Towards Sharper Object Boundaries in Self-Supervised Depth Estimation
作者: Aurélien Cecille, Stefan Duffner, Franck Davoine, Rémi Agier, Thibault Neveu
分类: cs.CV, cs.AI, cs.RO
发布日期: 2025-09-19 (更新: 2025-11-17)
备注: BMVC 2025 Oral, 10 pages, 6 figures
💡 一句话要点
提出基于混合分布的自监督深度估计,显著提升物体边界清晰度
🎯 匹配领域: 支柱三:空间感知与语义 (Perception & Semantics)
关键词: 自监督学习 深度估计 单目视觉 混合分布 边界清晰度 点云重建 3D场景理解
📋 核心要点
- 现有单目深度估计方法在物体边界处深度模糊,导致3D场景理解不准确。
- 论文提出将像素深度建模为混合分布,通过混合权重捕获深度不确定性,实现自监督下的清晰边界。
- 实验表明,该方法在KITTI和VKITTIv2数据集上显著提升了边界清晰度和点云质量。
📝 摘要(中文)
精确的单目深度估计对于3D场景理解至关重要,但现有方法通常模糊物体边界的深度,引入虚假的中间3D点。虽然实现清晰的边缘通常需要非常细粒度的监督,但我们的方法仅使用自监督即可产生清晰的深度不连续性。具体来说,我们将每个像素的深度建模为混合分布,捕获多个合理的深度,并将不确定性从直接回归转移到混合权重。这种公式通过方差感知损失函数和不确定性传播无缝集成到现有流程中。在KITTI和VKITTIv2上的大量评估表明,与最先进的基线相比,我们的方法实现了高达35%的边界清晰度提升,并改善了点云质量。
🔬 方法详解
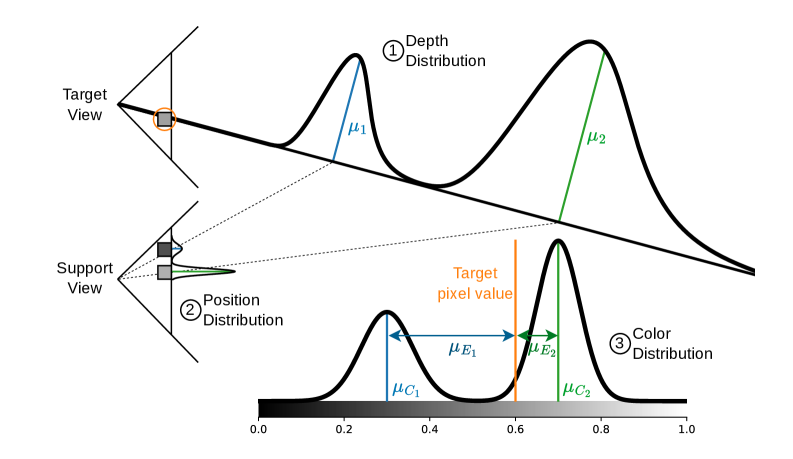
问题定义:现有单目深度估计方法在物体边界处存在深度模糊的问题,导致生成的3D点云质量下降,影响后续的3D场景理解任务。现有方法通常需要精细的监督信息才能获得清晰的边界,但在自监督场景下难以实现。
核心思路:论文的核心思路是将每个像素的深度建模为一个混合分布,而不是直接回归一个单一的深度值。这种混合分布能够捕获多个可能的深度值,从而更好地表示物体边界处的不确定性。通过学习混合分布的权重,可以将不确定性从深度回归转移到权重学习上,从而实现更清晰的深度边界。
技术框架:该方法可以无缝集成到现有的自监督深度估计pipeline中。整体流程包括:1)输入单目图像;2)使用深度估计网络预测每个像素的深度混合分布参数(例如,混合权重、均值和方差);3)使用方差感知损失函数训练网络,该损失函数考虑了深度估计的不确定性;4)通过不确定性传播,将深度估计的不确定性传递到后续任务中。
关键创新:最重要的技术创新点在于将像素深度建模为混合分布。与传统的直接回归方法相比,混合分布能够更好地表示深度不确定性,尤其是在物体边界处。这种建模方式使得网络能够学习到更清晰的深度不连续性,从而提升了边界清晰度。
关键设计:关键设计包括:1)混合分布的选择:论文可能使用了高斯混合模型或其他类型的混合模型来表示深度分布;2)方差感知损失函数:损失函数的设计需要考虑深度估计的方差,以鼓励网络学习到更准确的深度值;3)网络结构:深度估计网络的结构需要能够预测混合分布的参数,例如,混合权重、均值和方差。
🖼️ 关键图片


📊 实验亮点
实验结果表明,该方法在KITTI和VKITTIv2数据集上显著提升了物体边界的清晰度,最高可达35%。此外,该方法还改善了生成的点云质量,使其更接近真实场景。与state-of-the-art的自监督深度估计方法相比,该方法在边界清晰度和点云质量方面均取得了显著的提升。
🎯 应用场景
该研究成果可应用于自动驾驶、机器人导航、增强现实等领域。清晰的深度估计能够提升3D场景理解的准确性,从而改善自动驾驶车辆的感知能力,提高机器人导航的安全性,并增强AR应用的沉浸感。未来,该方法有望进一步推广到其他3D视觉任务中。
📄 摘要(原文)
Accurate monocular depth estimation is crucial for 3D scene understanding, but existing methods often blur depth at object boundaries, introducing spurious intermediate 3D points. While achieving sharp edges usually requires very fine-grained supervision, our method produces crisp depth discontinuities using only self-supervision. Specifically, we model per-pixel depth as a mixture distribution, capturing multiple plausible depths and shifting uncertainty from direct regression to the mixture weights. This formulation integrates seamlessly into existing pipelines via variance-aware loss functions and uncertainty propagation. Extensive evaluations on KITTI and VKITTIv2 show that our method achieves up to 35% higher boundary sharpness and improves point cloud quality compared to state-of-the-art baselines.