CapRL: Stimulating Dense Image Caption Capabilities via Reinforcement Learning
作者: Long Xing, Xiaoyi Dong, Yuhang Zang, Yuhang Cao, Jianze Liang, Qidong Huang, Jiaqi Wang, Feng Wu, Dahua Lin
分类: cs.CV, cs.AI, cs.CL
发布日期: 2025-09-26
备注: Code is available at https://github.com/InternLM/CapRL
🔗 代码/项目: GITHUB
💡 一句话要点
提出CapRL,利用强化学习提升图像描述的稠密性和实用性
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 图像描述 强化学习 视觉-语言模型 奖励函数 多模态学习
📋 核心要点
- 现有图像描述模型依赖监督微调,数据标注成本高昂,且模型易记忆标准答案,缺乏泛化性和创造性。
- CapRL利用强化学习,通过奖励机制引导模型生成更实用的描述,即能帮助语言模型准确回答图像相关问题。
- 实验表明,CapRL在多个基准测试中取得了显著提升,并在描述质量评估中达到或超过了现有先进模型。
📝 摘要(中文)
图像描述是连接视觉和语言领域的基础任务,在大规模视觉-语言模型(LVLM)的预训练中起着关键作用。目前最先进的图像描述模型通常采用监督微调(SFT)进行训练,这种模式依赖于昂贵且难以扩展的人工标注或专有模型生成的数据。这种方法通常导致模型记忆特定的标准答案,限制了其泛化能力和生成多样化、创造性描述的能力。为了克服SFT的局限性,我们提出将具有可验证奖励的强化学习(RLVR)范式应用于开放式的图像描述任务。然而,一个主要的挑战是为“好的”描述这种本质上主观的性质设计一个客观的奖励函数。我们引入了描述强化学习(CapRL),这是一个新颖的训练框架,它通过效用来重新定义描述质量:高质量的描述应该使非视觉语言模型能够准确地回答关于相应图像的问题。CapRL采用解耦的两阶段流程,其中LVLM生成描述,客观奖励来自独立的、无视觉的LLM仅基于该描述回答多项选择题的准确性。作为第一个将RLVR应用于主观图像描述任务的研究,我们证明了CapRL显著增强了多种设置。在由CapRL-3B标注的CapRL-5M描述数据集上进行预训练,在12个基准测试中获得了显著的提升。此外,在Prism框架下进行描述质量评估时,CapRL的性能与Qwen2.5-VL-72B相当,同时超过基线平均8.4%。代码已开源。
🔬 方法详解
问题定义:现有图像描述模型主要依赖于监督微调(SFT),需要大量人工标注或专有模型生成的数据。这种方式成本高昂且难以扩展,同时模型容易过拟合训练数据,导致生成的描述缺乏多样性和创造性,难以应对复杂场景。因此,如何降低数据依赖,提升模型泛化能力和描述质量是亟待解决的问题。
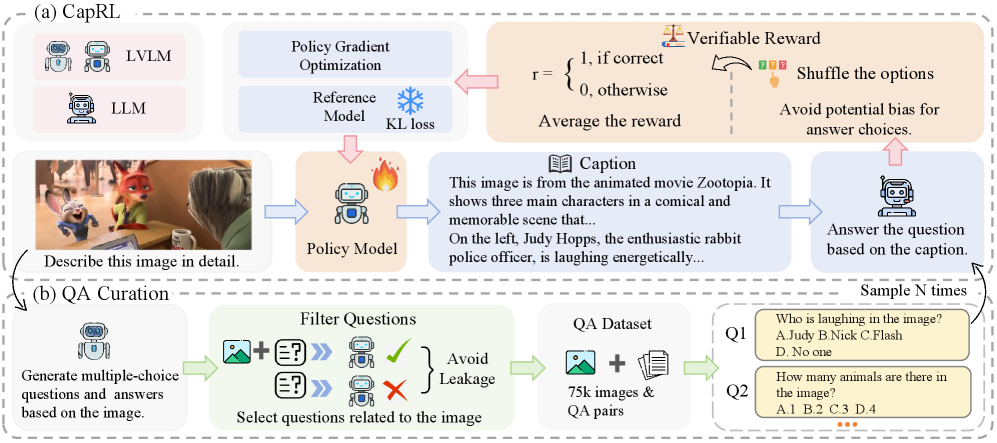
核心思路:CapRL的核心思路是将图像描述任务转化为一个强化学习问题,通过奖励机制来引导模型生成更实用的描述。这里的“实用性”被定义为:生成的描述能够帮助一个独立的语言模型准确回答关于图像的问题。这种方法避免了直接定义描述的“好坏”,而是通过下游任务的性能来间接评估描述质量。
技术框架:CapRL采用一个解耦的两阶段流程。第一阶段,一个视觉-语言模型(LVLM)根据输入图像生成描述。第二阶段,一个独立的、无视觉的语言模型(LLM)仅基于第一阶段生成的描述回答关于图像的多项选择题。LLM的回答准确率作为奖励信号,反馈给LVLM,用于优化其描述生成策略。整个框架通过强化学习算法进行训练。
关键创新:CapRL最重要的创新点在于将强化学习与图像描述任务相结合,并设计了一种基于下游任务性能的客观奖励函数。与传统的基于人工评估或预定义指标的奖励函数不同,CapRL的奖励函数能够更准确地反映描述的实用价值。此外,解耦的两阶段设计使得奖励信号的计算更加高效,避免了对LVLM进行直接的微调。
关键设计:CapRL的关键设计包括:1) 使用多项选择题作为评估描述质量的方式,避免了开放式问答带来的不确定性;2) 选择一个强大的、无视觉的LLM作为奖励评估器,确保奖励信号的准确性;3) 使用合适的强化学习算法(例如,策略梯度算法)来优化LVLM的描述生成策略;4) 构建大规模的CapRL-5M数据集,用于预训练和评估模型。
🖼️ 关键图片


📊 实验亮点
CapRL在12个基准测试中取得了显著的性能提升,证明了其有效性。在Prism框架下进行描述质量评估时,CapRL的性能与Qwen2.5-VL-72B相当,同时超过基线平均8.4%。这些结果表明,CapRL能够生成更高质量、更实用的图像描述,并为视觉-语言模型的预训练提供了一种新的有效方法。
🎯 应用场景
CapRL具有广泛的应用前景,可用于提升视觉-语言模型的预训练效果,改善图像搜索、智能客服、视觉辅助等应用的用户体验。通过生成更准确、更实用的图像描述,CapRL能够帮助机器更好地理解图像内容,并与人类进行更自然的交互。未来,该方法有望应用于机器人导航、自动驾驶等领域,提升机器的感知和决策能力。
📄 摘要(原文)
Image captioning is a fundamental task that bridges the visual and linguistic domains, playing a critical role in pre-training Large Vision-Language Models (LVLMs). Current state-of-the-art captioning models are typically trained with Supervised Fine-Tuning (SFT), a paradigm that relies on expensive, non-scalable data annotated by humans or proprietary models. This approach often leads to models that memorize specific ground-truth answers, limiting their generality and ability to generate diverse, creative descriptions. To overcome the limitation of SFT, we propose applying the Reinforcement Learning with Verifiable Rewards (RLVR) paradigm to the open-ended task of image captioning. A primary challenge, however, is designing an objective reward function for the inherently subjective nature of what constitutes a "good" caption. We introduce Captioning Reinforcement Learning (CapRL), a novel training framework that redefines caption quality through its utility: a high-quality caption should enable a non-visual language model to accurately answer questions about the corresponding image. CapRL employs a decoupled two-stage pipeline where an LVLM generates a caption, and the objective reward is derived from the accuracy of a separate, vision-free LLM answering Multiple-Choice Questions based solely on that caption. As the first study to apply RLVR to the subjective image captioning task, we demonstrate that CapRL significantly enhances multiple settings. Pretraining on the CapRL-5M caption dataset annotated by CapRL-3B results in substantial gains across 12 benchmarks. Moreover, within the Prism Framework for caption quality evaluation, CapRL achieves performance comparable to Qwen2.5-VL-72B, while exceeding the baseline by an average margin of 8.4%. Code is available here: https://github.com/InternLM/CapRL.