Explaining multimodal LLMs via intra-modal token interactions
作者: Jiawei Liang, Ruoyu Chen, Xianghao Jiao, Siyuan Liang, Shiming Liu, Qunli Zhang, Zheng Hu, Xiaochun Cao
分类: cs.CV, cs.AI
发布日期: 2025-09-26 (更新: 2025-10-01)
💡 一句话要点
通过模态内token交互增强多模态LLM的可解释性
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态学习 可解释性 视觉语言模型 token交互 模型归因
📋 核心要点
- 现有MLLM可解释性方法忽略了模态内部token间的依赖关系,导致视觉解释分散、文本解释存在虚假激活。
- 论文提出利用模态内交互增强可解释性,视觉模态采用多尺度解释聚合,文本模态采用激活排序相关性。
- 实验表明,该方法在多个MLLM和数据集上优于现有方法,生成更忠实和细粒度的模型行为解释。
📝 摘要(中文)
多模态大型语言模型(MLLM)在各种视觉-语言任务中取得了显著成功,但其内部决策机制仍未得到充分理解。现有的可解释性研究主要集中于跨模态归因,即识别模型在输出生成过程中关注的图像区域。然而,这些方法通常忽略了模态内的依赖关系。在视觉模态中,由于感受野有限,将重要性归因于孤立的图像块会忽略空间上下文,导致解释分散且嘈杂。在文本模态中,依赖于前面的token会引入虚假激活。未能有效缓解这些干扰会损害归因的保真度。为了解决这些限制,我们提出通过利用模态内交互来增强可解释性。对于视觉分支,我们引入了多尺度解释聚合(MSEA),它聚合多尺度输入的归因,以动态调整感受野,从而产生更整体和空间连贯的视觉解释。对于文本分支,我们提出了激活排序相关性(ARC),它通过对齐上下文token的top-k预测排名来衡量上下文token与当前token的相关性。ARC利用这种相关性来抑制来自不相关上下文的虚假激活,同时保留语义连贯的激活。在最先进的MLLM和基准数据集上进行的大量实验表明,我们的方法始终优于现有的可解释性方法,从而产生更忠实和细粒度的模型行为解释。
🔬 方法详解
问题定义:现有MLLM的可解释性方法主要关注跨模态的归因,忽略了模态内部token之间的依赖关系。在视觉模态中,由于感受野的限制,对孤立图像块的归因导致空间上下文信息的丢失,产生分散且噪声大的解释。在文本模态中,依赖于前序token会引入虚假的激活,影响归因的准确性。
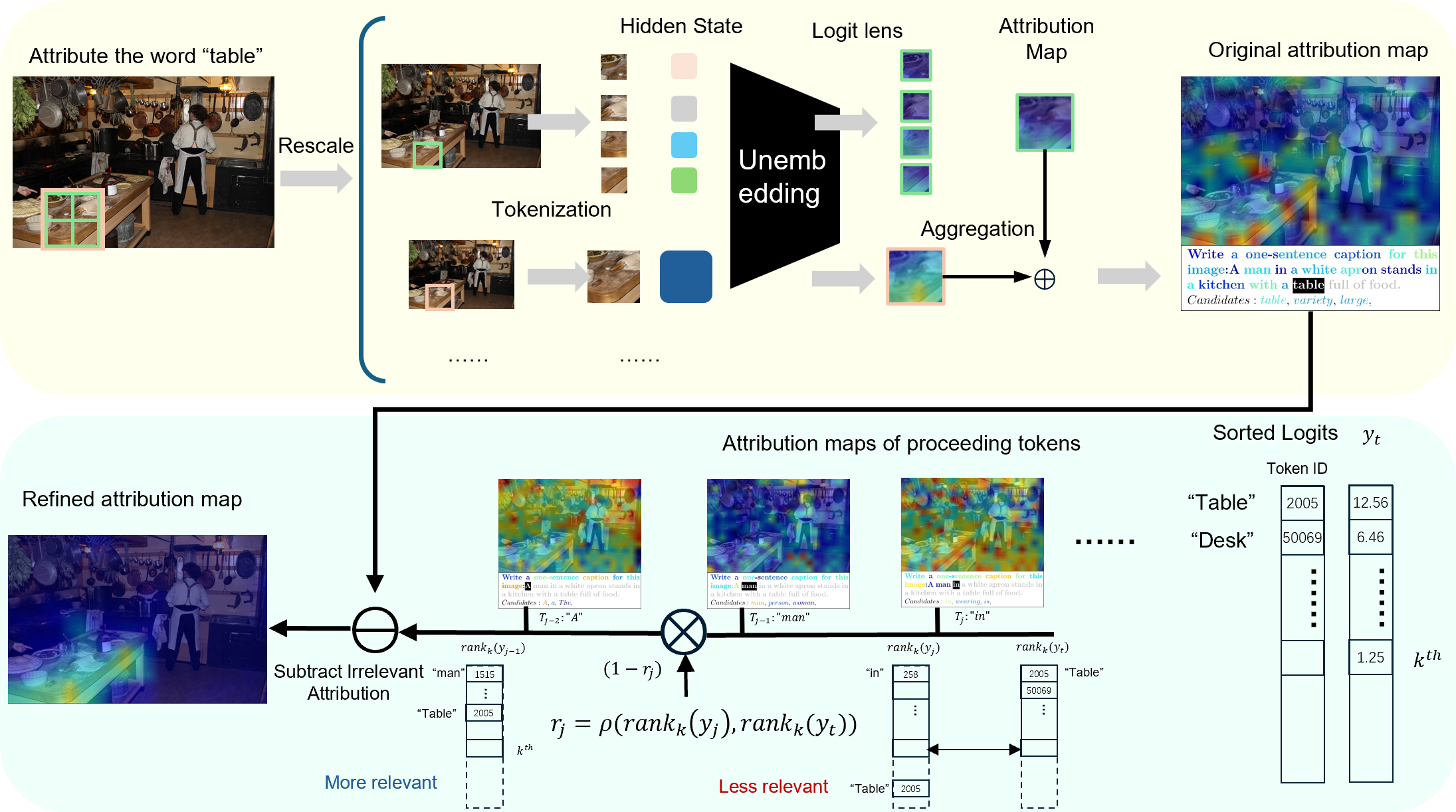
核心思路:论文的核心思路是通过引入模态内的交互来增强MLLM的可解释性。具体来说,针对视觉模态,通过聚合多尺度的解释来动态调整感受野,从而获得更全面的空间上下文信息。针对文本模态,通过衡量上下文token与当前token的相关性来抑制虚假的激活,保留语义上相关的激活。
技术框架:该方法主要包含两个模块:多尺度解释聚合(MSEA)和激活排序相关性(ARC)。MSEA用于增强视觉模态的解释,ARC用于增强文本模态的解释。MSEA通过聚合不同尺度的图像输入的归因图,从而获得更全局的视觉上下文信息。ARC通过计算上下文token的top-k预测排名与当前token的top-k预测排名的相关性,来衡量上下文token与当前token的相关程度。
关键创新:该方法最重要的创新点在于同时考虑了视觉和文本模态内部的token交互,并分别设计了MSEA和ARC来利用这些交互信息。与现有方法相比,该方法能够生成更连贯、更准确的解释,从而更好地理解MLLM的决策过程。
关键设计:在MSEA中,关键在于选择合适的尺度集合以及聚合不同尺度归因图的方式。在ARC中,关键在于选择合适的top-k值以及计算排名相关性的方法。论文中具体使用了哪些参数设置和计算方法未知。
🖼️ 关键图片


📊 实验亮点
实验结果表明,所提出的MSEA和ARC方法在多个MLLM和基准数据集上均优于现有的可解释性方法。具体性能提升数据未知,但论文强调该方法能够生成更忠实和细粒度的模型行为解释,有效缓解了视觉解释的分散性和文本解释的虚假激活问题。
🎯 应用场景
该研究成果可应用于提升多模态大语言模型的可信度和透明度,帮助用户理解模型的决策依据,从而在医疗诊断、自动驾驶等安全攸关领域增强模型的可信赖程度。此外,该方法也有助于模型调试和优化,发现潜在的偏差和错误。
📄 摘要(原文)
Multimodal Large Language Models (MLLMs) have achieved remarkable success across diverse vision-language tasks, yet their internal decision-making mechanisms remain insufficiently understood. Existing interpretability research has primarily focused on cross-modal attribution, identifying which image regions the model attends to during output generation. However, these approaches often overlook intra-modal dependencies. In the visual modality, attributing importance to isolated image patches ignores spatial context due to limited receptive fields, resulting in fragmented and noisy explanations. In the textual modality, reliance on preceding tokens introduces spurious activations. Failing to effectively mitigate these interference compromises attribution fidelity. To address these limitations, we propose enhancing interpretability by leveraging intra-modal interaction. For the visual branch, we introduce \textit{Multi-Scale Explanation Aggregation} (MSEA), which aggregates attributions over multi-scale inputs to dynamically adjust receptive fields, producing more holistic and spatially coherent visual explanations. For the textual branch, we propose \textit{Activation Ranking Correlation} (ARC), which measures the relevance of contextual tokens to the current token via alignment of their top-$k$ prediction rankings. ARC leverages this relevance to suppress spurious activations from irrelevant contexts while preserving semantically coherent ones. Extensive experiments across state-of-the-art MLLMs and benchmark datasets demonstrate that our approach consistently outperforms existing interpretability methods, yielding more faithful and fine-grained explanations of model behavior.