KV-Efficient VLA: A Method to Speed up Vision Language Models with RNN-Gated Chunked KV Cache
作者: Wanshun Xu, Long Zhuang, Lianlei Shan
分类: cs.CV, cs.AI
发布日期: 2025-09-20 (更新: 2025-11-23)
💡 一句话要点
KV-Efficient VLA:利用RNN门控分块KV缓存加速视觉语言模型
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 视觉语言模型 KV缓存 RNN门控 模型加速 内存压缩
📋 核心要点
- VLA模型在长时程任务中面临高计算成本和内存需求,尤其是在处理历史图像token时。
- KV-Efficient VLA通过RNN门控机制选择性地保留高实用性的上下文,压缩KV缓存。
- 实验表明,该方法能显著节省FLOPs、提高推理速度并减少KV内存占用,且易于集成。
📝 摘要(中文)
视觉-语言-动作(VLA)模型为机器人感知和控制提供了一个统一的框架,但其扩展到真实世界、长时程任务的能力受到注意力机制的高计算成本和推理过程中存储键值(KV)对所需的大量内存的限制,尤其是在保留历史图像token作为上下文时。最近的方法主要集中在扩展骨干架构以提高泛化能力,而较少强调解决实时使用至关重要的推理效率低下问题。本文提出了KV-Efficient VLA,这是一种与模型无关的内存压缩方法,旨在通过引入一种轻量级机制来选择性地保留高实用性的上下文来解决这些限制。我们的方法将KV缓存划分为固定大小的块,并采用循环门控模块来根据学习到的效用分数总结和过滤历史上下文。这种设计旨在保留最近的细粒度细节,同时积极地修剪陈旧的、低相关性的内存。实验表明,我们的方法平均可以节省24.6%的FLOPs,提高1.34倍的推理速度,并减少1.87倍的KV内存。我们的方法可以无缝集成到最新的VLA堆栈中,从而实现可扩展的推理,而无需修改下游控制逻辑。
🔬 方法详解
问题定义:VLA模型在处理长时程任务时,由于需要存储大量的历史图像token作为上下文,导致KV缓存占用大量内存,推理效率低下。现有方法主要关注提升模型泛化能力,忽略了推理效率的优化,难以满足实时性要求。
核心思路:通过引入一个轻量级的机制,选择性地保留高实用性的上下文信息,从而压缩KV缓存。核心思想是区分不同历史信息的价值,保留重要信息,丢弃冗余信息,以降低计算和存储成本。
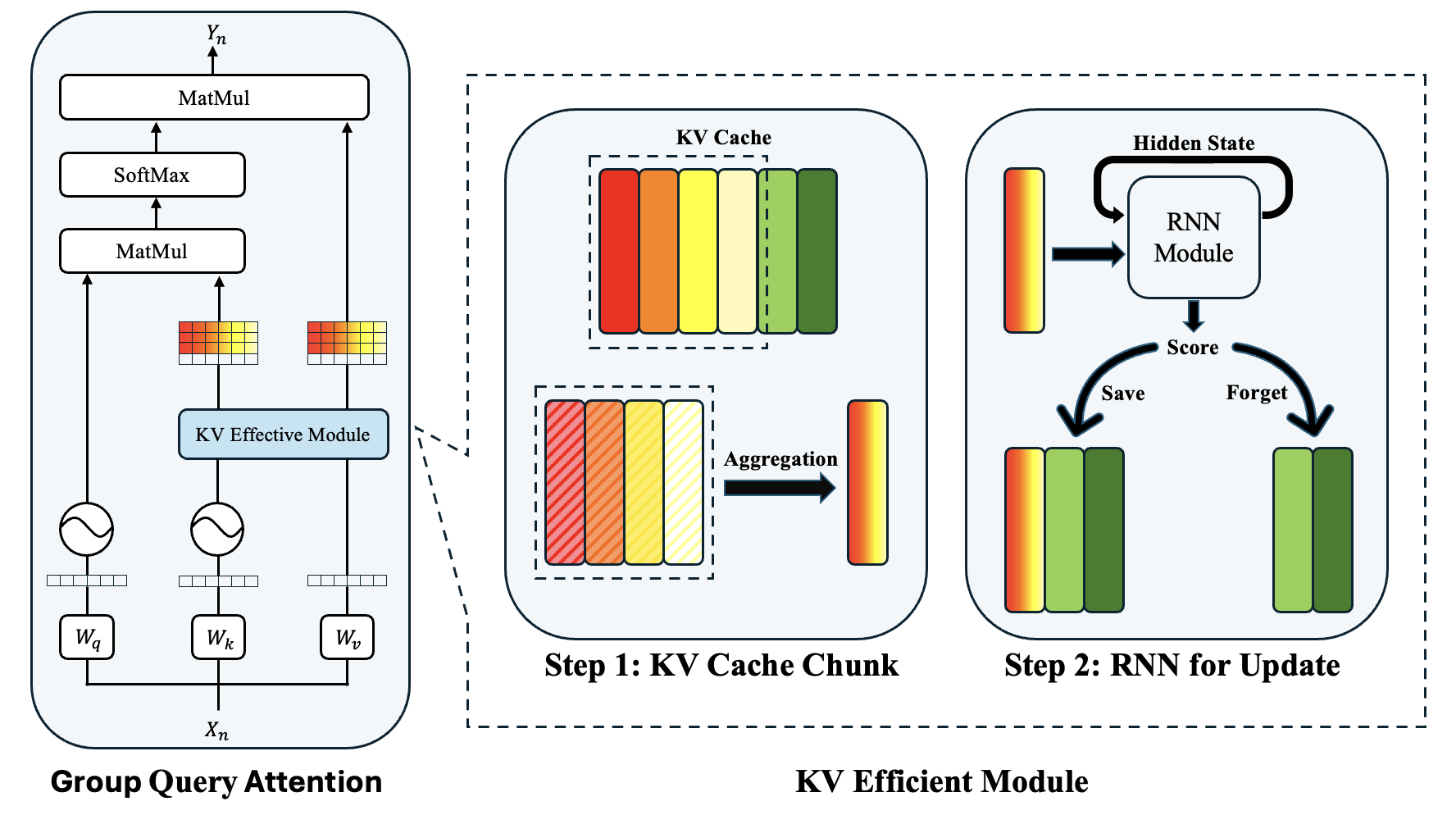
技术框架:KV-Efficient VLA将KV缓存划分为固定大小的块(chunks),并使用一个循环门控模块(RNN-gated module)来处理这些块。该门控模块根据学习到的效用分数,对历史上下文进行总结和过滤。整体流程包括:1) 将KV缓存分块;2) 使用RNN门控模块计算每个块的效用分数;3) 根据效用分数选择性地保留或丢弃块。
关键创新:关键创新在于使用RNN门控机制来动态地评估和过滤KV缓存中的历史信息。与传统的静态压缩方法不同,该方法能够根据上下文的重要性自适应地调整保留的信息量。这种动态选择机制能够更好地平衡计算成本和性能。
关键设计:RNN门控模块的具体结构和训练方式是关键设计。论文可能采用了GRU或LSTM等循环神经网络结构,并设计了相应的损失函数来训练门控模块,使其能够准确地评估历史信息的效用。此外,KV缓存的分块大小也是一个重要的参数,需要根据具体任务进行调整。
🖼️ 关键图片


📊 实验亮点
实验结果表明,KV-Efficient VLA在VLA模型上实现了显著的性能提升。具体来说,该方法平均节省了24.6%的FLOPs,提高了1.34倍的推理速度,并减少了1.87倍的KV内存占用。这些数据表明,该方法在降低计算成本和提高推理效率方面具有显著优势。
🎯 应用场景
该研究成果可广泛应用于机器人感知与控制领域,尤其是在需要处理长时程、高维度视觉信息的任务中,例如自动驾驶、智能制造、家庭服务机器人等。通过降低VLA模型的计算和存储成本,可以使其更容易部署在资源受限的设备上,并提高其在实际应用中的实时性。
📄 摘要(原文)
Vision-Language-Action (VLA) models offer a unified framework for robotic perception and control, but their ability to scale to real-world, long-horizon tasks is limited by the high computational cost of attention and the large memory required for storing key-value (KV) pairs during inference, particularly when retaining historical image tokens as context. Recent methods have focused on scaling backbone architectures to improve generalization, with less emphasis on addressing inference inefficiencies essential for real-time use. In this work, we present KV-Efficient VLA, a model-agnostic memory compression approach designed to address these limitations by introducing a lightweight mechanism to selectively retain high-utility context. Our method partitions the KV cache into fixed-size chunks and employs a recurrent gating module to summarize and filter the historical context according to learned utility scores. This design aims to preserve recent fine-grained detail while aggressively pruning stale, low-relevance memory. Based on experiments, our approach can yield an average of 24.6% FLOPs savings, 1.34x inference speedup, and 1.87x reduction in KV memory. Our method integrates seamlessly into recent VLA stacks, enabling scalable inference without modifying downstream control logic.