Large Pre-Trained Models for Bimanual Manipulation in 3D
作者: Hanna Yurchyk, Wei-Di Chang, Gregory Dudek, David Meger
分类: cs.CV, cs.LG, cs.RO
发布日期: 2025-09-24
备注: Accepted to 2025 IEEE-RAS 24th International Conference on Humanoid Robots
DOI: 10.1109/Humanoids65713.2025.11203079
💡 一句话要点
提出基于视觉变换器的注意力图以增强双手机器人操作
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱二:RL算法与架构 (RL & Architecture)
关键词: 双手操作 视觉变换器 注意力机制 体素表示 行为克隆 机器人技术 自监督学习
📋 核心要点
- 现有的双手机器人操作方法在处理复杂场景时,往往缺乏有效的视觉特征提取,导致性能不足。
- 本文提出通过将DINOv2模型的注意力图与体素表示结合,提升双手操作的语义理解能力。
- 实验结果表明,所提出的方法在RLBench基准测试中相较于现有策略有显著提升,平均绝对提升8.2%。
📝 摘要(中文)
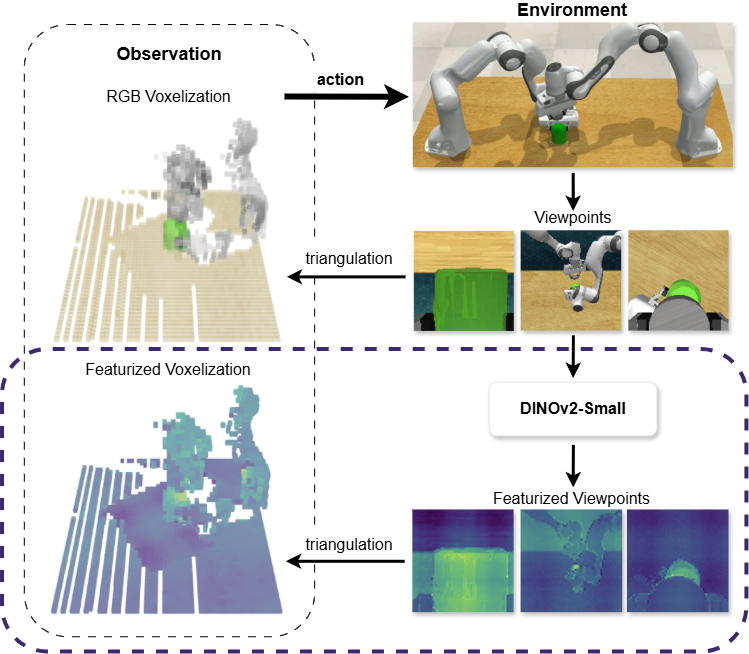
本文研究了将预训练的视觉变换器中的注意力图与体素表示相结合,以提升双手机器人操作的能力。具体而言,我们从自监督的DINOv2模型中提取注意力图,并将其解释为RGB图像上的像素级显著性分数。这些图被提升到3D体素网格中,形成体素级语义线索,并融入行为克隆策略中。在与最先进的体素基础策略结合后,我们的注意力引导特征化在RLBench双手基准测试中实现了平均绝对提升8.2%和相对增益21.9%。
🔬 方法详解
问题定义:本文旨在解决双手机器人在复杂操作场景中对视觉特征提取不足的问题,现有方法在处理多样化任务时表现不佳。
核心思路:通过提取DINOv2模型中的注意力图,将其作为像素级显著性分数,并将其提升至3D体素网格中,以增强语义信息的表达。
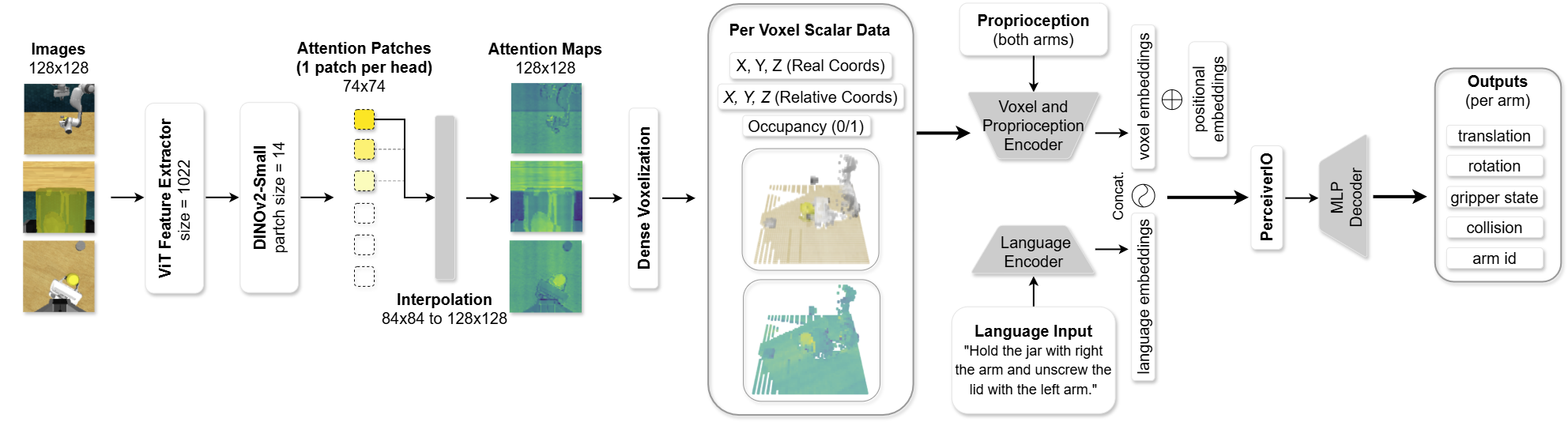
技术框架:整体架构包括三个主要模块:首先是从DINOv2提取注意力图,其次是将注意力图映射到3D体素网格,最后将生成的体素特征融入行为克隆策略中。
关键创新:本研究的创新点在于将视觉变换器的注意力机制与体素表示相结合,形成了一种新的特征提取方式,相较于传统方法具有更强的语义理解能力。
关键设计:在参数设置上,注意力图的分辨率与体素网格的大小相匹配,损失函数采用了行为克隆的标准损失,网络结构则基于DINOv2的预训练模型进行微调。
🖼️ 关键图片
📊 实验亮点
实验结果显示,所提出的注意力引导特征化方法在RLBench双手基准测试中实现了平均绝对提升8.2%,相对增益达到21.9%。这一显著提升表明了该方法在双手操作任务中的有效性,超越了现有的最先进策略。
🎯 应用场景
该研究的潜在应用领域包括机器人抓取、装配和服务等多种双手操作任务。通过提升机器人对环境的理解能力,可以显著提高其在复杂场景中的操作效率和准确性,未来可能在工业自动化和家庭服务机器人等领域产生深远影响。
📄 摘要(原文)
We investigate the integration of attention maps from a pre-trained Vision Transformer into voxel representations to enhance bimanual robotic manipulation. Specifically, we extract attention maps from DINOv2, a self-supervised ViT model, and interpret them as pixel-level saliency scores over RGB images. These maps are lifted into a 3D voxel grid, resulting in voxel-level semantic cues that are incorporated into a behavior cloning policy. When integrated into a state-of-the-art voxel-based policy, our attention-guided featurization yields an average absolute improvement of 8.2% and a relative gain of 21.9% across all tasks in the RLBench bimanual benchmark.