Hyperspectral Adapter for Semantic Segmentation with Vision Foundation Models
作者: Juana Valeria Hurtado, Rohit Mohan, Abhinav Valada
分类: cs.CV, cs.AI, cs.LG, cs.RO
发布日期: 2025-09-24 (更新: 2025-09-25)
💡 一句话要点
提出高光谱适配器,利用视觉基础模型提升高光谱图像语义分割性能
🎯 匹配领域: 支柱五:交互与反应 (Interaction & Reaction) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 高光谱图像 语义分割 视觉基础模型 Transformer 模态融合 自动驾驶 机器人感知
📋 核心要点
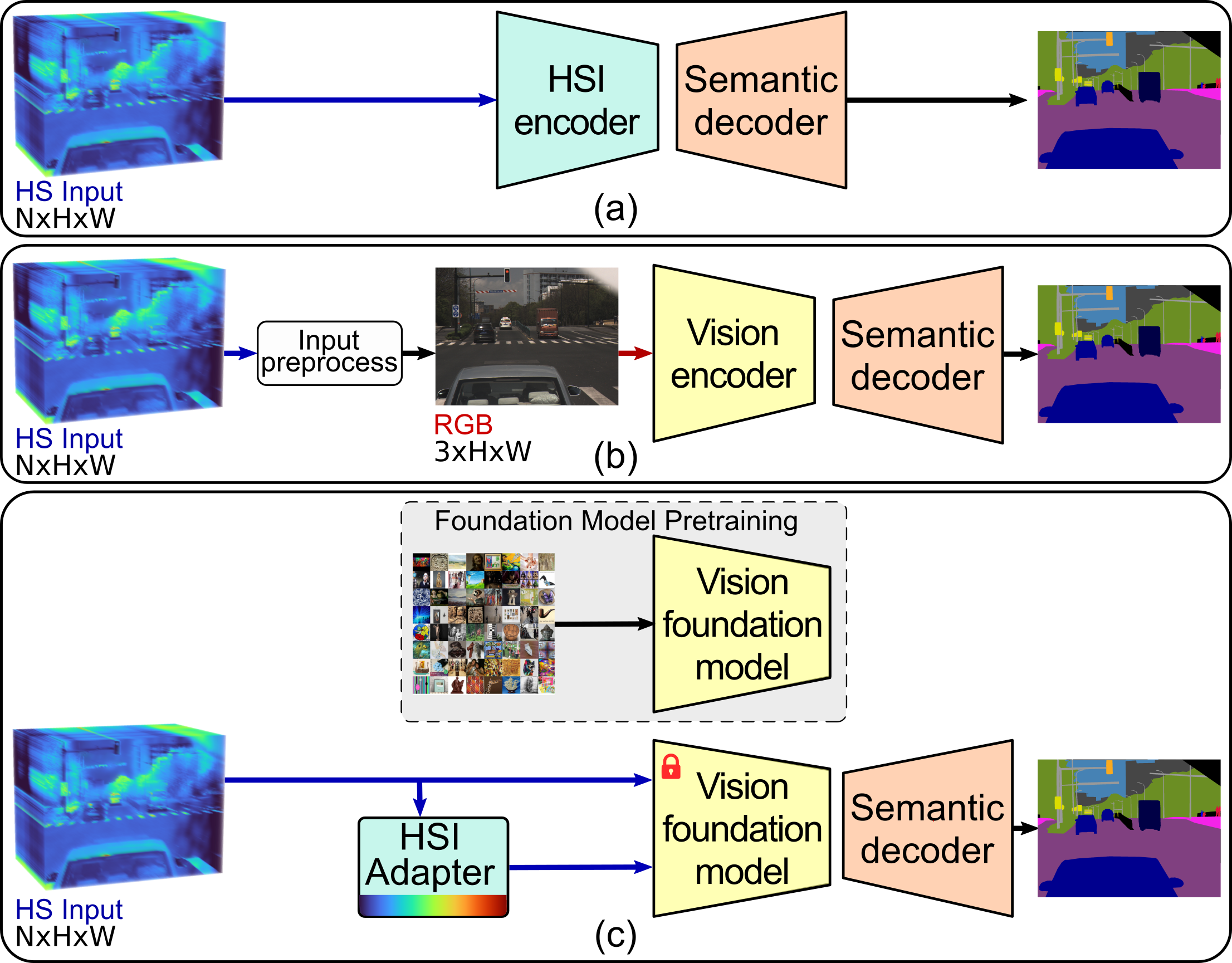
- 现有高光谱语义分割方法依赖为RGB图像设计的架构,无法充分利用高光谱数据的丰富光谱信息。
- 提出一种高光谱适配器,利用预训练的视觉基础模型,结合光谱Transformer和空间先验模块提取空间-光谱特征。
- 在自动驾驶数据集上的实验表明,该方法在直接使用高光谱输入时,达到了最先进的语义分割性能。
📝 摘要(中文)
高光谱成像(HSI)捕获空间信息以及跨多个窄波段的密集光谱测量。这种丰富的光谱内容有潜力促进稳健的机器人感知,尤其是在具有复杂材料成分、变化的光照或其他视觉挑战性条件的环境中。然而,当前的高光谱语义分割方法由于依赖于针对RGB输入优化的架构和学习框架而表现不佳。在这项工作中,我们提出了一种新的高光谱适配器,它利用预训练的视觉基础模型来有效地从高光谱数据中学习。我们的架构包含一个光谱Transformer和一个频谱感知空间先验模块,以提取丰富的空间-光谱特征。此外,我们引入了一个模态感知交互块,通过专用的提取和注入机制,促进高光谱表示和冻结的视觉Transformer特征的有效集成。在三个基准自动驾驶数据集上的广泛评估表明,我们的架构实现了最先进的语义分割性能,同时直接使用HSI输入,优于基于视觉和高光谱的分割方法。代码可在https://hsi-adapter.cs.uni-freiburg.de获取。
🔬 方法详解
问题定义:现有高光谱语义分割方法通常直接采用为RGB图像设计的网络结构,忽略了高光谱数据特有的丰富光谱信息。这些方法无法有效提取和利用高光谱数据的空间-光谱联合特征,导致分割精度受限。此外,从头训练深度高光谱分割模型需要大量标注数据,成本高昂。
核心思路:论文的核心思路是利用预训练的视觉基础模型强大的特征提取能力,并设计专门的适配器模块来桥接视觉模型和高光谱数据之间的差异。通过这种方式,可以有效利用高光谱数据的光谱信息,同时避免从头训练大型模型,降低了训练成本。
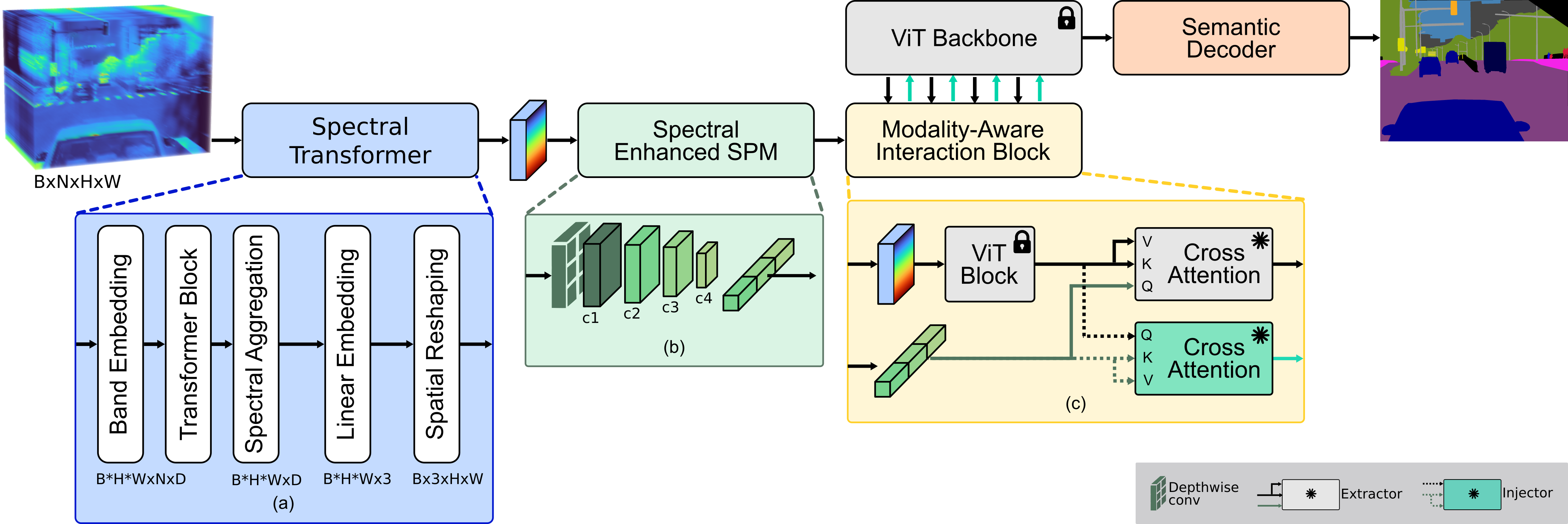
技术框架:整体架构包含三个主要模块:1) 光谱Transformer:用于提取高光谱数据的光谱特征。2) 频谱感知空间先验模块:用于提取空间信息,并结合光谱信息形成空间-光谱特征。3) 模态感知交互块:用于融合高光谱特征和预训练视觉Transformer的特征。整个流程是先分别提取高光谱数据的光谱和空间特征,然后通过交互块与视觉特征融合,最后进行语义分割。
关键创新:最重要的技术创新点在于模态感知交互块的设计。该模块通过专用的提取和注入机制,实现了高光谱特征和视觉特征的有效融合。与简单的特征拼接或加权融合相比,该模块能够更好地利用两种模态的信息,提升分割性能。
关键设计:光谱Transformer采用标准的Transformer结构,输入是高光谱数据的光谱向量。频谱感知空间先验模块利用卷积神经网络提取空间特征,并使用注意力机制将空间特征与光谱特征融合。模态感知交互块包含提取模块和注入模块,分别用于提取高光谱特征和视觉特征,然后通过交叉注意力机制进行融合。
🖼️ 关键图片
📊 实验亮点
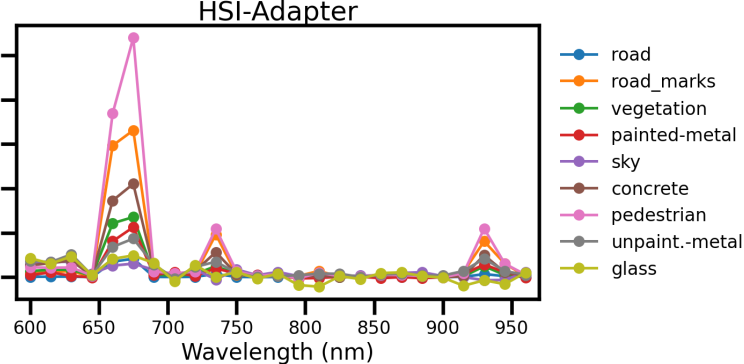
该方法在三个自动驾驶数据集上取得了state-of-the-art的语义分割性能,超越了现有的基于视觉和高光谱的分割方法。实验结果表明,该方法能够有效利用高光谱数据的光谱信息,并与预训练的视觉特征进行有效融合,从而显著提升分割精度。具体性能提升幅度未知,需查阅论文原文。
🎯 应用场景
该研究成果可应用于自动驾驶、遥感图像分析、农业监测、环境监测等领域。通过高光谱图像的语义分割,可以实现对复杂场景的精确理解,例如识别道路、植被、建筑物等,从而为机器人导航、资源管理和环境评估提供支持。未来,该技术有望在更多领域得到应用,例如医疗诊断、食品安全检测等。
📄 摘要(原文)
Hyperspectral imaging (HSI) captures spatial information along with dense spectral measurements across numerous narrow wavelength bands. This rich spectral content has the potential to facilitate robust robotic perception, particularly in environments with complex material compositions, varying illumination, or other visually challenging conditions. However, current HSI semantic segmentation methods underperform due to their reliance on architectures and learning frameworks optimized for RGB inputs. In this work, we propose a novel hyperspectral adapter that leverages pretrained vision foundation models to effectively learn from hyperspectral data. Our architecture incorporates a spectral transformer and a spectrum-aware spatial prior module to extract rich spatial-spectral features. Additionally, we introduce a modality-aware interaction block that facilitates effective integration of hyperspectral representations and frozen vision Transformer features through dedicated extraction and injection mechanisms. Extensive evaluations on three benchmark autonomous driving datasets demonstrate that our architecture achieves state-of-the-art semantic segmentation performance while directly using HSI inputs, outperforming both vision-based and hyperspectral segmentation methods. We make the code available at https://hsi-adapter.cs.uni-freiburg.de.