Improving Autism Detection with Multimodal Behavioral Analysis
作者: William Saakyan, Matthias Norden, Lola Eversmann, Simon Kirsch, Muyu Lin, Simon Guendelman, Isabel Dziobek, Hanna Drimalla
分类: cs.CV, cs.LG
发布日期: 2025-09-19
💡 一句话要点
提出基于多模态行为分析的自闭症检测方法,提升了诊断准确率。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 自闭症检测 多模态融合 行为分析 凝视特征 机器学习
📋 核心要点
- 现有自闭症检测方法在凝视特征提取上表现不佳,且泛化能力不足,限制了实际应用。
- 论文提出一种多模态行为分析方法,融合面部表情、语音、头部运动、心率和凝视行为等多种信息。
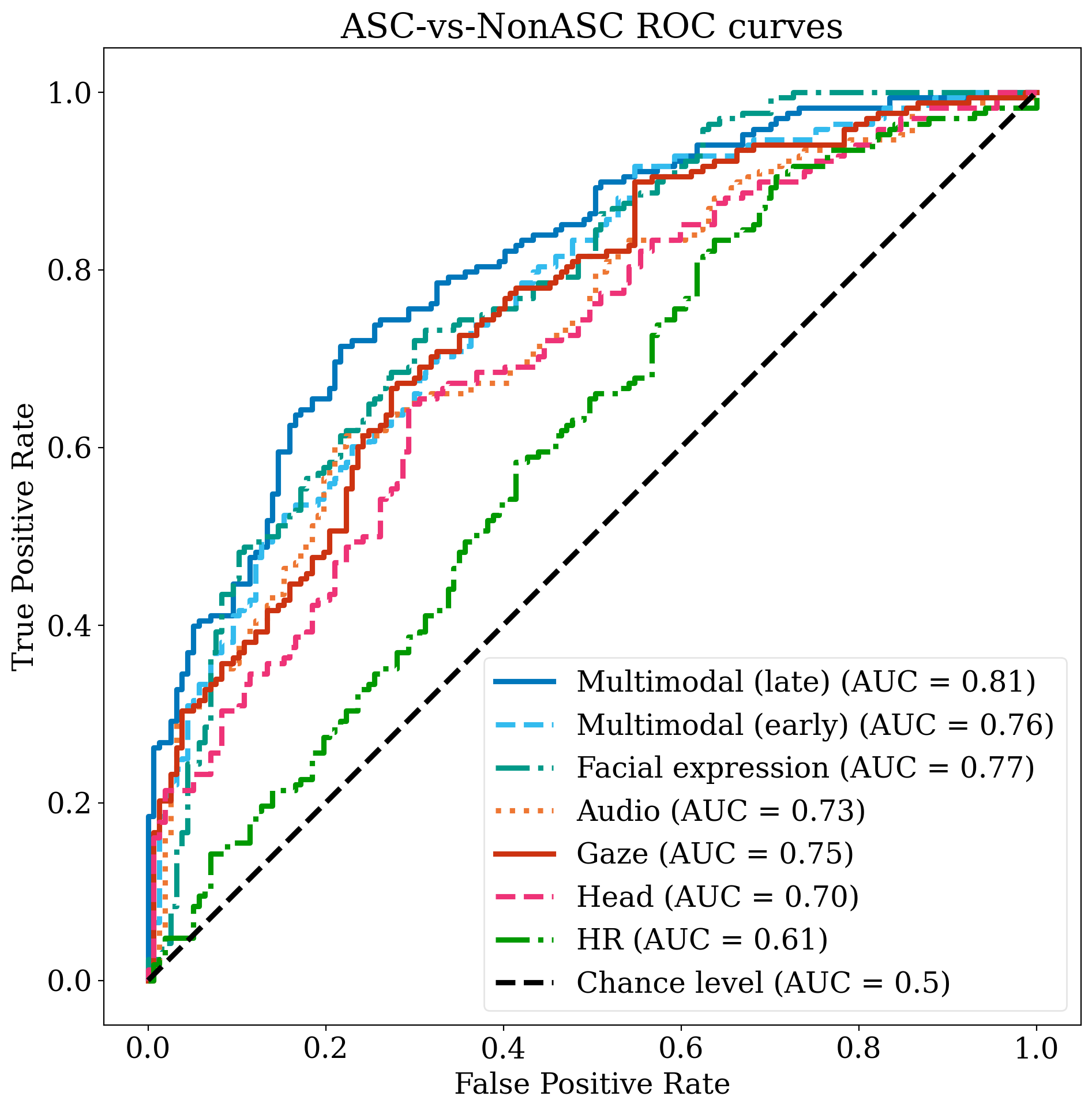
- 通过引入新的凝视统计描述符,显著提升了凝视特征的分类准确率,整体分类准确率达到74%。
📝 摘要(中文)
由于自闭症谱系障碍(ASC)诊断的复杂性和资源密集性,许多计算机辅助诊断方法被提出,通过分析患者视频数据中的行为线索来检测自闭症。尽管这些模型在某些数据集上显示出不错的结果,但它们在凝视特征表现不佳和缺乏真实世界泛化能力方面存在困难。为了解决这些挑战,我们分析了一个标准化的视频数据集,包含168名ASC参与者(46%为女性)和157名非自闭症参与者(46%为女性),据我们所知,这是目前最大且最平衡的数据集。我们对面部表情、语音韵律、头部运动、心率变异性(HRV)和凝视行为进行了多模态分析。为了解决先前凝视模型的局限性,我们引入了新的统计描述符来量化眼球凝视角度的变化,将基于凝视的分类准确率从64%提高到69%,并将计算结果与ASC凝视回避的临床研究结果对齐。使用后期融合,我们实现了74%的分类准确率,证明了整合跨多种模态的行为标记的有效性。我们的研究结果突出了可扩展的、基于视频的筛查工具在支持自闭症评估方面的潜力。
🔬 方法详解
问题定义:现有基于视频的自闭症检测方法,尤其是在处理凝视行为特征时,准确率较低,并且在真实世界场景中的泛化能力不足。主要痛点在于如何有效提取和利用患者的凝视模式,以及如何整合多种行为模态的信息以提高诊断准确率。
核心思路:论文的核心思路是通过多模态融合来提升自闭症检测的准确性。针对现有方法在凝视特征上的不足,论文提出了新的统计描述符,用于更精确地量化眼球凝视角度的变化。同时,结合面部表情、语音韵律、头部运动和心率变异性等多种生理和行为信号,利用不同模态之间的互补信息,从而提高整体的分类性能。
技术框架:该方法采用多模态融合的框架。首先,对视频数据进行预处理,提取面部表情、语音韵律、头部运动、心率变异性和凝视行为等特征。然后,针对每种模态,训练独立的分类器。最后,采用后期融合(late fusion)策略,将各个模态的分类结果进行整合,得到最终的自闭症诊断结果。
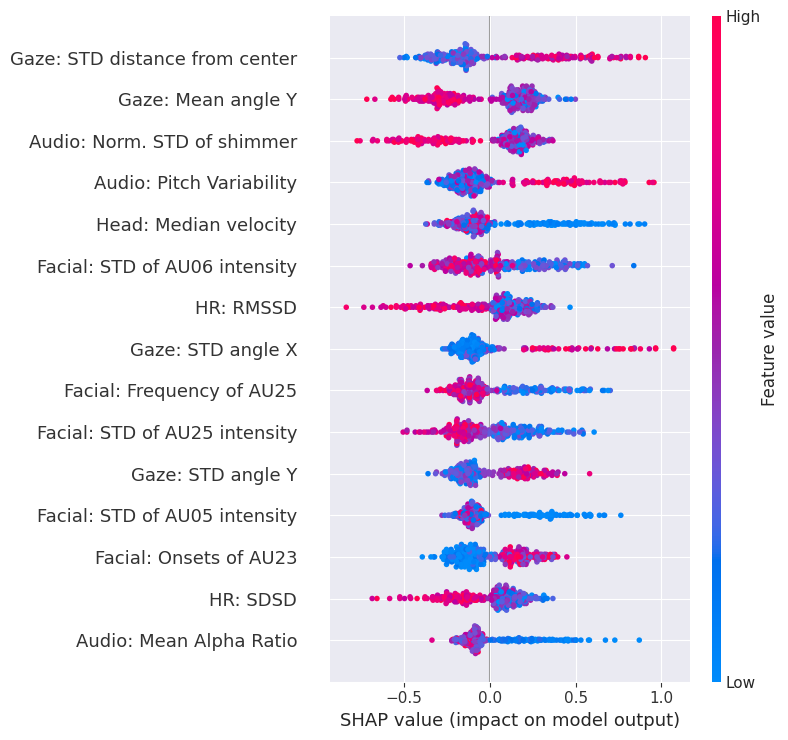
关键创新:论文的关键创新在于提出了新的凝视统计描述符,能够更有效地捕捉自闭症患者在凝视行为上的异常模式。这些描述符能够量化眼球凝视角度的变化,从而更好地反映自闭症患者的凝视回避行为。此外,多模态融合策略也提升了整体的诊断准确率。
关键设计:论文使用了包含168名ASC患者和157名非自闭症参与者的大规模平衡数据集。在凝视特征提取方面,设计了新的统计描述符来量化眼球凝视角度的变化。在融合策略上,采用了简单的后期融合方法,即将各个模态的分类概率进行加权平均。具体的权重参数可能需要根据实验结果进行调整。
🖼️ 关键图片
📊 实验亮点
论文通过引入新的凝视统计描述符,将基于凝视的自闭症分类准确率从64%提高到69%。通过多模态融合,最终实现了74%的分类准确率,表明该方法在自闭症检测方面具有显著的优势。该结果是在一个包含大量参与者的大规模平衡数据集上获得的,增强了研究结果的可靠性。
🎯 应用场景
该研究成果可应用于开发可扩展的、基于视频的自闭症筛查工具,辅助临床医生进行早期诊断和干预。该技术具有非侵入性、成本较低的优点,有望在社区医疗、远程医疗等场景中推广,提高自闭症的早期识别率,从而改善患者的预后。
📄 摘要(原文)
Due to the complex and resource-intensive nature of diagnosing Autism Spectrum Condition (ASC), several computer-aided diagnostic support methods have been proposed to detect autism by analyzing behavioral cues in patient video data. While these models show promising results on some datasets, they struggle with poor gaze feature performance and lack of real-world generalizability. To tackle these challenges, we analyze a standardized video dataset comprising 168 participants with ASC (46% female) and 157 non-autistic participants (46% female), making it, to our knowledge, the largest and most balanced dataset available. We conduct a multimodal analysis of facial expressions, voice prosody, head motion, heart rate variability (HRV), and gaze behavior. To address the limitations of prior gaze models, we introduce novel statistical descriptors that quantify variability in eye gaze angles, improving gaze-based classification accuracy from 64% to 69% and aligning computational findings with clinical research on gaze aversion in ASC. Using late fusion, we achieve a classification accuracy of 74%, demonstrating the effectiveness of integrating behavioral markers across multiple modalities. Our findings highlight the potential for scalable, video-based screening tools to support autism assessment.