methods through Geometric Consistency Regularization (GCR). GeLoc3r overcomes the speed-accuracy dilemma by training regression networks to produce geometrically consistent poses without inference-time geometric computation. During training, GeLoc3r leverages ground-truth depth to generate dense 3D-2D correspondences, weights them using a FusionTransformer that learns correspondence importance, and computes geometrically-consistent poses via weighted RANSAC. This creates a consistency loss that transfers geometric knowledge into the regression network. Unlike FAR method which requires both regression and geometric solving at inference, GeLoc3r only uses the enhanced regression head at test time, maintaining ReLoc3R's fast speed and approaching MASt3R's high accuracy. On challenging benchmarks, GeLoc3r consistently outperforms ReLoc3R, achieving significant improvements including 40.45% vs. 34.85% AUC@5° on the CO3Dv2 dataset (16% relative improvement), 68.66% vs. 66.70% AUC@5° on RealEstate10K, and 50.45% vs. 49.60% on MegaDepth1500. By teaching geometric consistency during training rather than enforcing it at inference, GeLoc3r represents a paradigm shift in how neural networks learn camera geometry, achieving both the speed of regression and the geometric understanding of correspondence methods.