Text-Scene: A Scene-to-Language Parsing Framework for 3D Scene Understanding
作者: Haoyuan Li, Rui Liu, Hehe Fan, Yi Yang
分类: cs.CV, cs.AI, cs.RO
发布日期: 2025-09-20
备注: 19 pages, 12 figures, 6 tables
💡 一句话要点
提出Text-Scene框架,实现3D场景到自然语言的自动解析,促进3D场景理解。
🎯 匹配领域: 支柱三:空间感知与语义 (Perception & Semantics) 支柱七:动作重定向 (Motion Retargeting) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 3D场景理解 场景解析 多模态学习 大型语言模型 几何分析
📋 核心要点
- 现有方法难以将2D图像理解能力扩展到3D场景,面临空间关系、物理属性等更丰富的概念挑战。
- Text-Scene框架通过几何分析和MLLM,自动将3D场景解析为文本描述,无需人工标注。
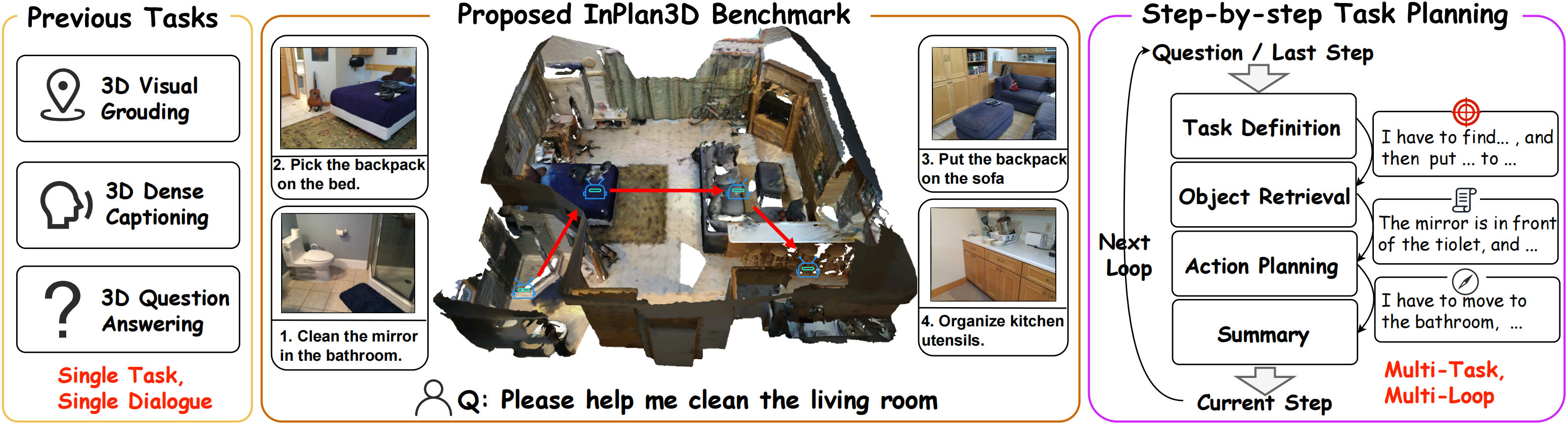
- 实验表明,Text-Scene生成的文本解析能够准确表示3D场景,并提升下游任务性能,同时发布了新的3D任务规划基准InPlan3D。
📝 摘要(中文)
本文提出Text-Scene框架,用于自动将3D场景解析为文本描述,以实现场景理解。该模型能够识别物体属性和空间关系,并生成连贯的场景总结,从而弥合了3D观测和语言之间的差距,无需人工干预。Text-Scene利用几何分析和多模态大型语言模型(MLLM),生成准确、详细且易于理解的描述,捕捉物体级别的细节和全局级别的上下文。在基准测试上的实验结果表明,我们的文本解析能够忠实地表示3D场景,并有益于下游任务。为了评估MLLM的推理能力,我们提出了InPlan3D,这是一个全面的3D任务规划基准,包含636个室内场景中的3174个长期规划任务。我们强调方法的清晰性和可访问性,旨在通过语言使3D场景内容易于理解。代码和数据集将会发布。
🔬 方法详解
问题定义:现有方法在3D场景理解方面面临挑战,主要是因为3D环境涉及更丰富的概念,如空间关系、可供性、物理属性和布局等。此外,缺乏大规模的3D视觉-语言数据集也阻碍了相关研究的进展。因此,如何有效地将3D场景信息转化为可理解的语言描述,成为了一个亟待解决的问题。
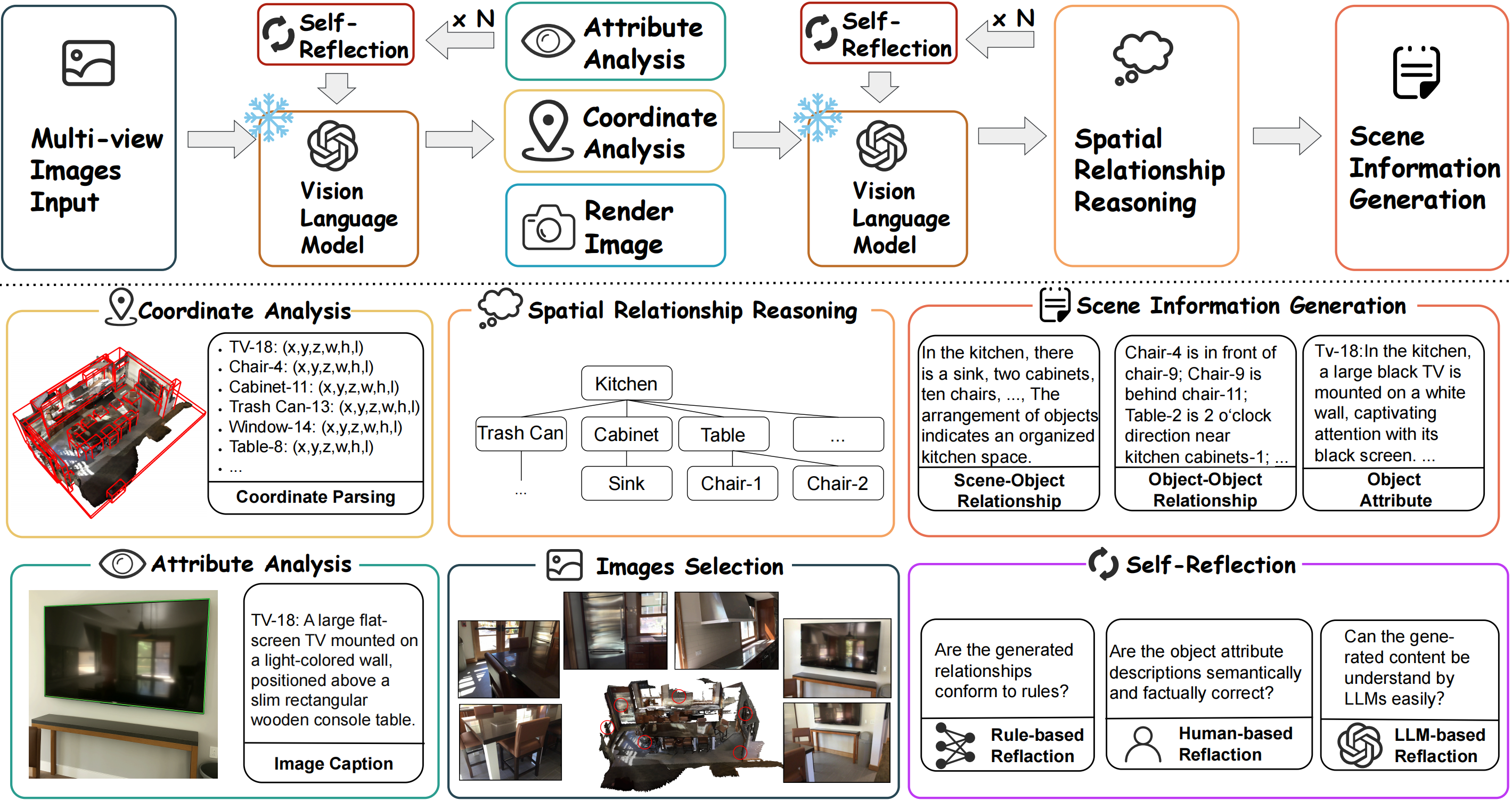
核心思路:Text-Scene的核心思路是利用几何分析和多模态大型语言模型(MLLM)的强大能力,自动将3D场景解析为文本描述。通过几何分析提取场景中的物体属性和空间关系,然后利用MLLM生成连贯的场景总结。这种方法旨在弥合3D观测和语言之间的差距,使得机器能够像人类一样理解和描述3D场景。
技术框架:Text-Scene框架主要包含以下几个阶段:1) 3D场景输入:接收3D场景数据作为输入。2) 几何分析:对3D场景进行几何分析,提取物体属性(如类别、大小、颜色等)和空间关系(如物体之间的位置关系、相对距离等)。3) 文本生成:利用MLLM,根据提取的物体属性和空间关系,生成对整个场景的连贯文本描述。4) 评估与优化:通过实验评估生成的文本描述的质量,并对模型进行优化。
关键创新:Text-Scene的关键创新在于它能够自动地将3D场景解析为文本描述,而无需人工干预。这使得该框架能够处理大规模的3D场景数据,并为下游任务提供丰富的场景信息。此外,该框架结合了几何分析和MLLM,能够生成准确、详细且易于理解的描述,捕捉物体级别的细节和全局级别的上下文。
关键设计:具体的技术细节包括:1) 使用点云或网格等3D数据格式作为输入。2) 利用现有的几何分析算法提取物体属性和空间关系。3) 选择合适的MLLM作为文本生成器,并对其进行微调,以适应3D场景描述的任务。4) 设计合适的损失函数,以优化生成的文本描述的质量。具体的参数设置和网络结构取决于所选择的几何分析算法和MLLM。
🖼️ 关键图片

📊 实验亮点
实验结果表明,Text-Scene生成的文本解析能够忠实地表示3D场景,并有益于下游任务。作者提出了InPlan3D基准,包含3174个长期规划任务,用于评估MLLM的推理能力。具体性能数据和对比基线将在论文中详细展示,旨在证明Text-Scene在3D场景理解方面的有效性和优越性。
🎯 应用场景
Text-Scene框架具有广泛的应用前景,例如在机器人导航、智能家居、虚拟现实和增强现实等领域。它可以帮助机器人理解周围环境,从而更好地完成任务。在智能家居中,它可以用于场景理解和物体识别,从而提供更智能化的服务。在虚拟现实和增强现实中,它可以用于生成逼真的场景描述,从而增强用户的沉浸感。未来,该技术有望进一步发展,实现更高级别的3D场景理解和交互。
📄 摘要(原文)
Enabling agents to understand and interact with complex 3D scenes is a fundamental challenge for embodied artificial intelligence systems. While Multimodal Large Language Models (MLLMs) have achieved significant progress in 2D image understanding, extending such capabilities to 3D scenes remains difficult: 1) 3D environment involves richer concepts such as spatial relationships, affordances, physics, layout, and so on, 2) the absence of large-scale 3D vision-language datasets has posed a significant obstacle. In this paper, we introduce Text-Scene, a framework that automatically parses 3D scenes into textual descriptions for scene understanding. Given a 3D scene, our model identifies object attributes and spatial relationships, and then generates a coherent summary of the whole scene, bridging the gap between 3D observation and language without requiring human-in-the-loop intervention. By leveraging both geometric analysis and MLLMs, Text-Scene produces descriptions that are accurate, detailed, and human-interpretable, capturing object-level details and global-level context. Experimental results on benchmarks demonstrate that our textual parses can faithfully represent 3D scenes and benefit downstream tasks. To evaluate the reasoning capability of MLLMs, we present InPlan3D, a comprehensive benchmark for 3D task planning, consisting of 3174 long-term planning tasks across 636 indoor scenes. We emphasize clarity and accessibility in our approach, aiming to make 3D scene content understandable through language. Code and datasets will be released.