Global Regulation and Excitation via Attention Tuning for Stereo Matching
作者: Jiahao Li, Xinhong Chen, Zhengmin Jiang, Qian Zhou, Yung-Hui Li, Jianping Wang
分类: cs.CV
发布日期: 2025-09-19
备注: International Conference on Computer Vision (ICCV 2025)
🔗 代码/项目: GITHUB
💡 一句话要点
提出GREAT框架,通过注意力机制增强立体匹配全局上下文信息,提升在病态区域的匹配精度。
🎯 匹配领域: 支柱三:空间感知与语义 (Perception & Semantics)
关键词: 立体匹配 注意力机制 全局上下文 深度估计 代价体
📋 核心要点
- 现有立体匹配方法在遮挡、无纹理等病态区域表现不佳,缺乏全局上下文和几何信息是主要瓶颈。
- GREAT框架通过空间、匹配和体注意力模块,显式建模全局上下文和几何信息,提升代价体的鲁棒性。
- 实验表明,GREAT框架能有效提升现有立体匹配算法的性能,并在多个数据集上取得领先结果。
📝 摘要(中文)
本文提出了一种名为全局调节和激励的注意力调整(GREAT)框架,旨在解决立体匹配算法在遮挡、无纹理或重复纹理等病态区域表现不佳的问题。这些区域的挑战源于缺乏有效的迭代细化所需的全局上下文和几何信息。GREAT框架包含三个注意力模块:空间注意力(SA)捕捉空间维度内的全局上下文;匹配注意力(MA)提取极线上的全局上下文;体注意力(VA)与SA和MA协同工作,构建由全局上下文和几何细节激发的更鲁棒的代价体。通过将GREAT框架集成到多个代表性的迭代立体匹配方法中,并进行大量实验验证了其通用性和有效性,统称为GREAT-Stereo。实验结果表明,该框架在具有挑战性的病态区域表现出卓越的性能。应用于IGEV-Stereo后,我们的GREAT-IGEV在Scene Flow测试集、KITTI 2015和ETH3D排行榜上均排名第一,并在Middlebury基准测试中排名第二。
🔬 方法详解
问题定义:现有的基于迭代的立体匹配算法,如RAFT-Stereo和IGEV-Stereo,在处理遮挡、无纹理或重复纹理等病态区域时面临挑战。这些方法缺乏足够的全局上下文信息和几何约束,导致迭代细化过程容易出错,最终影响视差估计的准确性。因此,如何有效地融入全局信息以提升现有立体匹配算法在病态区域的性能是本文要解决的关键问题。
核心思路:本文的核心思路是通过注意力机制来显式地建模和利用全局上下文信息。具体来说,作者设计了三个注意力模块:空间注意力(SA)、匹配注意力(MA)和体注意力(VA)。SA负责捕捉图像空间中的全局上下文,MA负责提取极线上的全局信息,VA则结合SA和MA的结果,增强代价体的特征表示,使其对病态区域更加鲁棒。通过这种方式,算法能够在迭代过程中更好地利用全局信息进行视差估计。
技术框架:GREAT框架可以集成到现有的迭代立体匹配算法中。其整体流程如下:首先,输入左右图像;然后,利用现有的立体匹配算法(如IGEV-Stereo)构建初始的代价体;接着,通过SA、MA和VA模块对代价体进行增强,融入全局上下文信息;最后,利用增强后的代价体进行迭代视差估计。GREAT框架作为一个插件,可以灵活地添加到不同的立体匹配算法中。
关键创新:本文的关键创新在于提出了一个通用的注意力框架,能够有效地将全局上下文信息融入到现有的迭代立体匹配算法中。与以往的方法相比,GREAT框架不是简单地堆叠更多的网络层,而是通过精心设计的注意力模块,显式地建模空间和极线上的全局信息,从而更好地指导视差估计。这种方法具有更好的可解释性和泛化能力。
关键设计:空间注意力(SA)模块采用自注意力机制,学习图像空间中不同位置之间的依赖关系。匹配注意力(MA)模块则沿着极线方向进行注意力计算,提取极线上的全局信息。体注意力(VA)模块结合SA和MA的结果,对代价体进行加权,增强其对病态区域的鲁棒性。这些模块的具体实现细节,如注意力头的数量、特征维度等,需要根据具体的立体匹配算法进行调整。
🖼️ 关键图片
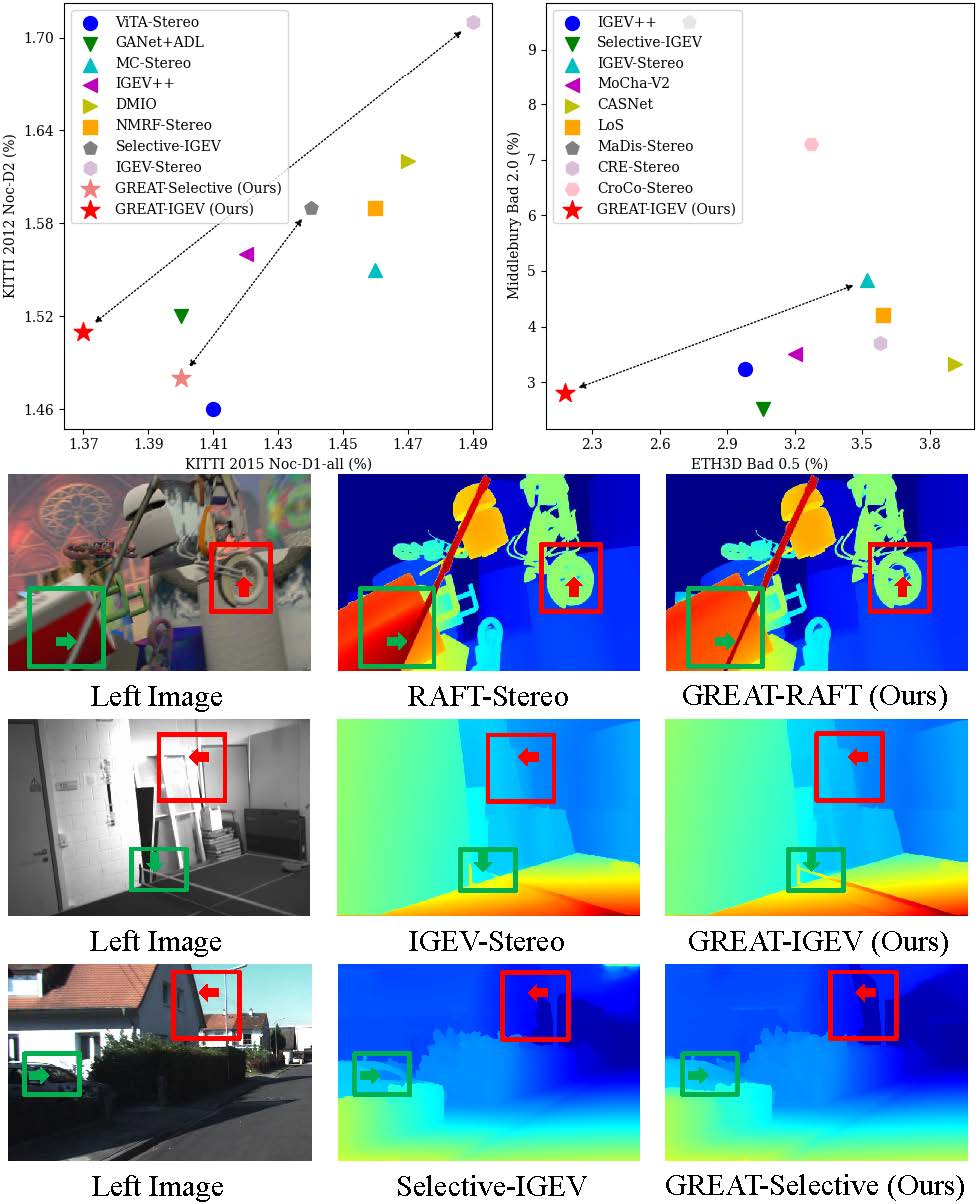

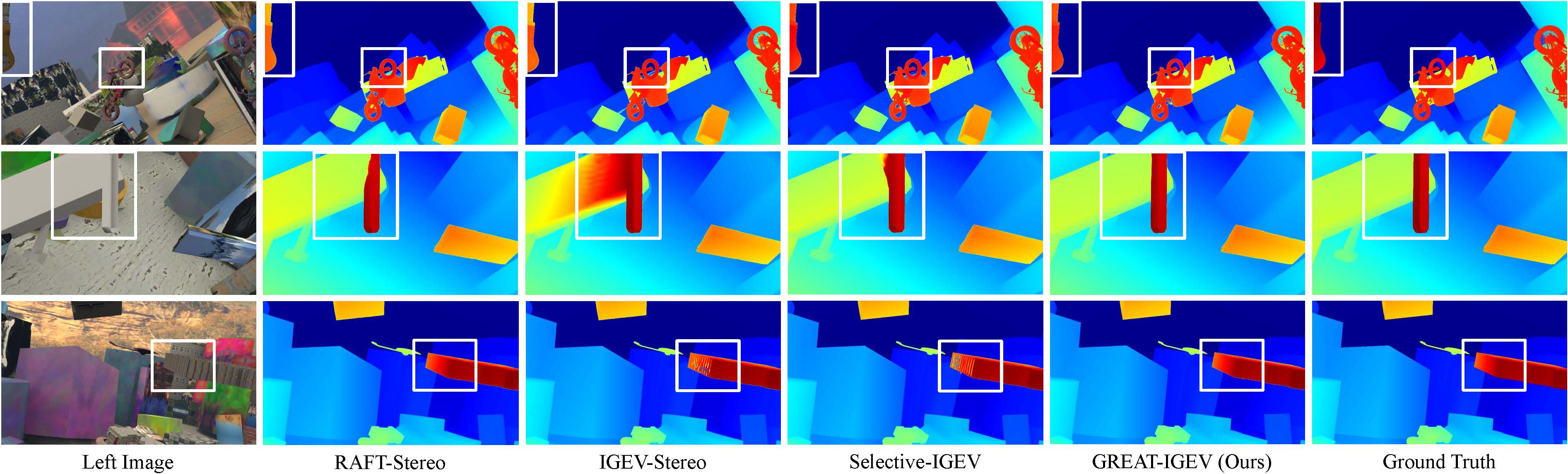
📊 实验亮点
实验结果表明,GREAT框架能够显著提升现有立体匹配算法的性能。例如,将GREAT框架应用于IGEV-Stereo后,在Scene Flow测试集、KITTI 2015和ETH3D排行榜上均取得了第一名的成绩,并在Middlebury基准测试中排名第二。这些结果表明,GREAT框架在处理具有挑战性的场景时具有显著优势,能够有效地提升立体匹配的精度和鲁棒性。
🎯 应用场景
该研究成果可广泛应用于自动驾驶、机器人导航、三维重建、虚拟现实等领域。通过提升立体匹配在复杂环境下的精度,可以提高自动驾驶系统的环境感知能力,增强机器人在未知环境中的导航能力,并为三维重建和虚拟现实应用提供更准确的深度信息。未来,该方法有望进一步扩展到其他计算机视觉任务中。
📄 摘要(原文)
Stereo matching achieves significant progress with iterative algorithms like RAFT-Stereo and IGEV-Stereo. However, these methods struggle in ill-posed regions with occlusions, textureless, or repetitive patterns, due to a lack of global context and geometric information for effective iterative refinement. To enable the existing iterative approaches to incorporate global context, we propose the Global Regulation and Excitation via Attention Tuning (GREAT) framework which encompasses three attention modules. Specifically, Spatial Attention (SA) captures the global context within the spatial dimension, Matching Attention (MA) extracts global context along epipolar lines, and Volume Attention (VA) works in conjunction with SA and MA to construct a more robust cost-volume excited by global context and geometric details. To verify the universality and effectiveness of this framework, we integrate it into several representative iterative stereo-matching methods and validate it through extensive experiments, collectively denoted as GREAT-Stereo. This framework demonstrates superior performance in challenging ill-posed regions. Applied to IGEV-Stereo, among all published methods, our GREAT-IGEV ranks first on the Scene Flow test set, KITTI 2015, and ETH3D leaderboards, and achieves second on the Middlebury benchmark. Code is available at https://github.com/JarvisLee0423/GREAT-Stereo.