JanusVLN: Decoupling Semantics and Spatiality with Dual Implicit Memory for Vision-Language Navigation
作者: Shuang Zeng, Dekang Qi, Xinyuan Chang, Feng Xiong, Shichao Xie, Xiaolong Wu, Shiyi Liang, Mu Xu, Xing Wei
分类: cs.CV, cs.RO
发布日期: 2025-09-26
备注: Project page: https://miv-xjtu.github.io/JanusVLN.github.io/
🔗 代码/项目: PROJECT_PAGE
💡 一句话要点
JanusVLN:利用双重隐式记忆解耦语义与空间信息,提升视觉语言导航性能
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 视觉语言导航 双重隐式记忆 多模态学习 空间推理 机器人导航
📋 核心要点
- 现有VLN方法依赖显式语义记忆,如构建文本认知地图或存储历史视觉帧,导致空间信息损失和计算冗余。
- JanusVLN采用双重隐式神经记忆,分别建模空间几何和视觉语义信息,实现紧凑高效的记忆表示。
- 实验表明,JanusVLN在VLN任务上取得了显著的性能提升,成功率超越了多种先进方法。
📝 摘要(中文)
本文提出了一种名为JanusVLN的新型视觉语言导航(VLN)框架,旨在解决现有方法中空间信息丢失、计算冗余和内存膨胀等问题。该框架受到人类导航中语义理解(左脑)和空间认知(右脑)的启发,采用双重隐式神经记忆,将空间几何记忆和视觉语义记忆建模为分离、紧凑且固定大小的神经表示。JanusVLN首先扩展了多模态大型语言模型(MLLM),使其能够整合来自空间几何编码器的3D先验知识,从而增强模型仅基于RGB输入的空间推理能力。然后,将来自空间几何和视觉语义编码器的历史键值缓存构建成双重隐式记忆,通过仅保留初始和滑动窗口中token的KV,避免了冗余计算,实现了高效的增量更新。实验结果表明,JanusVLN优于20多种现有方法,取得了SOTA性能。例如,与使用多种数据类型作为输入的方法相比,成功率提高了10.5-35.5%;与使用更多RGB训练数据的方法相比,成功率提高了3.6-10.8%。
🔬 方法详解
问题定义:视觉语言导航(VLN)任务要求智能体在自然语言指令的引导下,通过连续的视频流在未知的环境中导航。现有方法,特别是基于多模态大型语言模型(MLLM)的方法,通常依赖于显式的语义记忆,例如构建文本认知地图或存储历史视觉帧。这些方法存在空间信息丢失、计算冗余和内存膨胀等问题,阻碍了高效导航。
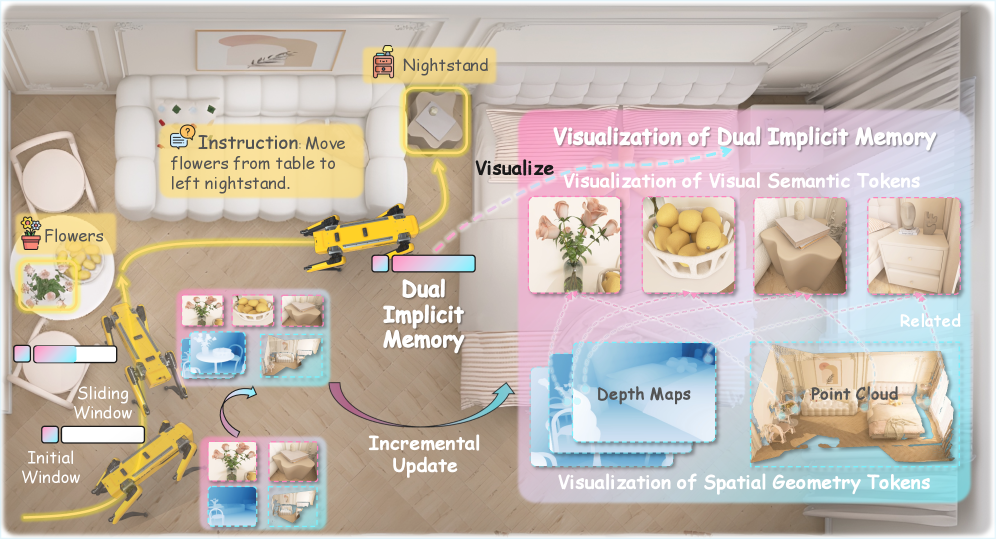
核心思路:受到人类导航过程中语义理解和空间认知分别由大脑不同区域处理的启发,论文提出了JanusVLN,该框架采用双重隐式神经记忆来分别建模空间几何和视觉语义信息。通过将这两种信息解耦并以紧凑的神经表示形式存储,可以更有效地利用它们进行导航。
技术框架:JanusVLN框架包含以下主要模块:1) 空间几何编码器:用于提取场景的3D先验知识。2) 视觉语义编码器:用于提取视觉语义信息。3) 双重隐式神经记忆:由空间几何和视觉语义编码器的历史键值缓存构建而成,用于存储和检索导航过程中的关键信息。4) MLLM:扩展了MLLM,使其能够整合来自空间几何编码器的3D先验知识,并利用双重隐式神经记忆进行导航决策。整体流程是,首先使用空间几何和视觉语义编码器提取特征,然后将特征存储到双重隐式神经记忆中,最后使用MLLM根据指令和记忆进行导航。
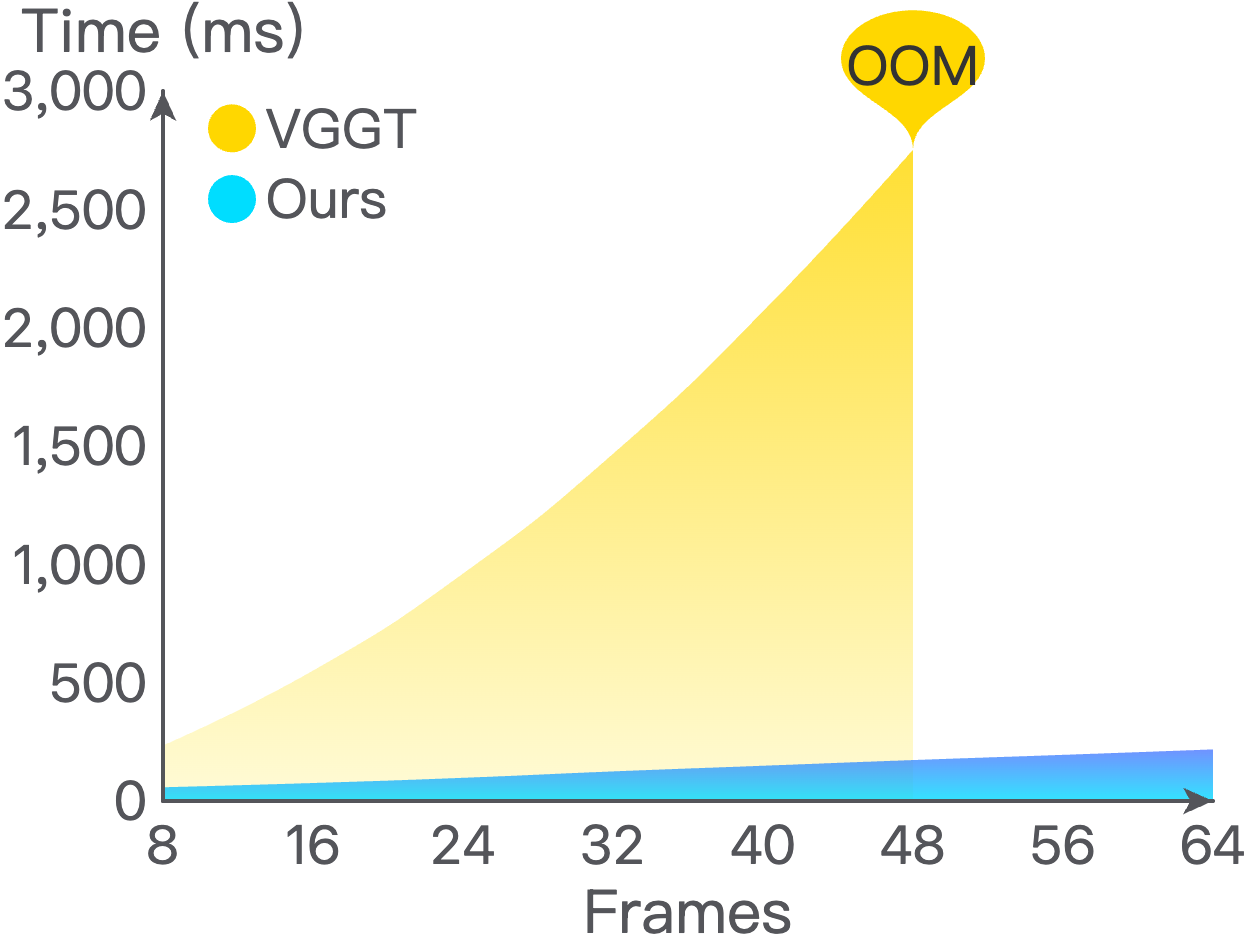
关键创新:JanusVLN的关键创新在于提出了双重隐式神经记忆,它将空间几何和视觉语义信息解耦并以紧凑的神经表示形式存储。与现有方法中使用的显式语义记忆相比,双重隐式神经记忆可以更有效地利用空间信息,并避免计算冗余和内存膨胀。此外,通过仅保留初始和滑动窗口中token的KV,避免了冗余计算,实现了高效的增量更新。
关键设计:空间几何编码器使用预训练的3D场景重建模型来提取场景的3D先验知识。视觉语义编码器使用预训练的视觉模型来提取视觉语义信息。双重隐式神经记忆使用键值缓存机制来存储和检索导航过程中的关键信息。MLLM使用交叉注意力机制来融合来自空间几何编码器、视觉语义编码器和双重隐式神经记忆的信息。损失函数包括导航损失和辅助损失,用于优化模型的导航性能和记忆表示。
🖼️ 关键图片

📊 实验亮点
JanusVLN在VLN任务上取得了显著的性能提升,超越了20多种现有方法,达到了SOTA水平。例如,与使用多种数据类型作为输入的方法相比,成功率提高了10.5-35.5%;与使用更多RGB训练数据的方法相比,成功率提高了3.6-10.8%。这些结果表明,JanusVLN提出的双重隐式神经记忆是一种有效的新型VLN范式。
🎯 应用场景
JanusVLN在机器人导航、自动驾驶、虚拟现实等领域具有广泛的应用前景。它可以帮助机器人在复杂的环境中更准确、更高效地完成导航任务,提升用户体验。未来,该技术可以进一步应用于室内服务机器人、物流配送机器人等领域,实现更智能化的服务。
📄 摘要(原文)
Vision-and-Language Navigation requires an embodied agent to navigate through unseen environments, guided by natural language instructions and a continuous video stream. Recent advances in VLN have been driven by the powerful semantic understanding of Multimodal Large Language Models. However, these methods typically rely on explicit semantic memory, such as building textual cognitive maps or storing historical visual frames. This type of method suffers from spatial information loss, computational redundancy, and memory bloat, which impede efficient navigation. Inspired by the implicit scene representation in human navigation, analogous to the left brain's semantic understanding and the right brain's spatial cognition, we propose JanusVLN, a novel VLN framework featuring a dual implicit neural memory that models spatial-geometric and visual-semantic memory as separate, compact, and fixed-size neural representations. This framework first extends the MLLM to incorporate 3D prior knowledge from the spatial-geometric encoder, thereby enhancing the spatial reasoning capabilities of models based solely on RGB input. Then, the historical key-value caches from the spatial-geometric and visual-semantic encoders are constructed into a dual implicit memory. By retaining only the KVs of tokens in the initial and sliding window, redundant computation is avoided, enabling efficient incremental updates. Extensive experiments demonstrate that JanusVLN outperforms over 20 recent methods to achieve SOTA performance. For example, the success rate improves by 10.5-35.5 compared to methods using multiple data types as input and by 3.6-10.8 compared to methods using more RGB training data. This indicates that the proposed dual implicit neural memory, as a novel paradigm, explores promising new directions for future VLN research. Ours project page: https://miv-xjtu.github.io/JanusVLN.github.io/.