Planning with Unified Multimodal Models
作者: Yihao Sun, Zhilong Zhang, Yang Yu, Pierre-Luc Bacon
分类: cs.CV
发布日期: 2025-09-27
备注: 29 pages, 11 figures
💡 一句话要点
提出Uni-Plan,利用统一多模态模型进行长程规划,提升决策能力。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 统一多模态模型 长程规划 决策制定 自判别过滤 视觉语言模型
📋 核心要点
- 现有方法主要依赖于基于语言的推理,限制了其推理和做出明智决策的能力,尤其是在复杂环境中。
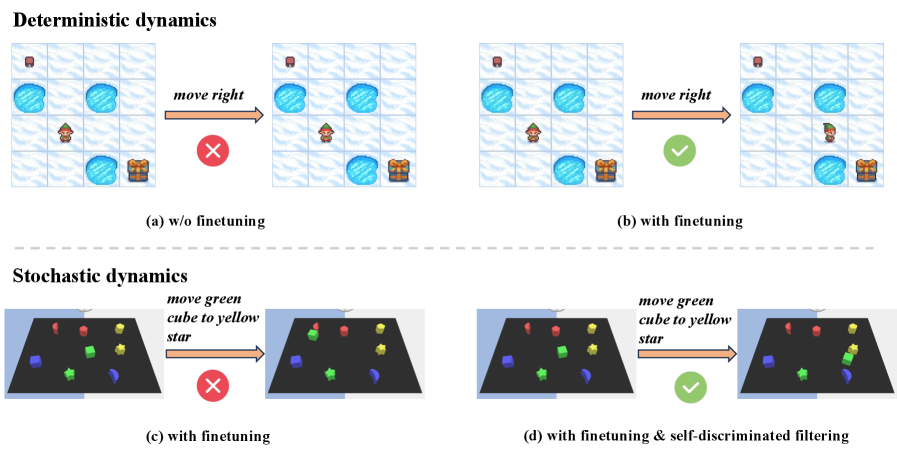
- Uni-Plan利用统一多模态模型,通过生成视觉内容进行推理,并采用自判别过滤来避免动力学预测中的幻觉。
- 实验表明,Uni-Plan在长程规划任务中显著提高了成功率,并展现出良好的数据可扩展性,无需专家演示。
📝 摘要(中文)
本文提出Uni-Plan,一个基于统一多模态模型(UMM)的规划框架,旨在利用UMM同时处理多模态输入和输出的优势,提升决策能力。该框架将单个模型用作策略、动力学模型和价值函数。为了避免动力学预测中的幻觉问题,论文提出了一种新颖的自判别过滤方法,其中生成模型作为自判别器来过滤无效的动力学预测。在长程规划任务上的实验表明,与基于视觉-语言模型(VLM)的方法相比,Uni-Plan显著提高了成功率,并且表现出强大的数据可扩展性,无需专家演示,并在相同训练数据量下实现了更好的性能。这项工作为未来使用UMM进行推理和决策的研究奠定了基础。
🔬 方法详解
问题定义:现有基于语言模型的决策方法在处理复杂环境和需要视觉信息辅助的规划任务时存在局限性。它们无法有效地利用视觉信息进行推理和预测,导致规划效果不佳,尤其是在长程规划中,容易出现幻觉和不准确的预测。
核心思路:论文的核心思路是利用统一多模态模型(UMM)同时处理多模态输入和输出的能力,将视觉信息融入到规划过程中。通过让模型生成视觉内容,辅助其进行推理和决策,从而提高规划的准确性和鲁棒性。此外,采用自判别过滤机制来减少动力学预测中的幻觉。
技术框架:Uni-Plan框架的核心是一个统一多模态模型,该模型同时充当策略、动力学模型和价值函数。框架的整体流程如下:1) 输入当前状态(包括视觉信息和语言指令);2) 模型生成下一步动作和预测的未来状态(包括视觉内容);3) 自判别器(即生成模型本身)评估预测状态的有效性;4) 根据价值函数评估状态,并选择最优动作。该过程迭代进行,直到完成规划目标。
关键创新:论文的关键创新在于:1) 提出了Uni-Plan框架,将统一多模态模型应用于长程规划任务;2) 提出了自判别过滤方法,利用生成模型本身作为判别器,过滤掉无效的动力学预测,从而减少幻觉;3) 将策略、动力学模型和价值函数集成到一个统一模型中,简化了训练和推理过程。与现有方法相比,Uni-Plan能够更好地利用视觉信息进行推理和决策,从而提高规划的准确性和鲁棒性。
关键设计:自判别过滤的关键在于利用生成模型的重构能力。对于预测的未来状态,模型尝试将其重构回原始状态。如果重构误差超过阈值,则认为该预测无效,并将其过滤掉。损失函数包括动作预测损失、状态预测损失和价值函数损失。具体的网络结构和参数设置取决于所使用的UMM的具体架构。
🖼️ 关键图片


📊 实验亮点
实验结果表明,Uni-Plan在长程规划任务中显著优于基于VLM的方法。具体而言,Uni-Plan在成功率方面取得了显著提升,并且在相同训练数据量下,性能优于需要专家演示的方法。这表明Uni-Plan具有强大的数据可扩展性和泛化能力。
🎯 应用场景
Uni-Plan框架具有广泛的应用前景,例如机器人导航、自动驾驶、游戏AI等领域。它可以应用于需要复杂推理和决策的场景,尤其是在环境感知和预测方面。该研究为未来利用多模态模型进行智能决策提供了新的思路,有望推动人工智能技术的发展。
📄 摘要(原文)
With the powerful reasoning capabilities of large language models (LLMs) and vision-language models (VLMs), many recent works have explored using them for decision-making. However, most of these approaches rely solely on language-based reasoning, which limits their ability to reason and make informed decisions. Recently, a promising new direction has emerged with unified multimodal models (UMMs), which support both multimodal inputs and outputs. We believe such models have greater potential for decision-making by enabling reasoning through generated visual content. To this end, we propose Uni-Plan, a planning framework built on UMMs. Within this framework, a single model simultaneously serves as the policy, dynamics model, and value function. In addition, to avoid hallucinations in dynamics predictions, we present a novel approach self-discriminated filtering, where the generative model serves as a self-discriminator to filter out invalid dynamics predictions. Experiments on long-horizon planning tasks show that Uni-Plan substantially improves success rates compared to VLM-based methods, while also showing strong data scalability, requiring no expert demonstrations and achieving better performance under the same training-data size. This work lays a foundation for future research in reasoning and decision-making with UMMs.