Event-guided 3D Gaussian Splatting for Dynamic Human and Scene Reconstruction
作者: Xiaoting Yin, Hao Shi, Kailun Yang, Jiajun Zhai, Shangwei Guo, Lin Wang, Kaiwei Wang
分类: cs.CV, cs.RO, eess.IV
发布日期: 2025-09-23
💡 一句话要点
提出事件相机引导的3D高斯溅射方法,用于动态人体和场景重建
🎯 匹配领域: 支柱三:空间感知与语义 (Perception & Semantics)
关键词: 事件相机 3D高斯溅射 动态重建 人体建模 场景重建 运动模糊 单目视觉
📋 核心要点
- 单目视频重建动态人体和静态场景面临运动模糊挑战,尤其是在快速运动下,RGB帧质量下降。
- 利用事件相机的高时间分辨率优势,提出基于3D高斯溅射的事件引导人体-场景联合重建框架。
- 通过事件引导的损失函数优化,提升快速运动区域的重建质量,并在基准数据集上取得显著性能提升。
📝 摘要(中文)
本文提出了一种新颖的事件引导的人体-场景重建框架,该框架通过3D高斯溅射从单个单目事件相机联合建模人体和场景。具体来说,统一的3D高斯集合携带可学习的语义属性;只有被分类为人体的那些高斯进行形变以用于动画,而场景高斯保持静态。为了对抗模糊,我们提出了一种事件引导的损失,该损失将连续渲染之间的模拟亮度变化与事件流进行匹配,从而提高了快速移动区域的局部保真度。我们的方法无需外部人体掩模,并简化了管理单独高斯集合的过程。在两个基准数据集ZJU-MoCap-Blur和MMHPSD-Blur上,它提供了最先进的人体-场景重建,与强大的基线相比,在PSNR/SSIM方面有显著提高,并降低了LPIPS,尤其是在高速运动对象上。
🔬 方法详解
问题定义:现有方法在单目视频中重建动态人体和静态场景时,尤其是在快速运动场景下,容易受到运动模糊的影响,导致重建质量下降。传统方法可能需要额外的人体掩模或分别管理人体和场景的高斯集合,增加了复杂性。
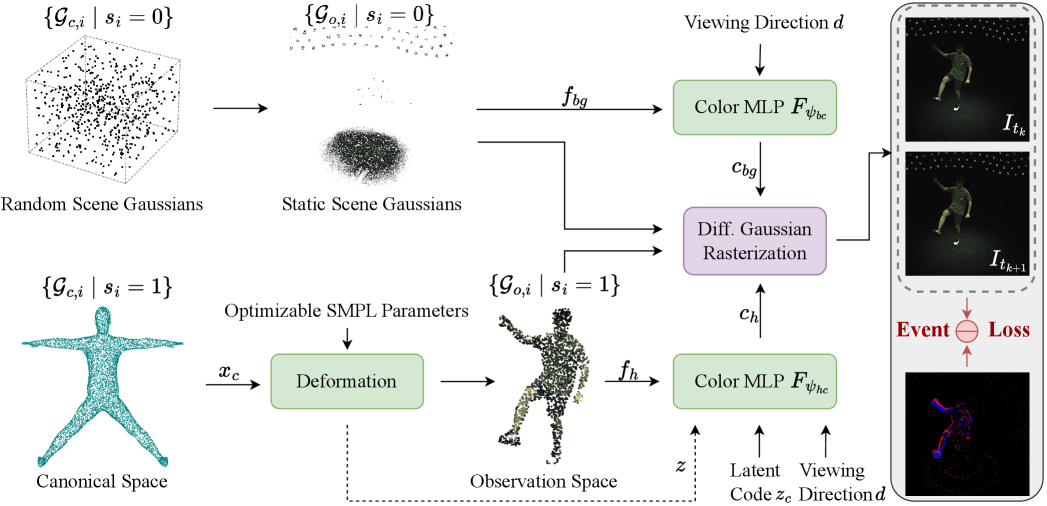
核心思路:本文的核心思路是利用事件相机的高时间分辨率特性,通过事件流引导3D高斯溅射的优化过程,从而减轻运动模糊的影响。同时,采用统一的3D高斯集合来表示人体和场景,并通过可学习的语义属性区分两者,简化了管理过程。
技术框架:该框架主要包含以下几个模块:1) 使用统一的3D高斯集合表示场景和人体,每个高斯携带可学习的语义属性。2) 根据语义属性将高斯分为人体和场景两部分,人体高斯进行形变以用于动画,场景高斯保持静态。3) 提出事件引导的损失函数,该损失函数将连续渲染之间的模拟亮度变化与事件流进行匹配,从而优化高斯参数。4) 通过优化后的高斯参数,渲染出高质量的人体-场景重建结果。
关键创新:最重要的技术创新点在于事件引导的损失函数,它利用事件相机提供的高时间分辨率信息,有效地减轻了运动模糊对重建质量的影响。与现有方法相比,该方法无需外部人体掩模,并简化了人体和场景的管理。
关键设计:事件引导的损失函数是关键设计之一,它通过最小化模拟亮度变化与事件流之间的差异来优化高斯参数。具体的实现细节包括:1) 计算连续渲染帧之间的亮度变化。2) 将亮度变化与事件流进行对齐。3) 使用对齐后的亮度变化和事件流计算损失值。此外,可学习的语义属性也是一个关键设计,它允许框架自动区分人体和场景,从而简化了管理过程。
🖼️ 关键图片


📊 实验亮点
在ZJU-MoCap-Blur和MMHPSD-Blur两个基准数据集上,该方法取得了state-of-the-art的性能。与现有方法相比,在PSNR/SSIM指标上取得了显著提升,并降低了LPIPS指标,尤其是在高速运动对象上,性能提升更为明显。实验结果表明,该方法能够有效地减轻运动模糊的影响,并重建出高质量的人体和场景。
🎯 应用场景
该研究成果可应用于虚拟现实、增强现实、游戏开发、运动分析等领域。例如,可以用于创建更逼真的虚拟人物,或者用于分析运动员的运动姿态。此外,该技术还可以应用于机器人导航和场景理解等领域,帮助机器人更好地理解周围环境。
📄 摘要(原文)
Reconstructing dynamic humans together with static scenes from monocular videos remains difficult, especially under fast motion, where RGB frames suffer from motion blur. Event cameras exhibit distinct advantages, e.g., microsecond temporal resolution, making them a superior sensing choice for dynamic human reconstruction. Accordingly, we present a novel event-guided human-scene reconstruction framework that jointly models human and scene from a single monocular event camera via 3D Gaussian Splatting. Specifically, a unified set of 3D Gaussians carries a learnable semantic attribute; only Gaussians classified as human undergo deformation for animation, while scene Gaussians stay static. To combat blur, we propose an event-guided loss that matches simulated brightness changes between consecutive renderings with the event stream, improving local fidelity in fast-moving regions. Our approach removes the need for external human masks and simplifies managing separate Gaussian sets. On two benchmark datasets, ZJU-MoCap-Blur and MMHPSD-Blur, it delivers state-of-the-art human-scene reconstruction, with notable gains over strong baselines in PSNR/SSIM and reduced LPIPS, especially for high-speed subjects.