Zero-Shot Visual Grounding in 3D Gaussians via View Retrieval
作者: Liwei Liao, Xufeng Li, Xiaoyun Zheng, Boning Liu, Feng Gao, Ronggang Wang
分类: cs.CV, cs.MM
发布日期: 2025-09-19
🔗 代码/项目: GITHUB
💡 一句话要点
提出GVR,通过视图检索实现3D高斯场景的零样本视觉定位
🎯 匹配领域: 支柱三:空间感知与语义 (Perception & Semantics) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 3D视觉定位 零样本学习 3D高斯溅射 视图检索 多视角学习
📋 核心要点
- 现有3D视觉定位方法难以处理3D高斯溅射的隐式表达,需要大量标注数据和逐场景训练。
- GVR通过视图检索将3D视觉定位转化为2D检索问题,利用多视角信息实现零样本定位。
- 实验表明,GVR在零样本设置下实现了最先进的视觉定位性能,无需逐场景训练。
📝 摘要(中文)
本文提出了一种名为GVR(Grounding via View Retrieval)的零样本3D视觉定位框架,用于在3D高斯溅射(3DGS)场景中根据文本提示定位物体。现有方法难以处理3DGS中空间纹理的隐式表示,且需要大量标注数据和逐场景训练。GVR将3D视觉定位转化为2D检索任务,利用物体级别的视图检索从多个视图中收集定位线索,避免了昂贵的3D标注和逐场景训练。实验结果表明,GVR在避免逐场景训练的同时,实现了最先进的视觉定位性能,为零样本3D视觉定位研究奠定了坚实的基础。
🔬 方法详解
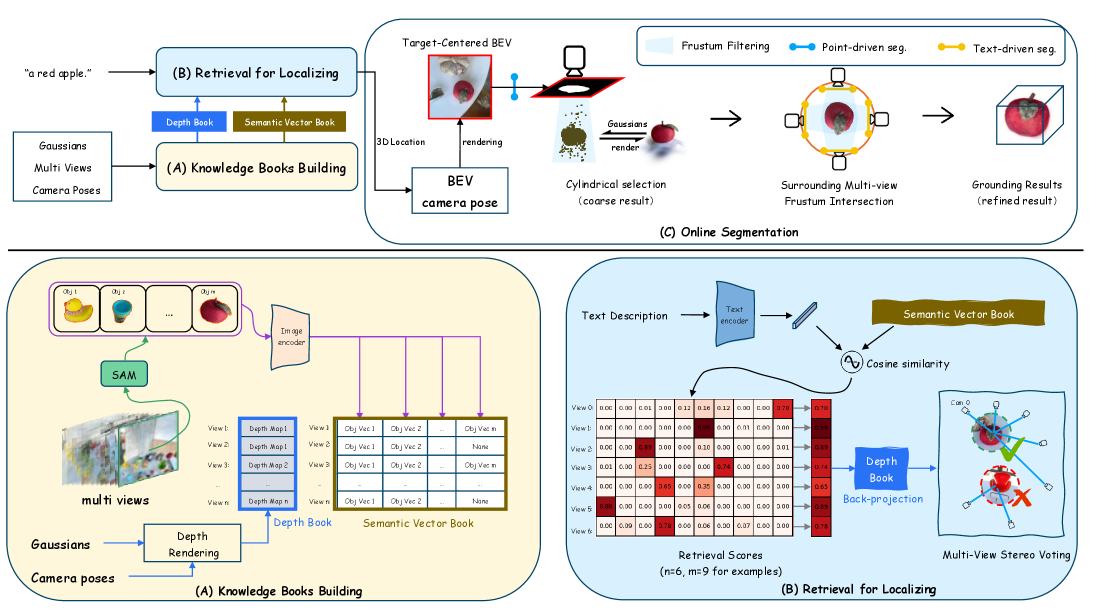
问题定义:现有的3D视觉定位方法在处理3D高斯溅射(3DGS)表示的场景时面临挑战。3DGS使用隐式的方式表达空间纹理信息,使得传统的基于显式几何的方法难以直接应用。此外,现有方法通常需要大量的3D标注数据进行训练,并且需要针对每个场景进行微调,成本高昂。
核心思路:GVR的核心思路是将3D视觉定位问题转化为一个2D视图检索问题。通过检索与文本描述相关的2D视图,可以利用2D视觉定位技术来获取3D场景中物体的定位信息。这种方法避免了直接处理3DGS表示的复杂性,并且可以利用现有的2D视觉定位模型和数据集。
技术框架:GVR框架主要包含以下几个阶段:1) 视图生成:从3DGS场景中渲染多个不同视角的2D图像。2) 视图检索:使用文本提示作为查询,从渲染的2D图像中检索出与文本描述最相关的视图。3) 2D定位:在检索到的2D视图中使用2D视觉定位模型定位目标物体。4) 3D投影:将2D定位结果投影回3D场景中,得到3D物体的定位结果。
关键创新:GVR的关键创新在于将3D视觉定位问题转化为2D视图检索问题,从而避免了直接处理3DGS表示的复杂性。此外,GVR利用多视角信息来提高定位的准确性,并且实现了零样本的3D视觉定位,无需任何3D标注数据或逐场景训练。
关键设计:GVR的关键设计包括:1) 使用预训练的CLIP模型来提取文本和图像的特征,用于视图检索。2) 使用余弦相似度来衡量文本和图像特征之间的相似度。3) 使用现有的2D视觉定位模型,如Grounding DINO,来在检索到的2D视图中定位目标物体。4) 使用相机参数将2D定位结果投影回3D场景中。
🖼️ 关键图片

📊 实验亮点
GVR在多个3D视觉定位数据集上取得了最先进的性能,并且无需任何3D标注数据或逐场景训练。实验结果表明,GVR在ScanRefer数据集上相比于之前的最佳方法,在zero-shot setting下取得了显著的性能提升。GVR的性能提升主要归功于其有效的视图检索策略和多视角信息融合。
🎯 应用场景
GVR具有广泛的应用前景,例如机器人导航、增强现实和虚拟现实等领域。在机器人导航中,GVR可以帮助机器人理解人类的指令,并在3D环境中定位目标物体。在增强现实和虚拟现实中,GVR可以实现基于文本描述的3D物体交互,提升用户体验。此外,GVR还可以应用于3D场景理解、智能家居等领域,具有重要的实际价值和未来影响。
📄 摘要(原文)
3D Visual Grounding (3DVG) aims to locate objects in 3D scenes based on text prompts, which is essential for applications such as robotics. However, existing 3DVG methods encounter two main challenges: first, they struggle to handle the implicit representation of spatial textures in 3D Gaussian Splatting (3DGS), making per-scene training indispensable; second, they typically require larges amounts of labeled data for effective training. To this end, we propose \underline{G}rounding via \underline{V}iew \underline{R}etrieval (GVR), a novel zero-shot visual grounding framework for 3DGS to transform 3DVG as a 2D retrieval task that leverages object-level view retrieval to collect grounding clues from multiple views, which not only avoids the costly process of 3D annotation, but also eliminates the need for per-scene training. Extensive experiments demonstrate that our method achieves state-of-the-art visual grounding performance while avoiding per-scene training, providing a solid foundation for zero-shot 3DVG research. Video demos can be found in https://github.com/leviome/GVR_demos.