ERGO: Efficient High-Resolution Visual Understanding for Vision-Language Models
作者: Jewon Lee, Wooksu Shin, Seungmin Yang, Ki-Ung Song, DongUk Lim, Jaeyeon Kim, Tae-Ho Kim, Bo-Kyeong Kim
分类: cs.CV, cs.AI, cs.CL, cs.LG
发布日期: 2025-09-26
🔗 代码/项目: GITHUB
💡 一句话要点
提出ERGO,通过高效高分辨率视觉理解提升视觉-语言模型性能
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 视觉-语言模型 高分辨率图像 高效推理 强化学习 多模态融合 区域选择 由粗到精
📋 核心要点
- 现有LVLMs处理高分辨率图像时,由于视觉tokens数量庞大,计算开销显著,限制了实际应用。
- ERGO采用两阶段“由粗到精”推理,先识别任务相关区域,再以全分辨率处理,降低计算成本并保留细节。
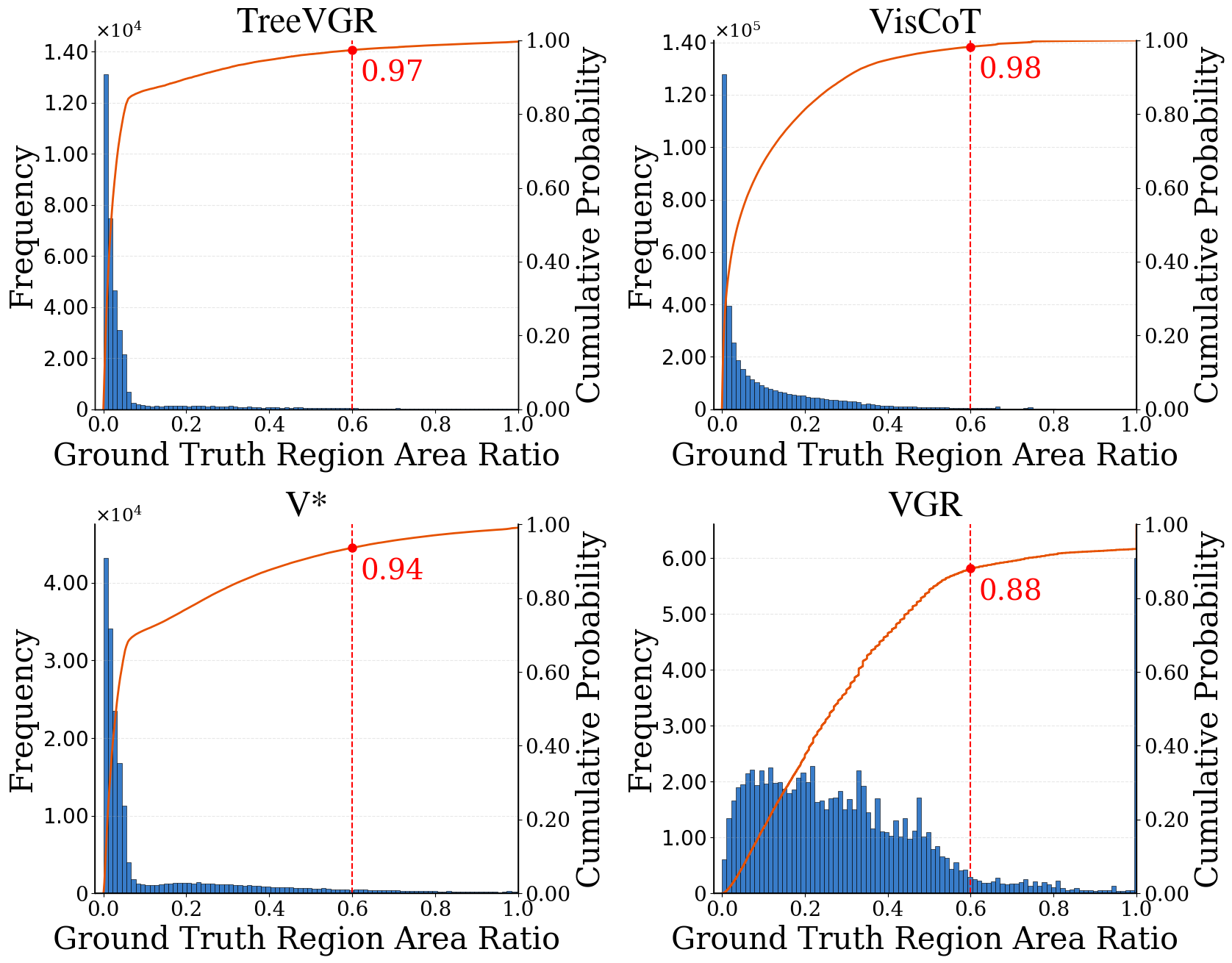
- ERGO利用多模态上下文进行推理驱动的感知,解决下采样图像中感知不确定性问题,提升模型准确性和效率。
📝 摘要(中文)
为了在实际视觉-语言应用中高效处理高分辨率图像,现有大型视觉-语言模型(LVLMs)由于大量的视觉tokens而产生巨大的计算开销。随着“用图像思考”模型的出现,推理现在超越了文本领域,扩展到视觉领域。本文提出了一种两阶段“由粗到精”的推理流程:首先,分析下采样图像以识别与任务相关的区域;然后,仅裁剪这些区域并以全分辨率在后续推理阶段处理。这种方法降低了计算成本,同时在必要时保留了细粒度的视觉细节。主要的挑战在于推断哪些区域与给定的查询真正相关。最近的相关方法在输入图像下采样后的第一阶段经常失败,这是由于感知驱动的推理,需要清晰的视觉信息才能进行有效的推理。为了解决这个问题,本文提出了ERGO(高效推理与引导观察),它执行推理驱动的感知,利用多模态上下文来确定关注的位置。ERGO模型可以考虑感知不确定性,扩大裁剪区域以覆盖视觉上模糊的区域,从而回答问题。为此,本文在强化学习框架中开发了简单而有效的奖励组件,用于由粗到精的感知。在多个数据集上,ERGO方法比原始模型和竞争方法提供更高的准确性,并具有更高的效率。例如,ERGO在V*基准测试中超过Qwen2.5-VL-7B 4.7个点,同时仅使用23%的视觉tokens,实现了3倍的推理加速。代码和模型可在https://github.com/nota-github/ERGO找到。
🔬 方法详解
问题定义:现有大型视觉-语言模型在处理高分辨率图像时,需要处理大量的视觉tokens,导致计算成本过高,推理速度慢,难以满足实际应用的需求。尤其是在需要细粒度视觉信息的任务中,全局处理高分辨率图像的效率非常低。
核心思路:ERGO的核心思路是只关注图像中与任务相关的区域,避免对整个高分辨率图像进行处理。通过一个“由粗到精”的两阶段流程,首先快速识别出可能包含答案的区域,然后只对这些区域进行高分辨率的详细分析。这种选择性关注的方式可以显著减少计算量,提高推理速度。
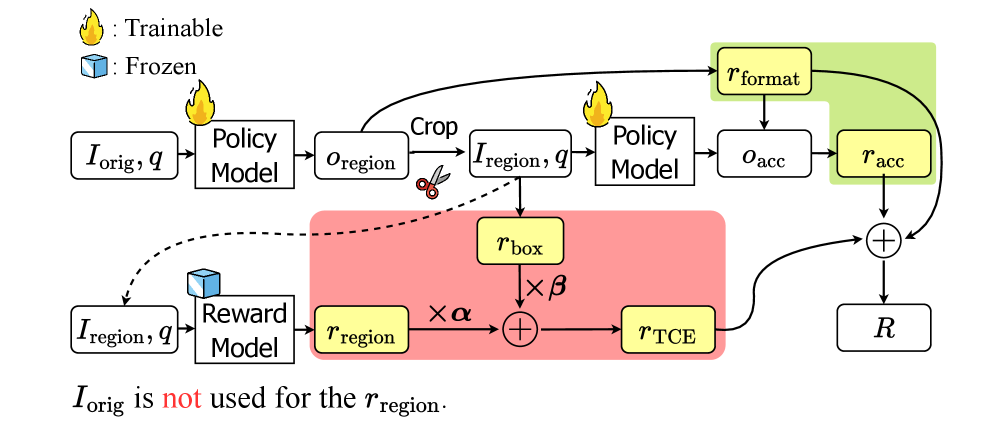
技术框架:ERGO包含两个主要阶段:粗略推理阶段和精细推理阶段。在粗略推理阶段,模型接收下采样后的图像和文本查询,利用多模态信息识别出可能包含答案的区域。这个阶段使用强化学习框架,通过奖励机制引导模型关注相关区域。在精细推理阶段,模型将粗略推理阶段识别出的区域裁剪出来,并以全分辨率进行处理,最终给出答案。
关键创新:ERGO的关键创新在于其推理驱动的感知机制。与传统的感知驱动的推理不同,ERGO首先进行粗略的推理,然后根据推理结果来指导对图像的感知。这种方式可以有效地利用多模态信息,克服下采样图像带来的感知不确定性,从而更准确地识别出与任务相关的区域。
关键设计:ERGO使用强化学习来训练粗略推理阶段的区域选择策略。奖励函数包含多个组成部分,包括准确性奖励、效率奖励和覆盖率奖励。准确性奖励鼓励模型选择包含正确答案的区域,效率奖励鼓励模型选择尽可能小的区域,覆盖率奖励则鼓励模型在存在感知不确定性时扩大选择区域。此外,ERGO还使用了多模态上下文信息,包括文本查询和视觉特征,来提高区域选择的准确性。
🖼️ 关键图片

📊 实验亮点
ERGO在多个数据集上取得了显著的性能提升。例如,在V*基准测试中,ERGO超过Qwen2.5-VL-7B 4.7个点,同时仅使用23%的视觉tokens,实现了3倍的推理加速。这些结果表明,ERGO在提高模型准确性和效率方面具有显著优势。
🎯 应用场景
ERGO适用于需要处理高分辨率图像的视觉-语言任务,例如视觉问答、图像描述、目标检测等。其高效的推理能力使其在资源受限的设备上也能运行复杂的视觉-语言模型,具有广泛的应用前景。未来可应用于智能助手、自动驾驶、医疗诊断等领域。
📄 摘要(原文)
Efficient processing of high-resolution images is crucial for real-world vision-language applications. However, existing Large Vision-Language Models (LVLMs) incur substantial computational overhead due to the large number of vision tokens. With the advent of "thinking with images" models, reasoning now extends beyond text to the visual domain. This capability motivates our two-stage "coarse-to-fine" reasoning pipeline: first, a downsampled image is analyzed to identify task-relevant regions; then, only these regions are cropped at full resolution and processed in a subsequent reasoning stage. This approach reduces computational cost while preserving fine-grained visual details where necessary. A major challenge lies in inferring which regions are truly relevant to a given query. Recent related methods often fail in the first stage after input-image downsampling, due to perception-driven reasoning, where clear visual information is required for effective reasoning. To address this issue, we propose ERGO (Efficient Reasoning & Guided Observation) that performs reasoning-driven perception-leveraging multimodal context to determine where to focus. Our model can account for perceptual uncertainty, expanding the cropped region to cover visually ambiguous areas for answering questions. To this end, we develop simple yet effective reward components in a reinforcement learning framework for coarse-to-fine perception. Across multiple datasets, our approach delivers higher accuracy than the original model and competitive methods, with greater efficiency. For instance, ERGO surpasses Qwen2.5-VL-7B on the V* benchmark by 4.7 points while using only 23% of the vision tokens, achieving a 3x inference speedup. The code and models can be found at: https://github.com/nota-github/ERGO.