Qianfan-VL: Domain-Enhanced Universal Vision-Language Models
作者: Daxiang Dong, Mingming Zheng, Dong Xu, Bairong Zhuang, Wenyu Zhang, Chunhua Luo, Haoran Wang, Zijian Zhao, Jie Li, Yuxuan Li, Hanjun Zhong, Mengyue Liu, Jieting Chen, Shupeng Li, Lun Tian, Yaping Feng, Xin Li, Donggang Jiang, Yong Chen, Yehua Xu, Duohao Qin, Chen Feng, Dan Wang, Henghua Zhang, Jingjing Ha, Jinhui He, Yanfeng Zhai, Chengxin Zheng, Jiayi Mao, Jiacheng Chen, Ruchang Yao, Ziye Yuan, Jianmin Wu, Guangjun Xie, Dou Shen
分类: cs.CV, cs.AI
发布日期: 2025-09-19
备注: 12 pages
💡 一句话要点
提出Qianfan-VL,通过领域增强技术实现领先的多模态大语言模型
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态大语言模型 领域增强 视觉语言模型 OCR 文档理解 数学推理 长链式思考
📋 核心要点
- 现有通用视觉语言模型在特定领域表现不足,难以满足企业级应用需求。
- Qianfan-VL采用多阶段训练和数据合成,增强模型在OCR、文档理解等领域的性能。
- 实验表明,Qianfan-VL在多个基准测试中达到领先水平,验证了领域增强的有效性。
📝 摘要(中文)
我们提出了Qianfan-VL,一系列参数规模从30亿到700亿的多模态大语言模型,通过创新的领域增强技术实现了最先进的性能。我们的方法采用了多阶段渐进式训练和高精度数据合成流程,这些技术对于增强领域特定能力同时保持强大的通用性能至关重要。Qianfan-VL在通用基准测试上取得了与领先开源模型相当的结果,并在CCBench、SEEDBench IMG、ScienceQA和MMStar等基准测试上取得了最先进的性能。领域增强策略在OCR和文档理解方面提供了显著优势,这在公共基准测试(OCRBench 87.3%,DocVQA 94.75%)和内部评估中得到了验证。值得注意的是,Qianfan-VL-8B和70B变体融合了长链式思考能力,在数学推理(MathVista 78.6%)和逻辑推理任务上表现出卓越的性能。所有模型完全在百度的昆仑P800芯片上训练,验证了大规模AI基础设施在单个任务上以超过90%的扩展效率在5000个芯片上训练SOTA级多模态模型的能力。这项工作为开发适用于各种企业部署场景的领域增强型多模态模型建立了一种有效的方法。
🔬 方法详解
问题定义:现有视觉语言模型在通用任务上表现良好,但在特定领域,如OCR、文档理解、数学推理等,性能仍有提升空间。现有方法难以兼顾通用性和领域特定性,且训练成本高昂。
核心思路:Qianfan-VL的核心思路是通过领域增强技术,在保持通用性能的同时,显著提升模型在特定领域的表现。通过多阶段渐进式训练和高精度数据合成,使模型能够更好地理解和处理特定领域的知识和任务。
技术框架:Qianfan-VL的训练流程包括以下几个主要阶段:1) 预训练:使用大规模通用视觉语言数据集进行预训练,使模型具备基本的视觉和语言理解能力。2) 领域增强:使用高精度合成的领域特定数据进行训练,提升模型在特定领域的性能。3) 微调:在下游任务上进行微调,进一步优化模型性能。
关键创新:Qianfan-VL的关键创新在于其领域增强策略,该策略通过多阶段渐进式训练和高精度数据合成,有效地提升了模型在特定领域的性能。与传统的微调方法相比,Qianfan-VL的领域增强策略能够更好地保留模型的通用能力,避免过拟合于特定领域。
关键设计:Qianfan-VL采用了多项关键设计,包括:1) 高精度数据合成流程,用于生成高质量的领域特定数据。2) 多阶段渐进式训练策略,逐步提升模型在通用和特定领域的性能。3) 长链式思考能力,提升模型在数学推理和逻辑推理任务上的表现。具体参数设置和损失函数细节未在摘要中详细说明,属于未知信息。
🖼️ 关键图片
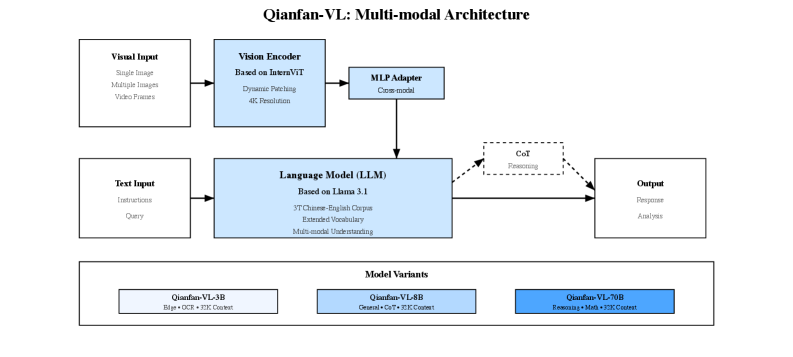
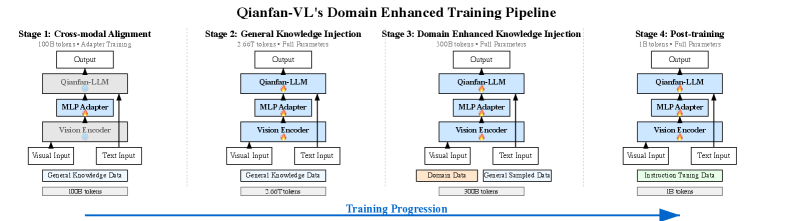
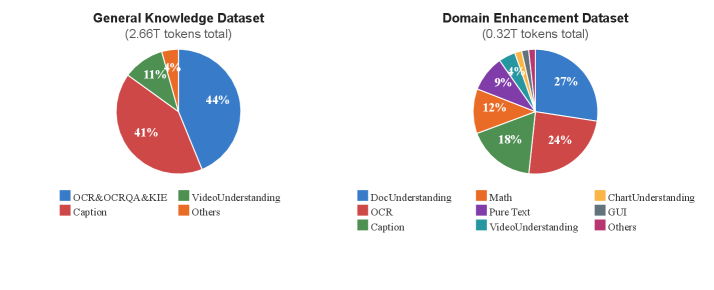
📊 实验亮点
Qianfan-VL在多个基准测试中取得了领先的性能。在OCRBench上达到87.3%,在DocVQA上达到94.75%。Qianfan-VL-8B和70B变体在MathVista上达到78.6%。所有模型均在百度昆仑P800芯片上训练,验证了大规模AI基础设施的有效性,在5000个芯片上实现了超过90%的扩展效率。
🎯 应用场景
Qianfan-VL适用于多种企业级应用场景,如智能文档处理、OCR识别、数学问题求解、智能客服等。该研究成果有助于提升企业自动化水平,降低运营成本,并为用户提供更智能、更高效的服务。未来,Qianfan-VL有望在更多领域得到应用,推动人工智能技术的发展。
📄 摘要(原文)
We present Qianfan-VL, a series of multimodal large language models ranging from 3B to 70B parameters, achieving state-of-the-art performance through innovative domain enhancement techniques. Our approach employs multi-stage progressive training and high-precision data synthesis pipelines, which prove to be critical technologies for enhancing domain-specific capabilities while maintaining strong general performance. Qianfan-VL achieves comparable results to leading open-source models on general benchmarks, with state-of-the-art performance on benchmarks such as CCBench, SEEDBench IMG, ScienceQA, and MMStar. The domain enhancement strategy delivers significant advantages in OCR and document understanding, validated on both public benchmarks (OCRBench 873, DocVQA 94.75%) and in-house evaluations. Notably, Qianfan-VL-8B and 70B variants incorporate long chain-of-thought capabilities, demonstrating superior performance on mathematical reasoning (MathVista 78.6%) and logical inference tasks. All models are trained entirely on Baidu's Kunlun P800 chips, validating the capability of large-scale AI infrastructure to train SOTA-level multimodal models with over 90% scaling efficiency on 5000 chips for a single task. This work establishes an effective methodology for developing domain-enhanced multimodal models suitable for diverse enterprise deployment scenarios.