MesaTask: Towards Task-Driven Tabletop Scene Generation via 3D Spatial Reasoning
作者: Jinkun Hao, Naifu Liang, Zhen Luo, Xudong Xu, Weipeng Zhong, Ran Yi, Yichen Jin, Zhaoyang Lyu, Feng Zheng, Lizhuang Ma, Jiangmiao Pang
分类: cs.CV, cs.RO
发布日期: 2025-09-26
备注: Accepted by NeurIPS 2025; Project page: https://mesatask.github.io/
💡 一句话要点
MesaTask:提出基于3D空间推理的任务驱动型桌面场景生成框架
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱二:RL算法与架构 (RL & Architecture) 支柱四:生成式动作 (Generative Motion)
关键词: 桌面场景生成 3D空间推理 任务驱动 大型语言模型 机器人操作
📋 核心要点
- 传统桌面场景生成方法依赖手动设计或随机布局,难以保证场景的合理性以及与任务的对齐。
- 论文提出空间推理链,将场景生成分解为对象推理、空间关系推理和场景图构建,弥合任务与场景的鸿沟。
- 实验结果表明,MesaTask生成的桌面场景在任务符合性和布局真实性方面优于现有基线方法。
📝 摘要(中文)
本文提出了一种新的任务:面向任务的桌面场景生成,旨在解决高层任务指令与桌面场景之间的巨大差距。为了支持该任务的研究,作者构建了一个大规模数据集MesaTask-10K,包含约10700个合成桌面场景,这些场景具有人工设计的布局,确保了布局的真实性和复杂的对象间关系。为了弥合任务和场景之间的差距,作者提出了一个空间推理链,将生成过程分解为对象推理、空间关系推理和场景图构建,最终生成3D布局。作者提出了一个基于LLM的框架MesaTask,该框架利用了空间推理链,并通过DPO算法进一步增强,以生成与给定任务描述相符的、物理上合理的桌面场景。大量的实验表明,与基线方法相比,MesaTask在生成符合任务的、具有真实布局的桌面场景方面表现出优越的性能。
🔬 方法详解
问题定义:论文旨在解决机器人操作任务训练中,缺乏与任务相关的真实桌面场景的问题。现有方法要么依赖耗时的人工设计,要么采用纯随机布局,导致生成的场景缺乏真实性和任务相关性,无法有效支持机器人操作任务的学习。
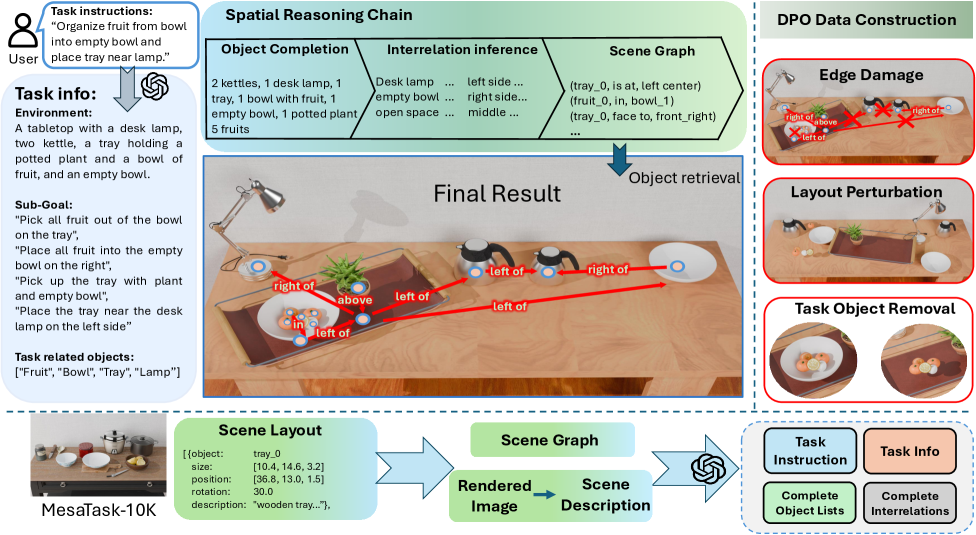
核心思路:论文的核心思路是将桌面场景生成过程分解为多个可控的步骤,通过显式的空间推理来弥合高层任务指令和底层3D场景之间的差距。通过引入空间推理链,模型可以逐步推断场景中应该包含哪些物体、物体之间的空间关系以及最终的3D布局,从而生成更符合任务描述且物理上合理的场景。
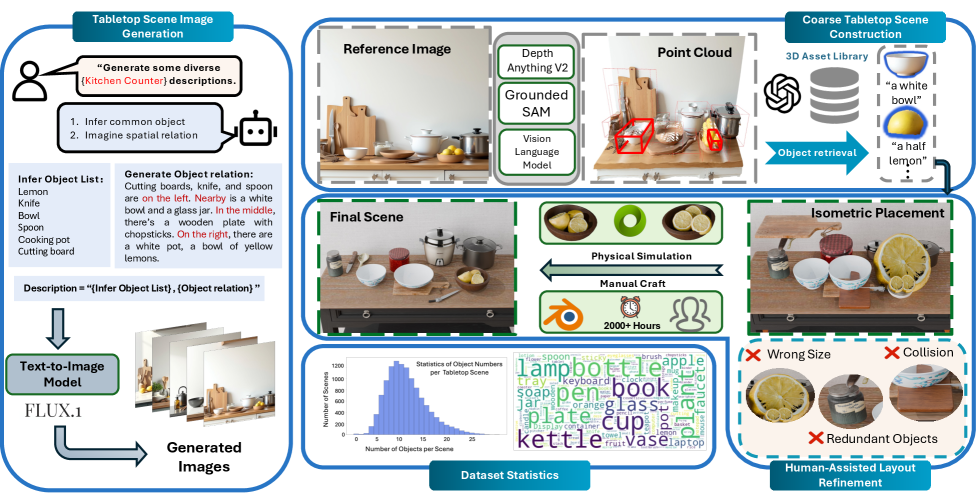
技术框架:MesaTask框架主要包含以下几个模块:1) 对象推理:根据任务描述推断场景中需要包含的物体;2) 空间关系推理:确定物体之间的空间关系,例如“A在B的上方”;3) 场景图构建:将物体和它们之间的空间关系表示为场景图;4) 3D布局生成:根据场景图生成最终的3D场景布局。该框架利用大型语言模型(LLM)作为核心推理引擎,并使用DPO算法进行微调,以提高生成场景的质量和任务相关性。
关键创新:论文的关键创新在于提出了空间推理链,将复杂的场景生成任务分解为多个可解释的步骤,使得模型能够更好地理解任务描述并生成符合任务要求的场景。此外,论文还构建了一个大规模的桌面场景数据集MesaTask-10K,为该领域的研究提供了重要的数据支持。与现有方法相比,MesaTask能够生成更真实、更符合任务要求的桌面场景。
关键设计:在空间关系推理模块中,论文设计了一组预定义的空间关系,例如“above”、“below”、“next to”等,用于描述物体之间的相对位置。在DPO微调过程中,论文使用人工标注的偏好数据来指导模型的学习,使得模型能够生成更符合人类期望的场景。此外,论文还设计了一系列评估指标,用于衡量生成场景的任务相关性和物理合理性。
🖼️ 关键图片

📊 实验亮点
实验结果表明,MesaTask在生成任务相关的桌面场景方面显著优于基线方法。具体而言,MesaTask在任务符合性指标上取得了XX%的提升,在布局真实性指标上取得了YY%的提升(具体数值请参考原论文)。这些结果表明,MesaTask能够有效地生成符合任务要求且物理上合理的桌面场景。
🎯 应用场景
该研究成果可应用于机器人操作任务的训练和仿真,例如物体抓取、装配等。通过生成大量与特定任务相关的桌面场景,可以有效提高机器人的操作技能和泛化能力。此外,该技术还可以应用于虚拟现实和游戏开发等领域,用于生成逼真的3D场景。
📄 摘要(原文)
The ability of robots to interpret human instructions and execute manipulation tasks necessitates the availability of task-relevant tabletop scenes for training. However, traditional methods for creating these scenes rely on time-consuming manual layout design or purely randomized layouts, which are limited in terms of plausibility or alignment with the tasks. In this paper, we formulate a novel task, namely task-oriented tabletop scene generation, which poses significant challenges due to the substantial gap between high-level task instructions and the tabletop scenes. To support research on such a challenging task, we introduce MesaTask-10K, a large-scale dataset comprising approximately 10,700 synthetic tabletop scenes with manually crafted layouts that ensure realistic layouts and intricate inter-object relations. To bridge the gap between tasks and scenes, we propose a Spatial Reasoning Chain that decomposes the generation process into object inference, spatial interrelation reasoning, and scene graph construction for the final 3D layout. We present MesaTask, an LLM-based framework that utilizes this reasoning chain and is further enhanced with DPO algorithms to generate physically plausible tabletop scenes that align well with given task descriptions. Exhaustive experiments demonstrate the superior performance of MesaTask compared to baselines in generating task-conforming tabletop scenes with realistic layouts. Project page is at https://mesatask.github.io/