Lightweight Structured Multimodal Reasoning for Clinical Scene Understanding in Robotics
作者: Saurav Jha, Stefan K. Ehrlich
分类: cs.CV, cs.AI, cs.HC, cs.RO
发布日期: 2025-09-26
备注: 11 pages, 3 figures
💡 一句话要点
提出轻量级结构化多模态推理框架,用于机器人临床场景理解
🎯 匹配领域: 支柱三:空间感知与语义 (Perception & Semantics) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态推理 临床场景理解 医疗机器人 视觉-语言模型 链式思考 场景图 代理式框架
📋 核心要点
- 现有VLM在时间推理、不确定性估计和结构化输出方面存在局限,难以满足医疗机器人临床场景理解的需求。
- 论文提出一种轻量级代理式多模态框架,结合VLM与SmolAgent编排层,实现链式思考、语音-视觉融合和动态工具调用。
- 实验表明,该框架在准确性和鲁棒性上优于现有VLM,验证了其在医疗机器人领域的应用潜力。
📝 摘要(中文)
医疗机器人需要在动态临床环境中进行鲁棒的多模态感知和推理,以确保安全。现有的视觉-语言模型(VLMs)虽然展示了强大的通用能力,但在时间推理、不确定性估计以及机器人规划所需的结构化输出方面仍然存在局限性。本文提出了一种轻量级的、基于代理的多模态框架,用于基于视频的场景理解。该框架结合了Qwen2.5-VL-3B-Instruct模型与基于SmolAgent的编排层,支持链式思考推理、语音-视觉融合和动态工具调用。该框架生成结构化的场景图,并利用混合检索模块进行可解释和自适应的推理。在Video-MME基准测试和一个定制的临床数据集上的评估表明,与最先进的VLMs相比,该框架具有竞争力的准确性和更高的鲁棒性,证明了其在机器人辅助手术、患者监护和决策支持方面的潜力。
🔬 方法详解
问题定义:现有视觉-语言模型(VLMs)在医疗机器人临床场景理解中面临挑战,具体体现在时间推理能力不足,难以准确估计不确定性,并且无法生成机器人规划所需的结构化输出,例如场景图。这些局限性阻碍了VLMs在机器人辅助手术、患者监护等关键应用中的部署。
核心思路:论文的核心思路是构建一个轻量级的、基于代理的多模态推理框架,该框架能够利用大型语言模型(LLMs)的推理能力,同时克服其在特定任务上的局限性。通过引入一个编排层(基于SmolAgent),该框架可以支持链式思考推理、语音-视觉融合和动态工具调用,从而实现更鲁棒和可解释的场景理解。
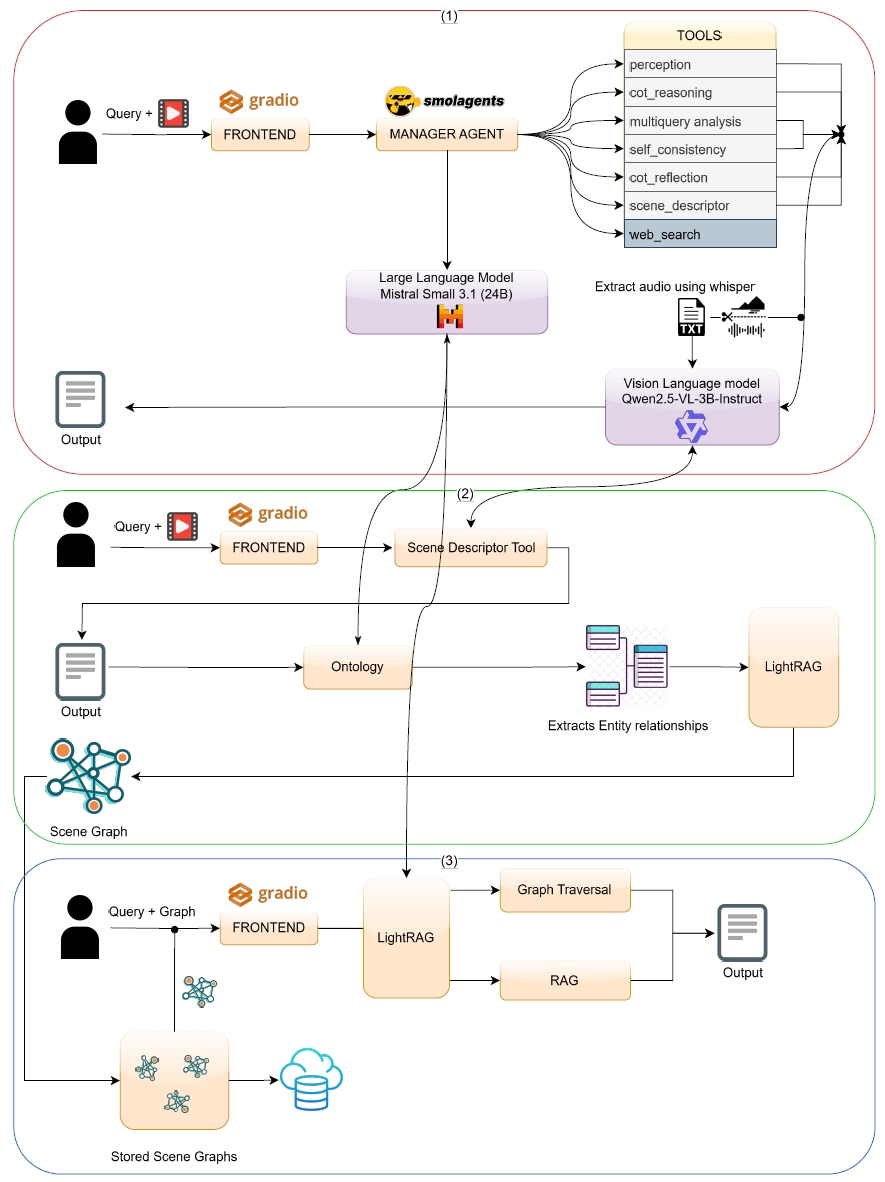
技术框架:该框架包含以下主要模块:1) 多模态输入模块,处理视频和语音数据;2) VLM(Qwen2.5-VL-3B-Instruct)作为基础模型,提取视觉和语言特征;3) 基于SmolAgent的编排层,负责任务分解、工具选择和结果整合;4) 混合检索模块,用于知识检索和辅助推理;5) 结构化场景图生成模块,将推理结果转化为结构化表示。整个流程包括:输入数据 -> VLM特征提取 -> SmolAgent任务规划 -> 工具调用(包括检索) -> 结果整合 -> 场景图生成。
关键创新:该论文的关键创新在于将大型语言模型与代理式框架相结合,实现了一种轻量级且可扩展的多模态推理方法。与传统的端到端VLM相比,该框架具有更强的模块化和可解释性,能够更好地适应复杂的临床场景。此外,混合检索模块的引入进一步提高了推理的准确性和鲁棒性。
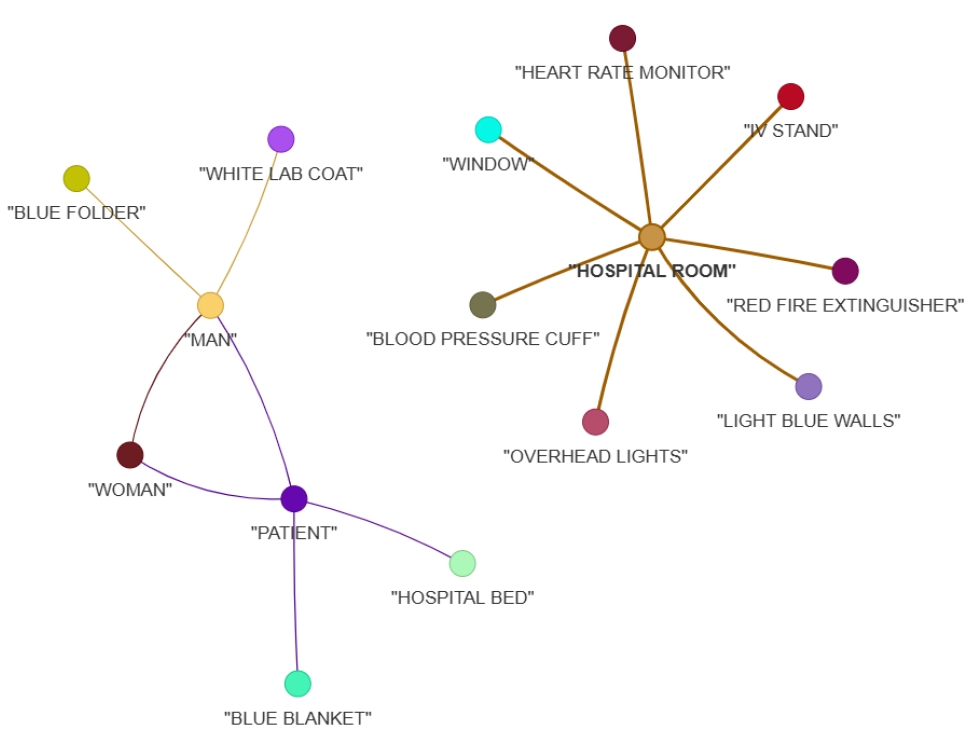
关键设计:Qwen2.5-VL-3B-Instruct模型作为视觉语言模型的基础,负责提取图像和文本特征。SmolAgent编排层使用预定义的工具集,例如知识库查询、目标检测等。混合检索模块结合了基于语义的检索和基于规则的检索,以提高检索的准确性。场景图的生成采用预定义的节点和边类型,以确保结构化输出的一致性。
🖼️ 关键图片
📊 实验亮点
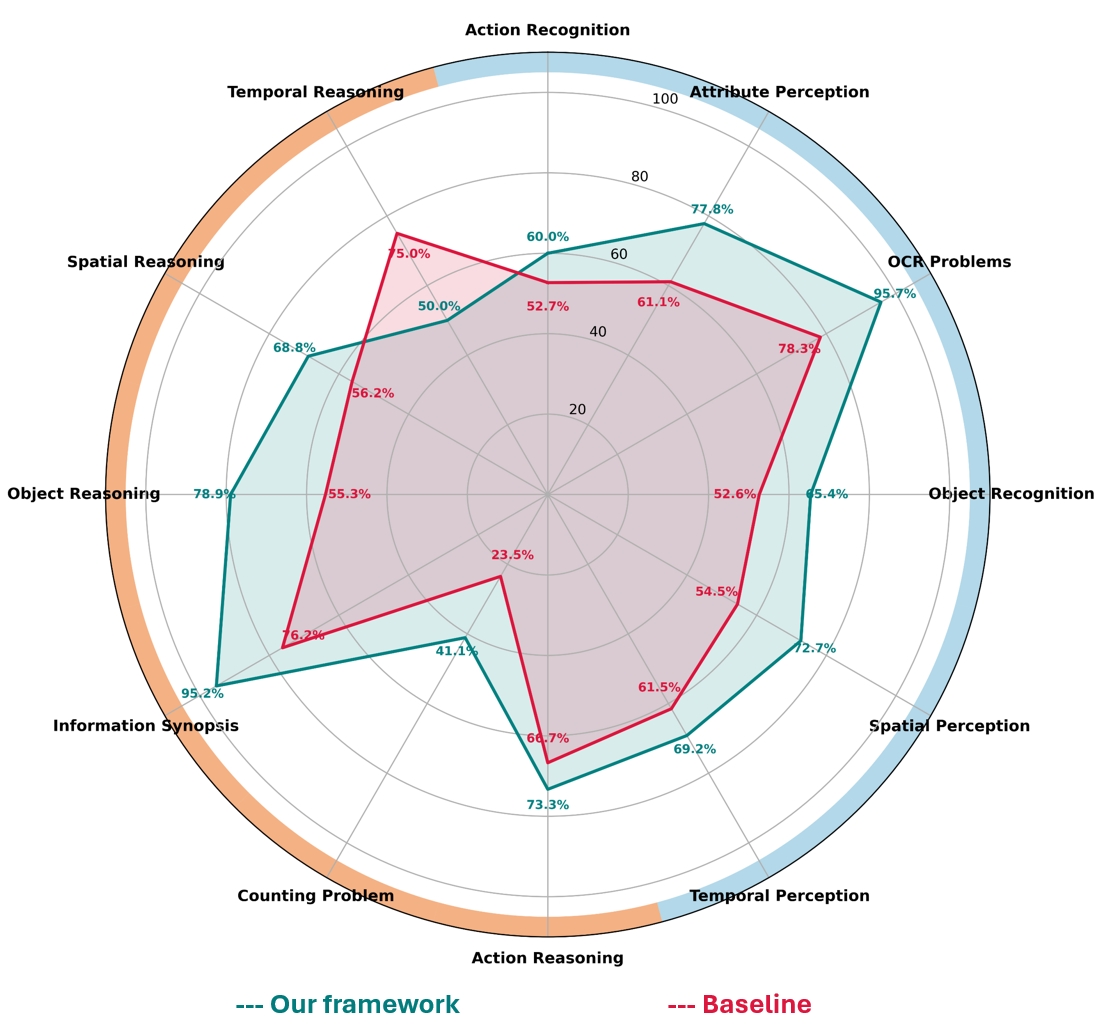
在Video-MME基准测试和定制的临床数据集上,该框架表现出与最先进的VLMs相当甚至更优的性能。实验结果表明,该框架在准确性和鲁棒性方面均有提升,尤其是在处理复杂和不确定性较高的临床场景时。具体性能数据(例如准确率、召回率等)在摘要中未明确给出,属于未知信息。
🎯 应用场景
该研究成果可应用于机器人辅助手术,通过实时场景理解辅助医生进行手术决策;在患者监护方面,可用于监测患者状态并及时发出警报;在临床决策支持方面,可为医生提供更全面、准确的患者信息,辅助诊断和治疗方案制定。该框架的轻量级设计使其易于部署在资源受限的医疗环境中,具有广阔的应用前景。
📄 摘要(原文)
Healthcare robotics requires robust multimodal perception and reasoning to ensure safety in dynamic clinical environments. Current Vision-Language Models (VLMs) demonstrate strong general-purpose capabilities but remain limited in temporal reasoning, uncertainty estimation, and structured outputs needed for robotic planning. We present a lightweight agentic multimodal framework for video-based scene understanding. Combining the Qwen2.5-VL-3B-Instruct model with a SmolAgent-based orchestration layer, it supports chain-of-thought reasoning, speech-vision fusion, and dynamic tool invocation. The framework generates structured scene graphs and leverages a hybrid retrieval module for interpretable and adaptive reasoning. Evaluations on the Video-MME benchmark and a custom clinical dataset show competitive accuracy and improved robustness compared to state-of-the-art VLMs, demonstrating its potential for applications in robot-assisted surgery, patient monitoring, and decision support.