MDF-MLLM: Deep Fusion Through Cross-Modal Feature Alignment for Contextually Aware Fundoscopic Image Classification
作者: Jason Jordan, Mohammadreza Akbari Lor, Peter Koulen, Mei-Ling Shyu, Shu-Ching Chen
分类: cs.CV, cs.AI
发布日期: 2025-09-21
备注: Word count: 5157, Table count: 2, Figure count: 5
💡 一句话要点
提出MDF-MLLM以解决视网膜图像分类准确性不足问题
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态融合 深度学习 视网膜图像 疾病分类 交叉注意力 U-Net 临床决策支持 特征融合
📋 核心要点
- 现有的多模态大语言模型在视网膜图像分类中难以捕捉低级空间细节,导致准确性不足。
- MDF-MLLM通过多层次特征融合和交叉注意力机制,整合图像和文本信息,从而提升分类性能。
- 实验结果显示,MDF-MLLM在分类任务中准确率达到94%,较基线提升56%,F1分数提升35%。
📝 摘要(中文)
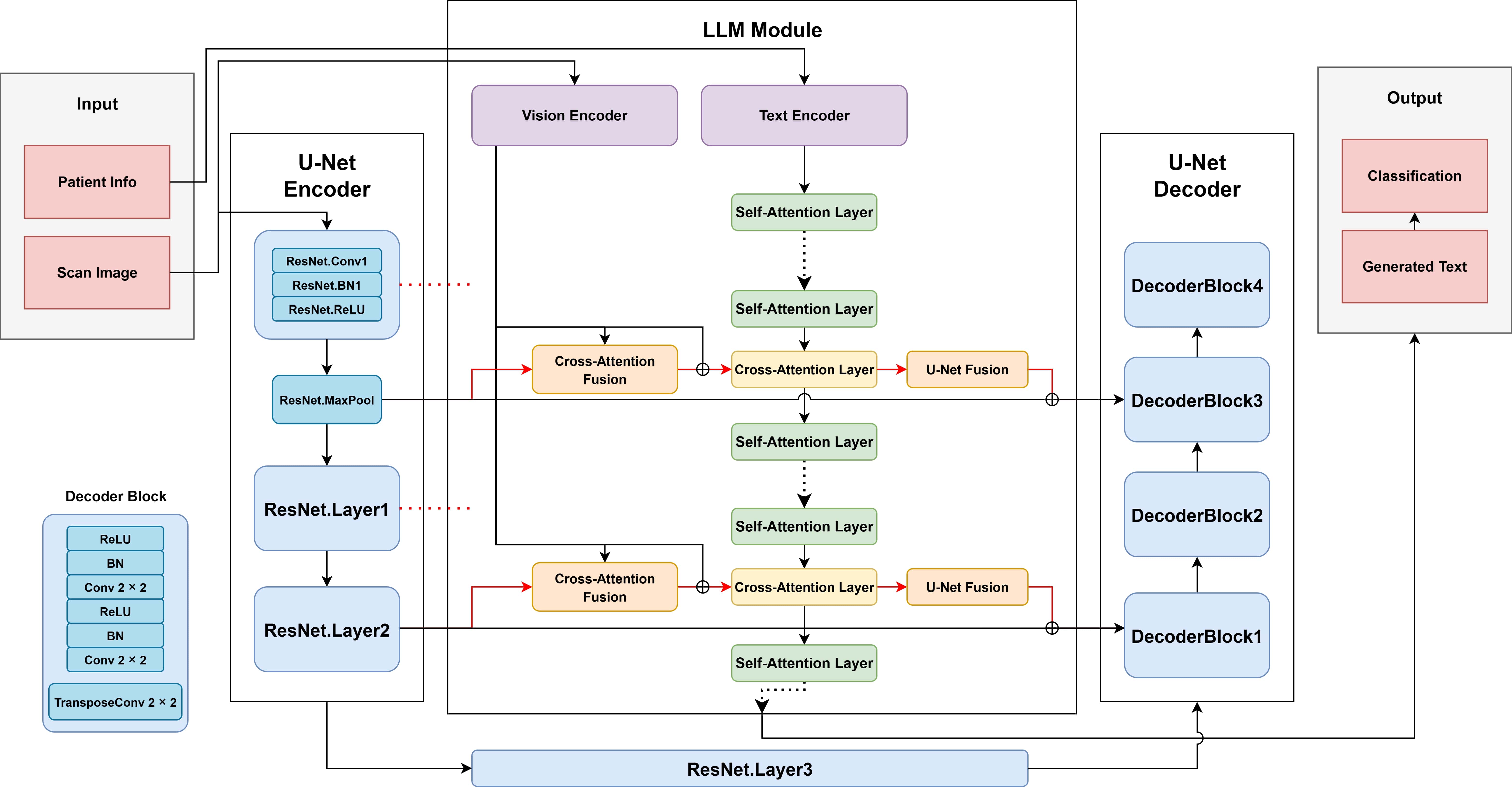
本研究旨在通过整合细粒度图像特征和全局文本上下文,提升视网膜图像的疾病分类准确性,采用了一种新颖的多模态深度学习架构。现有的多模态大语言模型(MLLM)在捕捉诊断视网膜疾病(如青光眼、糖尿病视网膜病变和色素性视网膜炎)所需的低级空间细节方面存在困难。该模型在1305对视网膜图像-文本对上进行开发和验证,使用分类准确率和F1分数进行评估。MDF-MLLM通过将四个U-Net编码器层的跳跃特征集成到LLaMA 3.2 11B MLLM的交叉注意力块中,显著提高了分类准确率,从基线的60%提升至94%。
🔬 方法详解
问题定义:本研究旨在解决现有多模态大语言模型在视网膜图像分类中无法有效捕捉低级空间细节的问题,这限制了对视网膜疾病的准确诊断。
核心思路:MDF-MLLM通过将细粒度图像特征与全局文本上下文相结合,利用多层次特征融合和交叉注意力机制,增强了模型对视网膜图像的理解能力。
技术框架:该架构主要包括四个U-Net编码器层的跳跃特征集成、交叉注意力块和LLaMA 3.2 11B MLLM。图像特征通过分块投影并使用缩放交叉注意力和FiLM基础的U-Net调制进行融合。
关键创新:MDF-MLLM的多深度融合方法显著提升了空间推理和分类能力,尤其在处理富含临床文本的遗传性疾病时表现突出,超越了传统的MLLM基线。
关键设计:模型在训练过程中对U-Net和MLLM组件进行了全面微调,采用了适当的损失函数和网络结构设计,以确保在分类任务中的高效性能。
🖼️ 关键图片

📊 实验亮点
MDF-MLLM在双类型疾病分类任务中取得了94%的准确率,相较于基线模型的60%提升了56%。此外,召回率和F1分数分别提高了67%和35%,显示出显著的性能改进。
🎯 应用场景
MDF-MLLM在临床决策支持系统中具有广泛的应用潜力,能够帮助医生更准确地诊断视网膜疾病,从而提高患者的治疗效果。未来,该模型还可以扩展到更多疾病的分类和图像分割任务,进一步提升其临床实用性。
📄 摘要(原文)
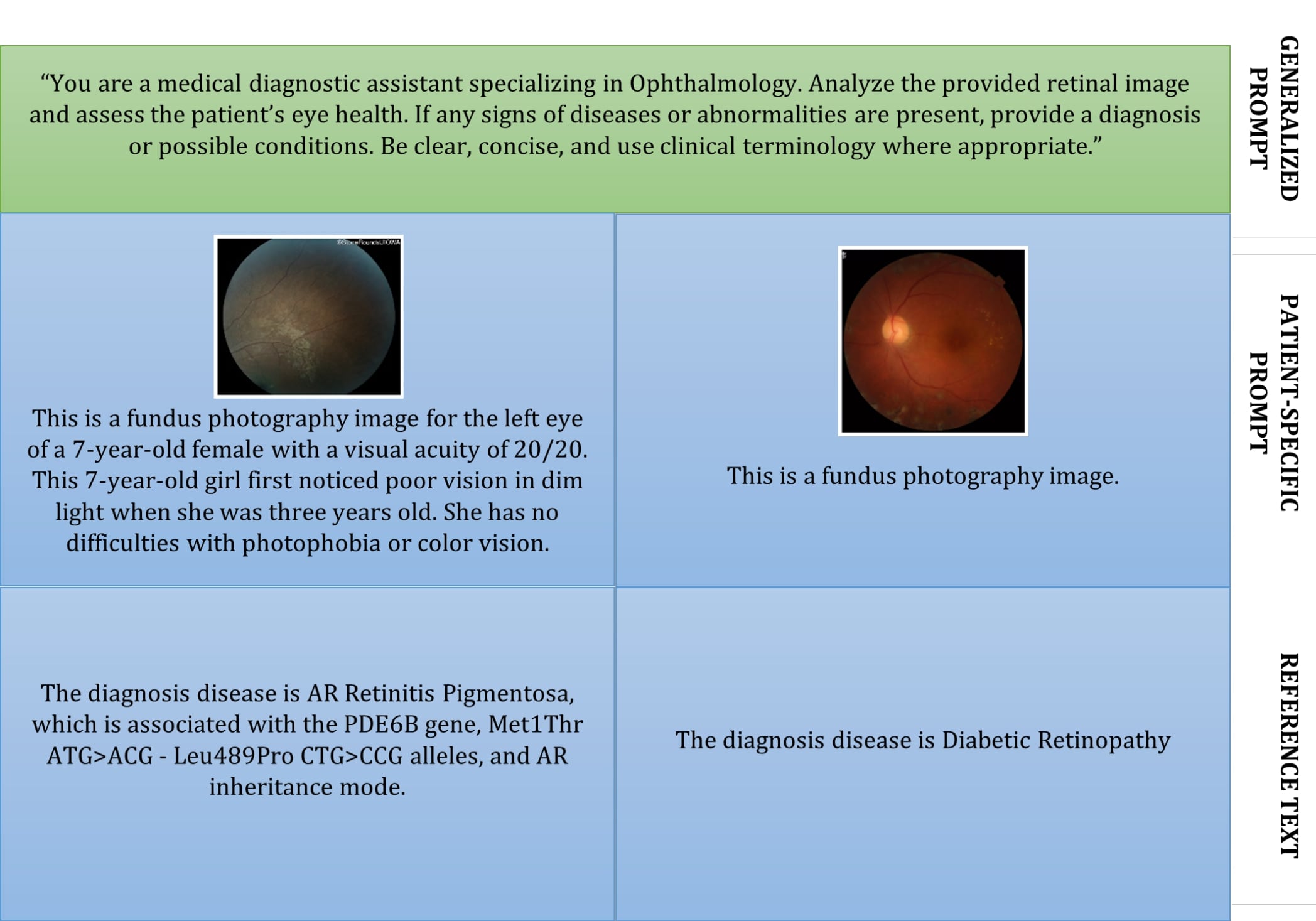
This study aimed to enhance disease classification accuracy from retinal fundus images by integrating fine-grained image features and global textual context using a novel multimodal deep learning architecture. Existing multimodal large language models (MLLMs) often struggle to capture low-level spatial details critical for diagnosing retinal diseases such as glaucoma, diabetic retinopathy, and retinitis pigmentosa. This model development and validation study was conducted on 1,305 fundus image-text pairs compiled from three public datasets (FIVES, HRF, and StoneRounds), covering acquired and inherited retinal diseases, and evaluated using classification accuracy and F1-score. The MDF-MLLM integrates skip features from four U-Net encoder layers into cross-attention blocks within a LLaMA 3.2 11B MLLM. Vision features are patch-wise projected and fused using scaled cross-attention and FiLM-based U-Net modulation. Baseline MLLM achieved 60% accuracy on the dual-type disease classification task. MDF-MLLM, with both U-Net and MLLM components fully fine-tuned during training, achieved a significantly higher accuracy of 94%, representing a 56% improvement. Recall and F1-scores improved by as much as 67% and 35% over baseline, respectively. Ablation studies confirmed that the multi-depth fusion approach contributed to substantial gains in spatial reasoning and classification, particularly for inherited diseases with rich clinical text. MDF-MLLM presents a generalizable, interpretable, and modular framework for fundus image classification, outperforming traditional MLLM baselines through multi-scale feature fusion. The architecture holds promise for real-world deployment in clinical decision support systems. Future work will explore synchronized training techniques, a larger pool of diseases for more generalizability, and extending the model for segmentation tasks.