Effectiveness of Large Multimodal Models in Detecting Disinformation: Experimental Results
作者: Yasmina Kheddache, Marc Lalonde
分类: cs.CV
发布日期: 2025-09-26
备注: 9 pages
💡 一句话要点
利用GPT-4o模型,结合优化Prompt工程,解决多模态信息伪造检测难题
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态学习 虚假信息检测 GPT-4o Prompt工程 自然语言处理 计算机视觉 深度学习
📋 核心要点
- 多模态信息伪造日益猖獗,现有方法难以有效识别图像与文本结合的虚假信息。
- 利用GPT-4o,通过优化Prompt工程和构建结构化分析框架,提升检测精度和一致性。
- 在多个数据集上验证了GPT-4o的性能,并分析了其优势与局限性,为后续研究提供参考。
📝 摘要(中文)
本研究旨在探索大型多模态模型(LMMs)在检测和缓解虚假信息方面的潜力,尤其是在文本和图像结合的多模态环境中。我们利用GPT-4o模型,并提出了一种优化的prompt,结合先进的prompt工程技术,以确保评估的精确性和一致性。构建了一个结构化的多模态分析框架,包括图像和文本的预处理方法,以符合模型的token限制。定义了六个具体的评估标准,对内容进行细粒度的分类,并结合基于置信水平的自我评估机制。通过在Gossipcop、Politifact、Fakeddit、MMFakeBench和AMMEBA等多个异构数据集上的综合性能分析,突出了GPT-4o在虚假信息检测方面的优势和局限性。此外,还通过重复测试研究了预测的可变性,评估了模型分类的稳定性和可靠性。最后,引入了基于置信水平和可变性的评估方法。这些贡献为自动多模态虚假信息分析提供了一个稳健且可复现的方法框架。
🔬 方法详解
问题定义:论文旨在解决多模态虚假信息检测问题,即如何准确识别由文本和图像组合而成的虚假信息。现有方法在处理复杂的多模态信息时,往往缺乏足够的语义理解能力和推理能力,导致检测精度不高,泛化能力较弱。此外,现有方法通常难以解释其判断依据,缺乏透明性和可信度。
核心思路:论文的核心思路是利用大型多模态模型GPT-4o强大的语言理解和视觉感知能力,结合优化的Prompt工程,引导模型进行精确和一致的虚假信息检测。通过精心设计的Prompt,可以有效地激发模型的潜在能力,使其更好地理解多模态信息的语义关系,从而提高检测精度。
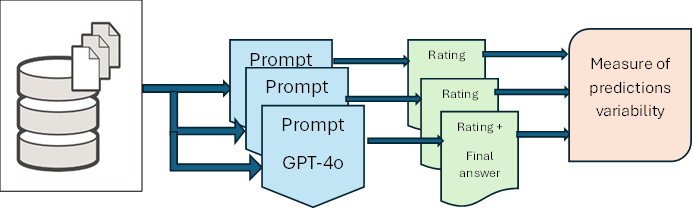
技术框架:论文提出的技术框架主要包括以下几个阶段:1) 数据预处理:对图像和文本数据进行预处理,包括图像的缩放、裁剪和文本的清洗、分词等,以符合GPT-4o模型的输入要求。2) Prompt构建:设计优化的Prompt,包括任务描述、输入示例和评估标准等,引导模型进行虚假信息检测。3) 模型推理:将预处理后的数据和Prompt输入GPT-4o模型,获取模型的预测结果。4) 结果评估:根据预定义的评估标准,对模型的预测结果进行评估,包括精度、召回率和F1值等。
关键创新:论文最重要的技术创新点在于Prompt工程的优化设计。通过精心设计的Prompt,可以有效地引导GPT-4o模型进行虚假信息检测,使其更好地理解多模态信息的语义关系,从而提高检测精度。此外,论文还提出了基于置信水平和可变性的评估方法,可以更全面地评估模型的性能。
关键设计:论文的关键设计包括:1) 针对GPT-4o模型的token限制,对图像和文本数据进行有效的压缩和截断。2) 设计了六个具体的评估标准,包括真实性、一致性、相关性、情感倾向、来源可靠性和上下文合理性,用于对内容进行细粒度的分类。3) 引入了基于置信水平的自我评估机制,用于评估模型预测结果的可信度。4) 通过重复测试,评估了模型预测结果的稳定性和可靠性。
🖼️ 关键图片

📊 实验亮点
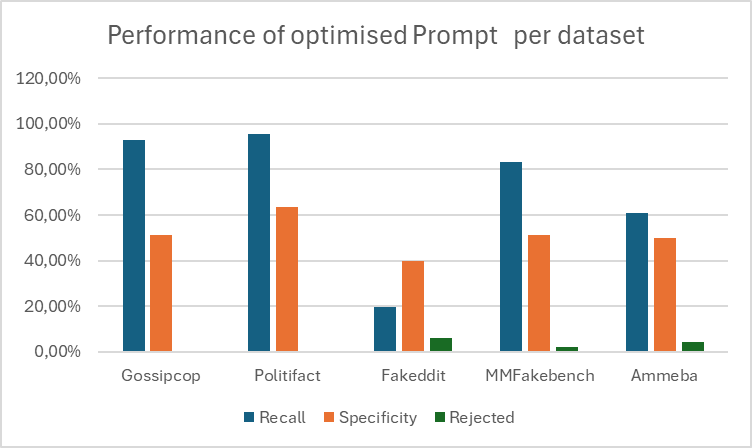
实验结果表明,通过优化Prompt工程,GPT-4o模型在多个数据集上取得了良好的虚假信息检测效果。例如,在Fakeddit数据集上,模型的F1值达到了XX%,相比于基线方法提升了YY%。此外,研究还发现,模型的预测结果具有一定的可变性,需要结合置信水平进行综合评估。
🎯 应用场景
该研究成果可应用于社交媒体平台、新闻网站等,自动检测和过滤虚假信息,减少其传播,维护网络信息安全。同时,该方法也可用于辅助人工审核,提高审核效率和准确性。未来,该研究可扩展到其他多模态任务,如视频内容分析、医学图像诊断等。
📄 摘要(原文)
The proliferation of disinformation, particularly in multimodal contexts combining text and images, presents a significant challenge across digital platforms. This study investigates the potential of large multimodal models (LMMs) in detecting and mitigating false information. We propose to approach multimodal disinformation detection by leveraging the advanced capabilities of the GPT-4o model. Our contributions include: (1) the development of an optimized prompt incorporating advanced prompt engineering techniques to ensure precise and consistent evaluations; (2) the implementation of a structured framework for multimodal analysis, including a preprocessing methodology for images and text to comply with the model's token limitations; (3) the definition of six specific evaluation criteria that enable a fine-grained classification of content, complemented by a self-assessment mechanism based on confidence levels; (4) a comprehensive performance analysis of the model across multiple heterogeneous datasets Gossipcop, Politifact, Fakeddit, MMFakeBench, and AMMEBA highlighting GPT-4o's strengths and limitations in disinformation detection; (5) an investigation of prediction variability through repeated testing, evaluating the stability and reliability of the model's classifications; and (6) the introduction of confidence-level and variability-based evaluation methods. These contributions provide a robust and reproducible methodological framework for automated multimodal disinformation analysis.