GS-Scale: Unlocking Large-Scale 3D Gaussian Splatting Training via Host Offloading
作者: Donghyun Lee, Dawoon Jeong, Jae W. Lee, Hongil Yoon
分类: cs.CV
发布日期: 2025-09-19
💡 一句话要点
GS-Scale:通过主机卸载解锁大规模3D高斯溅射训练
🎯 匹配领域: 支柱三:空间感知与语义 (Perception & Semantics)
关键词: 3D高斯溅射 大规模场景 主机卸载 GPU内存优化 渲染 视锥剔除 优化器更新
📋 核心要点
- 现有3D高斯溅射方法在大规模场景训练时,面临GPU内存需求过高的挑战,限制了模型质量和场景复杂度。
- GS-Scale通过将高斯参数存储在主机内存中,并按需传输到GPU,显著降低了GPU内存占用。
- GS-Scale通过选择性卸载、参数转发和延迟更新等优化,在降低GPU内存的同时,保持了与GPU相当的训练速度,并提升了LPIPS指标。
📝 摘要(中文)
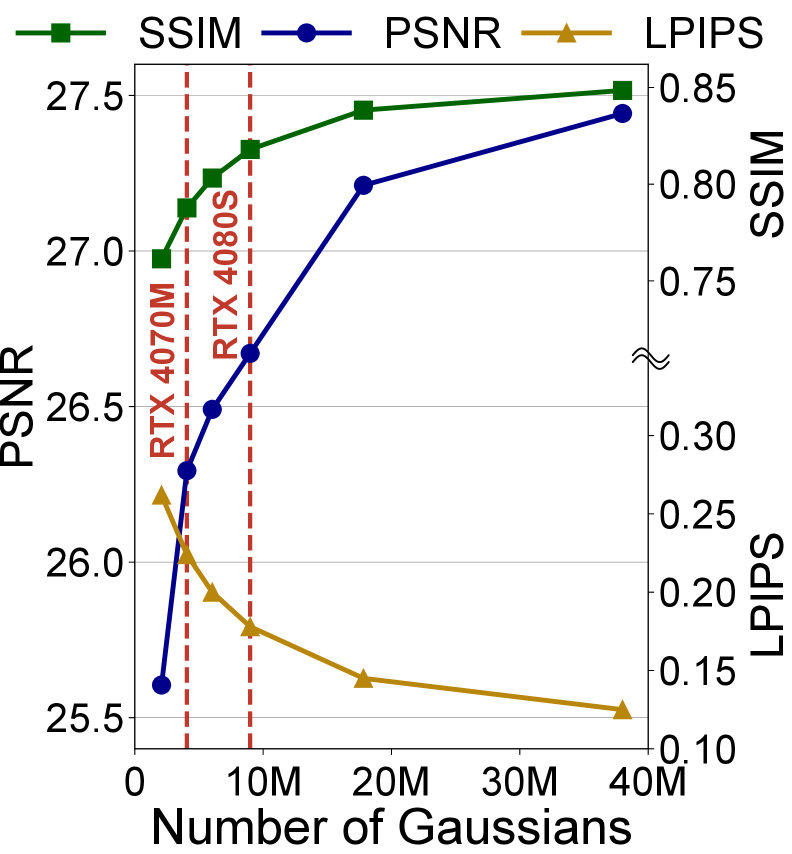
3D高斯溅射通过提供高质量的视觉效果和快速的渲染速度,彻底改变了图形渲染。然而,由于存储参数、梯度和优化器状态需要大量的内存,这会迅速耗尽GPU内存,因此高质量地训练大规模场景仍然具有挑战性。为了解决这些限制,我们提出了GS-Scale,一个快速且内存高效的3D高斯溅射训练系统。GS-Scale将所有高斯分布存储在主机内存中,仅在每次前向和后向传递时按需将一个子集传输到GPU。虽然这显著降低了GPU内存使用量,但它需要视锥剔除和优化器更新在CPU上执行,由于CPU有限的计算和内存带宽,这会导致速度减慢。为了缓解这个问题,GS-Scale采用了三个系统级优化:(1)选择性地卸载几何参数以实现快速视锥剔除,(2)参数转发以流水线化CPU优化器更新与GPU计算,以及(3)延迟优化器更新以最小化对梯度为零的高斯分布的不必要内存访问。我们对大规模数据集的广泛评估表明,GS-Scale显著降低了3.3-5.6倍的GPU内存需求,同时实现了与没有主机卸载的GPU相当的训练速度。这使得在消费级GPU上进行大规模3D高斯溅射训练成为可能;例如,GS-Scale可以在RTX 4070 Mobile GPU上将高斯分布的数量从400万扩展到1800万,从而实现23-35%的LPIPS(学习的感知图像块相似度)提升。
🔬 方法详解
问题定义:现有3D高斯溅射方法在训练大规模场景时,需要消耗大量的GPU内存,用于存储高斯参数、梯度和优化器状态。这限制了模型能够处理的场景规模和复杂度,尤其是在消费级GPU上。现有方法难以在保证训练速度的同时,降低GPU内存占用。
核心思路:GS-Scale的核心思路是将所有高斯参数存储在主机(CPU)内存中,仅在需要时将一部分数据传输到GPU进行计算。通过这种方式,可以显著降低GPU内存占用,从而支持更大规模的场景训练。同时,为了弥补CPU计算速度较慢的缺点,GS-Scale采用了多种系统级优化策略。
技术框架:GS-Scale的整体框架包括以下几个主要阶段:1. 数据准备:将所有高斯参数存储在主机内存中。2. 视锥剔除:在CPU上进行视锥剔除,筛选出需要参与渲染的高斯分布。为了加速视锥剔除,选择性地将几何参数卸载到CPU。3. 前向传播:将筛选出的高斯参数从主机内存传输到GPU,进行前向传播计算。4. 反向传播:在GPU上进行反向传播计算,得到梯度。5. 优化器更新:在CPU上进行优化器更新。为了流水线化CPU优化器更新与GPU计算,采用参数转发策略。为了减少不必要的内存访问,采用延迟优化器更新策略,只更新梯度不为零的高斯分布。
关键创新:GS-Scale的关键创新在于:1. 主机卸载:将高斯参数存储在主机内存中,按需传输到GPU,显著降低GPU内存占用。2. 选择性卸载:选择性地将几何参数卸载到CPU,加速视锥剔除。3. 参数转发:流水线化CPU优化器更新与GPU计算,提高训练效率。4. 延迟更新:只更新梯度不为零的高斯分布,减少不必要的内存访问。
关键设计:GS-Scale的关键设计包括:1. 内存管理:高效地管理主机内存和GPU内存之间的数据传输。2. 视锥剔除算法:选择合适的视锥剔除算法,在保证精度的前提下,提高剔除速度。3. 参数转发机制:设计高效的参数转发机制,保证CPU和GPU之间的数据同步。4. 延迟更新策略:合理设置延迟更新的阈值,避免过度更新或更新不足。
🖼️ 关键图片


📊 实验亮点
GS-Scale在大型数据集上进行了广泛的评估,结果表明,GS-Scale能够显著降低GPU内存需求,降低幅度达到3.3-5.6倍,同时保持与GPU相当的训练速度。例如,在RTX 4070 Mobile GPU上,GS-Scale可以将高斯分布的数量从400万扩展到1800万,从而实现23-35%的LPIPS提升。
🎯 应用场景
GS-Scale的应用场景广泛,包括:大规模城市建模、虚拟现实/增强现实、游戏开发、自动驾驶等。该研究的实际价值在于降低了3D高斯溅射训练的硬件门槛,使得更多开发者能够在消费级GPU上训练高质量的大规模3D场景。未来,GS-Scale有望推动3D高斯溅射技术在更多领域的应用。
📄 摘要(原文)
The advent of 3D Gaussian Splatting has revolutionized graphics rendering by delivering high visual quality and fast rendering speeds. However, training large-scale scenes at high quality remains challenging due to the substantial memory demands required to store parameters, gradients, and optimizer states, which can quickly overwhelm GPU memory. To address these limitations, we propose GS-Scale, a fast and memory-efficient training system for 3D Gaussian Splatting. GS-Scale stores all Gaussians in host memory, transferring only a subset to the GPU on demand for each forward and backward pass. While this dramatically reduces GPU memory usage, it requires frustum culling and optimizer updates to be executed on the CPU, introducing slowdowns due to CPU's limited compute and memory bandwidth. To mitigate this, GS-Scale employs three system-level optimizations: (1) selective offloading of geometric parameters for fast frustum culling, (2) parameter forwarding to pipeline CPU optimizer updates with GPU computation, and (3) deferred optimizer update to minimize unnecessary memory accesses for Gaussians with zero gradients. Our extensive evaluations on large-scale datasets demonstrate that GS-Scale significantly lowers GPU memory demands by 3.3-5.6x, while achieving training speeds comparable to GPU without host offloading. This enables large-scale 3D Gaussian Splatting training on consumer-grade GPUs; for instance, GS-Scale can scale the number of Gaussians from 4 million to 18 million on an RTX 4070 Mobile GPU, leading to 23-35% LPIPS (learned perceptual image patch similarity) improvement.