TennisTV: Do Multimodal Large Language Models Understand Tennis Rallies?
作者: Zhongyuan Bao, Lejun Zhang
分类: cs.CV
发布日期: 2025-09-19 (更新: 2026-01-18)
💡 一句话要点
TennisTV:首个网球视频理解基准,评估多模态大模型在快速运动场景下的性能
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 网球视频理解 多模态大模型 基准数据集 时间定位 运动视频分析
📋 核心要点
- 现有MLLM在通用视频理解表现良好,但在网球等快速运动视频理解方面存在挑战,缺乏针对性评估。
- 论文构建了TennisTV基准,将网球回合建模为击球事件序列,并设计了自动化的数据处理和问题生成流程。
- 通过对17个MLLM的评估,论文揭示了帧采样密度和时间定位对网球视频理解性能的关键影响。
📝 摘要(中文)
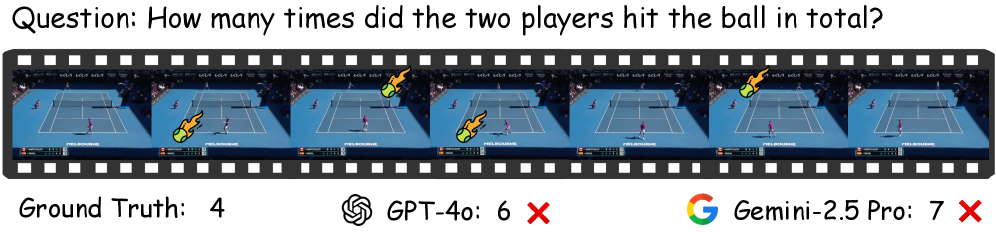
多模态大语言模型(MLLM)在通用视频理解方面表现出色,但在网球等快速、高频运动方面表现不佳,因为网球回合片段短小但信息密集。为了系统地评估MLLM在这个具有挑战性的领域中的性能,我们提出了TennisTV,这是第一个也是最全面的网球视频理解基准。TennisTV将每个回合建模为连续击球事件的时间序列,并使用自动管道进行过滤和问题生成。它涵盖了从击球级别到回合级别的8个任务,并包含2527个经过人工验证的问题。通过评估17个具有代表性的MLLM,我们提供了对网球视频理解的首次系统评估。结果表明两个关键见解:(i)帧采样密度应针对任务进行定制和平衡,以及(ii)改进时间定位对于更强的推理至关重要。
🔬 方法详解
问题定义:现有的多模态大语言模型在理解快速运动视频,特别是网球比赛视频时,面临着信息密度高、时间跨度短的挑战。缺乏专门针对网球视频理解的基准数据集,使得难以系统地评估和提升模型在该领域的性能。现有方法难以有效捕捉网球回合中快速变化的动作和策略信息。
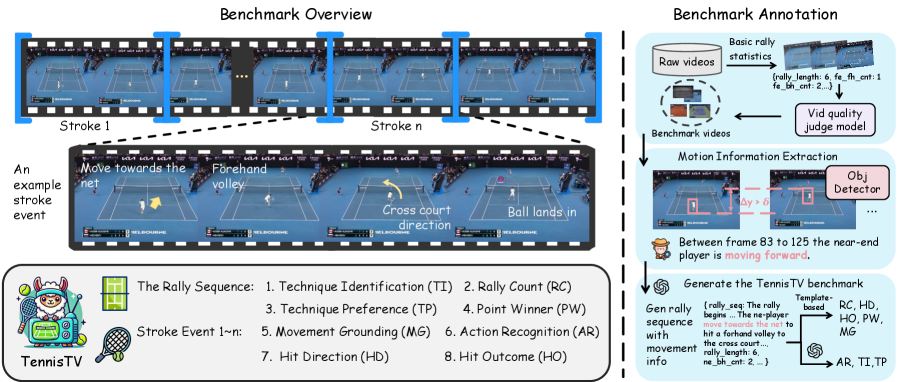
核心思路:论文的核心思路是构建一个专门用于评估多模态大语言模型在网球视频理解能力的基准数据集TennisTV。通过将网球回合分解为一系列连续的击球事件,并设计相应的任务和问题,来系统地评估模型对网球比赛的理解程度。这种方法能够更细粒度地分析模型的性能瓶颈,并指导模型优化。
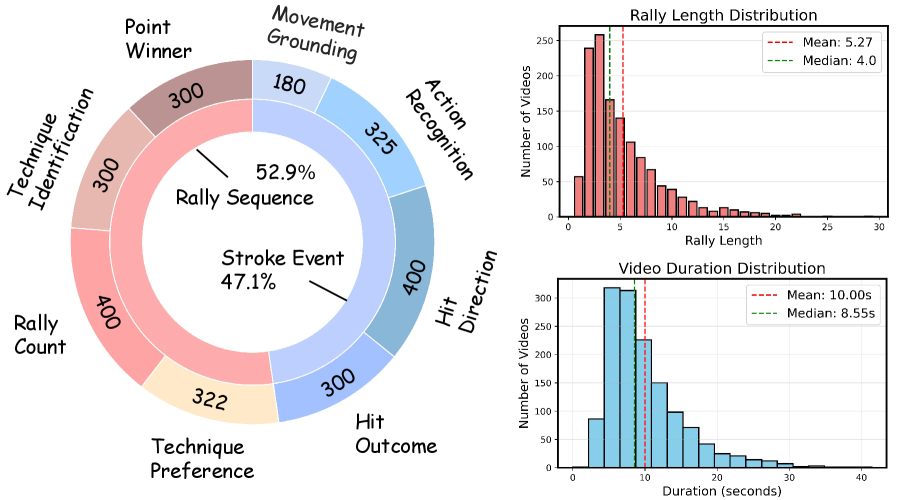
技术框架:TennisTV的构建流程主要包括以下几个阶段:1) 数据收集与过滤:利用自动化管道从网球视频中提取高质量的回合片段。2) 事件标注:将每个回合标注为一系列按时间顺序排列的击球事件。3) 问题生成:针对不同级别的理解任务(从击球级别到回合级别)自动生成问题。4) 人工验证:对生成的问题进行人工验证,确保问题的质量和相关性。整个框架旨在创建一个全面、高质量的网球视频理解基准。
关键创新:该论文的关键创新在于构建了首个专门针对网球视频理解的基准数据集TennisTV。与现有的通用视频理解基准相比,TennisTV更加关注快速运动场景下的细粒度动作理解和时间推理能力。此外,论文还提出了针对网球视频的自动化问题生成方法,大大提高了数据标注的效率。
关键设计:TennisTV包含8个任务,涵盖了从击球级别到回合级别的不同理解层次。问题类型包括选择题和开放式问题。在评估MLLM时,论文探索了不同的帧采样密度,并分析了时间定位对模型性能的影响。没有明确提及损失函数和网络结构等技术细节,但强调了帧采样密度和时间定位的重要性。
🖼️ 关键图片
📊 实验亮点
通过在TennisTV基准上评估17个MLLM,论文发现帧采样密度对不同任务的影响不同,需要进行针对性调整。实验还表明,提升模型的时间定位能力是提高网球视频理解性能的关键。这些发现为未来MLLM在运动视频理解方面的研究提供了重要的指导。
🎯 应用场景
该研究成果可应用于智能体育分析、运动员训练辅助、体育赛事直播增强等领域。通过提升AI对网球等运动视频的理解能力,可以为教练员和运动员提供更精准的战术分析和训练建议,同时也能为观众带来更丰富的观赛体验。未来,该技术有望推广到其他快速运动项目的视频分析中。
📄 摘要(原文)
Multimodal large language models (MLLMs) excel at general video understanding but struggle with fast, high-frequency sports like tennis, where rally clips are short yet information-dense. To systematically evaluate MLLMs in this challenging domain, we present TennisTV, the first and most comprehensive benchmark for tennis video understanding. TennisTV models each rally as a temporal-ordered sequence of consecutive stroke events, using automated pipelines for filtering and question generation. It covers 8 tasks from the stroke level to the rally level and includes 2527 human-verified questions. Evaluating 17 representative MLLMs, we provide the first systematic assessment of tennis video understanding. Results yield two key insights: (i) frame-sampling density should be tailored and balanced across tasks, and (ii) improving temporal grounding is essential for stronger reasoning.