VideoScore2: Think before You Score in Generative Video Evaluation
作者: Xuan He, Dongfu Jiang, Ping Nie, Minghao Liu, Zhengxuan Jiang, Mingyi Su, Wentao Ma, Junru Lin, Chun Ye, Yi Lu, Keming Wu, Benjamin Schneider, Quy Duc Do, Zhuofeng Li, Yiming Jia, Yuxuan Zhang, Guo Cheng, Haozhe Wang, Wangchunshu Zhou, Qunshu Lin, Yuanxing Zhang, Ge Zhang, Wenhao Huang, Wenhu Chen
分类: cs.CV, cs.AI, cs.CL
发布日期: 2025-09-26
🔗 代码/项目: PROJECT_PAGE
💡 一句话要点
VideoScore2:提出多维度、可解释的视频生成评估框架,提升评估准确性和可控性。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 视频生成评估 多维度评估 可解释性 思维链 强化学习
📋 核心要点
- 现有视频生成评估器通常输出单一不透明的分数,缺乏可解释性,且分析粒度粗糙,难以全面捕捉视频质量。
- VideoScore2通过显式评估视觉质量、文本对齐和物理一致性,并提供思维链推理,实现多维度、可解释的评估。
- 实验表明,VideoScore2在多个基准测试中显著提升了评估准确性,并能有效用于奖励建模,从而实现可控生成。
📝 摘要(中文)
本文提出VideoScore2,一个多维度、可解释且与人类对齐的视频评估框架,旨在解决文本到视频生成评估中存在的挑战。该框架显式地评估视觉质量、文本到视频的对齐以及物理/常识一致性,并生成详细的思维链推理过程。模型基于大规模数据集VideoFeedback2进行训练,该数据集包含27168个带有人工标注的视频,以及跨三个维度的分数和推理轨迹。训练过程采用两阶段流水线:首先进行监督式微调,然后使用带有Group Relative Policy Optimization (GRPO)的强化学习,以增强分析的鲁棒性。实验结果表明,VideoScore2在领域内基准测试VideoScore-Bench-v2上取得了44.35 (+5.94)的准确率,并在四个领域外基准测试(VideoGenReward-Bench、VideoPhy2等)上取得了平均50.37 (+4.32)的性能,同时提供了可解释的评估,通过有效的奖励建模,弥合了评估和可控生成之间的差距,适用于Best-of-N采样。
🔬 方法详解
问题定义:当前文本到视频生成技术快速发展,但如何有效评估生成视频的质量仍然是一个挑战。现有的评估方法通常只输出一个单一的、不透明的分数,缺乏可解释性,并且无法提供细粒度的分析,难以捕捉视频质量的各个方面,如视觉质量、语义一致性和物理合理性。
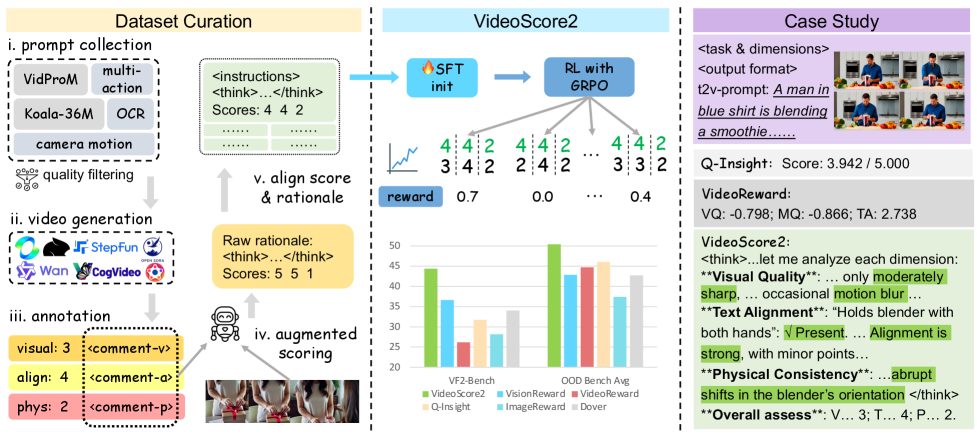
核心思路:VideoScore2的核心思路是将视频评估分解为多个维度,包括视觉质量、文本对齐和物理/常识一致性,并为每个维度提供可解释的评估结果。通过引入思维链(Chain-of-Thought)推理,模型能够生成详细的推理过程,从而提高评估的可解释性和可靠性。这种多维度、可解释的评估方法能够更全面地反映视频的质量,并为视频生成模型的改进提供更有效的反馈。
技术框架:VideoScore2的整体框架包含以下几个主要模块:1) 特征提取模块:用于提取视频的视觉特征和文本的语义特征。2) 多维度评估模块:针对视觉质量、文本对齐和物理/常识一致性三个维度进行评估,并生成相应的分数和推理过程。3) 奖励建模模块:利用评估结果作为奖励信号,用于训练视频生成模型。训练过程采用两阶段流水线:首先使用大规模人工标注数据集进行监督式微调,然后使用带有Group Relative Policy Optimization (GRPO)的强化学习进行优化。
关键创新:VideoScore2的关键创新在于其多维度、可解释的评估框架。与传统的单一分数评估方法相比,VideoScore2能够提供更全面、更细粒度的评估结果,并能够解释评估的原因。此外,VideoScore2还引入了思维链推理,进一步提高了评估的可解释性和可靠性。GRPO的使用也增强了模型的鲁棒性。
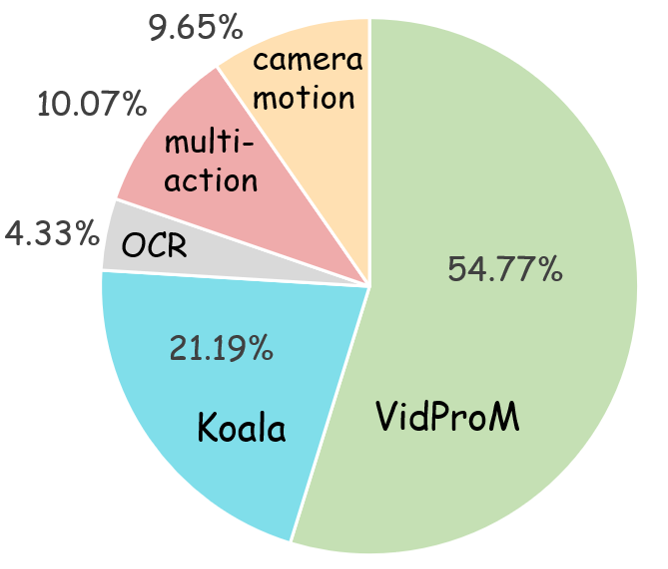
关键设计:VideoScore2的关键设计包括:1) 大规模人工标注数据集VideoFeedback2,包含27168个视频,以及跨三个维度的分数和推理轨迹。2) 使用预训练的视觉和语言模型作为特征提取器。3) 采用Transformer架构作为多维度评估模块的基础模型。4) 使用Group Relative Policy Optimization (GRPO)作为强化学习的优化算法,以提高模型的鲁棒性。
🖼️ 关键图片
📊 实验亮点
VideoScore2在VideoScore-Bench-v2上取得了44.35 (+5.94)的准确率,并在VideoGenReward-Bench、VideoPhy2等四个领域外基准测试上取得了平均50.37 (+4.32)的性能提升。这些结果表明,VideoScore2在评估准确性和泛化能力方面均优于现有方法。
🎯 应用场景
VideoScore2可广泛应用于文本到视频生成模型的评估和改进,例如用于优化生成模型的奖励函数,从而生成更高质量、更符合人类期望的视频。此外,该框架还可用于视频内容审核、视频质量评估等领域,具有重要的实际应用价值和潜在的商业前景。
📄 摘要(原文)
Recent advances in text-to-video generation have produced increasingly realistic and diverse content, yet evaluating such videos remains a fundamental challenge due to their multi-faceted nature encompassing visual quality, semantic alignment, and physical consistency. Existing evaluators and reward models are limited to single opaque scores, lack interpretability, or provide only coarse analysis, making them insufficient for capturing the comprehensive nature of video quality assessment. We present VideoScore2, a multi-dimensional, interpretable, and human-aligned framework that explicitly evaluates visual quality, text-to-video alignment, and physical/common-sense consistency while producing detailed chain-of-thought rationales. Our model is trained on a large-scale dataset VideoFeedback2 containing 27,168 human-annotated videos with both scores and reasoning traces across three dimensions, using a two-stage pipeline of supervised fine-tuning followed by reinforcement learning with Group Relative Policy Optimization (GRPO) to enhance analytical robustness. Extensive experiments demonstrate that VideoScore2 achieves superior performance with 44.35 (+5.94) accuracy on our in-domain benchmark VideoScore-Bench-v2 and 50.37 (+4.32) average performance across four out-of-domain benchmarks (VideoGenReward-Bench, VideoPhy2, etc), while providing interpretable assessments that bridge the gap between evaluation and controllable generation through effective reward modeling for Best-of-N sampling. Project Page: https://tiger-ai-lab.github.io/VideoScore2/