Pyramid Token Pruning for High-Resolution Large Vision-Language Models via Region, Token, and Instruction-Guided Importance
作者: Yuxuan Liang, Xu Li, Xiaolei Chen, Yi Zheng, Haotian Chen, Bin Li, Xiangyang Xue
分类: cs.CV
发布日期: 2025-09-19 (更新: 2025-09-29)
💡 一句话要点
提出金字塔Token剪枝(PTP)策略,解决高分辨率大视觉语言模型中计算开销过大的问题。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 视觉语言模型 Token剪枝 高分辨率图像 视觉显著性 指令引导 模型优化 计算效率
📋 核心要点
- 高分辨率图像输入导致视觉token数量激增,成为大型视觉语言模型(LVLMs)推理开销的主要瓶颈。
- 论文提出金字塔Token剪枝(PTP)策略,结合视觉显著性和指令相关性,选择性保留重要token。
- 实验表明,PTP能显著降低计算成本和推理延迟,同时保持甚至略微提升模型性能。
📝 摘要(中文)
大型视觉语言模型(LVLMs)最近展现出强大的多模态理解能力,但其细粒度的视觉感知通常受到低输入分辨率的限制。一种常见的补救方法是将高分辨率图像分割成多个子图像进行单独编码,但这会急剧增加视觉token的数量,并带来巨大的推理开销。为了克服这一挑战,我们提出金字塔Token剪枝(PTP),这是一种无需训练的策略,它以分层方式整合自下而上的区域和token级别的视觉显著性,以及自上而下的指令引导相关性。受到人类视觉认知的启发,PTP选择性地保留来自显著区域的更多token,同时进一步强调与任务指令最相关的token。在13个不同的基准测试上的大量实验表明,PTP在计算成本、内存使用和推理延迟方面显著降低,而性能下降可忽略不计。
🔬 方法详解
问题定义:现有的大型视觉语言模型在处理高分辨率图像时,通常采用将图像分割成多个子图像的方式,这导致视觉token数量爆炸式增长,显著增加了计算成本和推理延迟。现有的token剪枝方法可能无法有效区分重要和不重要的token,导致性能下降。
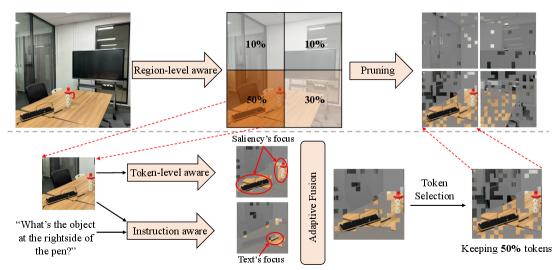
核心思路:论文的核心思路是模拟人类视觉认知过程,即首先关注图像中的显著区域,然后根据任务指令关注与任务相关的特定token。通过结合自下而上的视觉显著性和自上而下的指令引导,选择性地保留重要的token,从而降低计算开销。
技术框架:PTP包含三个主要阶段:1) 区域显著性评估:使用预训练的显著性检测模型识别图像中的显著区域。2) Token显著性评估:在每个区域内,基于token的视觉特征计算token的显著性得分。3) 指令引导相关性评估:利用语言指令,计算每个token与指令的相关性得分。最后,综合考虑区域显著性、token显著性和指令相关性,对token进行剪枝。
关键创新:PTP的关键创新在于将视觉显著性和指令相关性相结合,实现更有效的token剪枝。与传统的token剪枝方法相比,PTP能够更好地保留与任务相关的关键信息,从而在降低计算成本的同时保持甚至提升模型性能。此外,PTP是一种无需训练的策略,易于集成到现有的LVLM中。
关键设计:PTP的关键设计包括:1) 使用预训练的显著性检测模型(例如,SALNet)提取区域显著性。2) 使用token的视觉特征(例如,Transformer层的输出)计算token显著性得分。3) 使用指令的embedding和token的视觉特征计算指令相关性得分。4) 使用加权平均的方式综合三个得分,并根据设定的阈值进行token剪枝。具体权重参数的选择需要根据实验结果进行调整。
🖼️ 关键图片


📊 实验亮点
在13个不同的基准测试上,PTP在计算成本、内存使用和推理延迟方面显著降低,而性能下降可忽略不计。例如,在某些任务上,PTP可以将推理速度提高2倍以上,同时保持与原始模型相当的性能。此外,PTP在一些任务上甚至略微提升了模型性能,这表明PTP能够有效地保留与任务相关的关键信息。
🎯 应用场景
该研究成果可广泛应用于需要处理高分辨率图像的视觉语言任务中,例如图像描述、视觉问答、目标检测等。通过降低计算成本和推理延迟,PTP能够使LVLM在资源受限的设备上运行,并加速模型的部署和应用。此外,该方法还可以应用于视频理解等领域,提高模型的效率和可扩展性。
📄 摘要(原文)
Large Vision-Language Models (LVLMs) have recently demonstrated strong multimodal understanding, yet their fine-grained visual perception is often constrained by low input resolutions. A common remedy is to partition high-resolution images into multiple sub-images for separate encoding, but this approach drastically inflates the number of visual tokens and introduces prohibitive inference overhead. To overcome this challenge, we propose Pyramid Token Pruning (PTP), a training-free strategy that hierarchically integrates bottom-up visual saliency at both region and token levels with top-down instruction-guided relevance. Inspired by human visual cognition, PTP selectively preserves more tokens from salient regions while further emphasizing those most relevant to task instructions. Extensive experiments on 13 diverse benchmarks show that PTP substantially reduces computational cost, memory usage, and inference latency, with negligible performance degradation.