Enhancing Sa2VA for Referent Video Object Segmentation: 2nd Solution for 7th LSVOS RVOS Track
作者: Ran Hong, Feng Lu, Leilei Cao, An Yan, Youhai Jiang, Fengjie Zhu
分类: cs.CV
发布日期: 2025-09-19
备注: 6 pages, 2 figures
💡 一句话要点
提出Video-Language Checker与Key-Frame Sampler,显著提升Sa2VA在指代表体视频分割任务上的性能
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 指代表体视频分割 视频语言理解 关键帧采样 视频内容分析 大型语言模型 Sa2VA 无监督学习
📋 核心要点
- 指代表体视频分割旨在根据自然语言描述分割视频中的所有匹配对象,现有方法如Sa2VA仍存在性能瓶颈。
- 本文提出视频-语言检查器和关键帧采样器,前者减少误报,后者捕捉关键信息,提升分割精度。
- 该方法无需额外训练,在MeViS测试集上J&F分数达到64.14%,在LSVOS RVOS赛道中排名第二。
📝 摘要(中文)
本文提出了一种无需额外训练的框架,用于显著提升Sa2VA在指代表体视频分割(RVOS)任务上的性能。该方法引入了两个关键组件:一是视频-语言检查器,用于显式验证查询中描述的主题和动作是否实际出现在视频中,从而减少误报;二是关键帧采样器,自适应地选择信息量大的帧,以更好地捕捉早期对象外观和长程时间上下文。在没有任何额外训练的情况下,我们的方法在MeViS测试集上实现了64.14%的J&F分数,在ICCV 2025第七届LSVOS挑战赛的RVOS赛道中排名第二。
🔬 方法详解
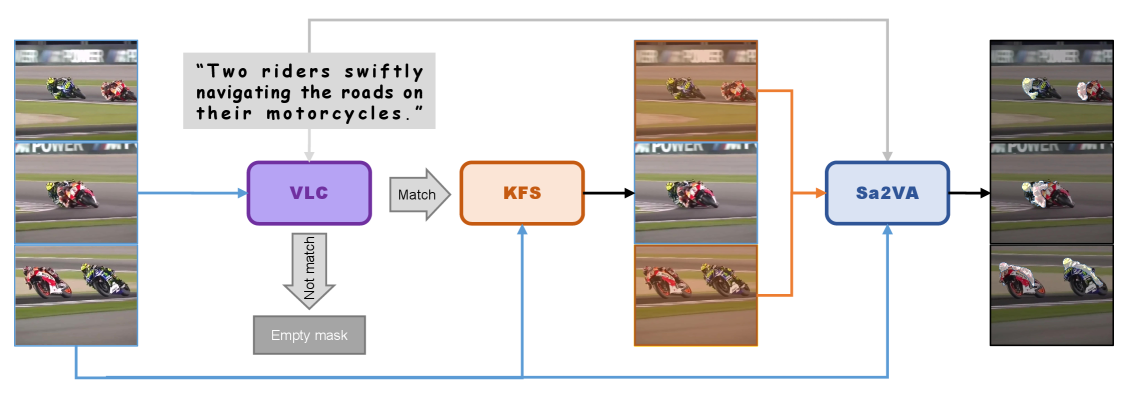
问题定义:指代表体视频分割(RVOS)旨在根据给定的自然语言描述,分割视频中所有符合描述的对象。现有方法,如Sa2VA,虽然利用了大型语言模型(LLMs)和SAM,但仍存在对视频内容理解不准确,导致误报,以及无法有效捕捉视频中的关键帧信息等问题。这些问题限制了RVOS的性能。
核心思路:本文的核心思路是通过引入视频-语言一致性检查和关键帧采样机制,来提升Sa2VA在RVOS任务上的性能。视频-语言检查器旨在确保语言描述与视频内容的一致性,减少因语言描述与视频内容不符而产生的误报。关键帧采样器则旨在选择最具代表性的帧,从而更好地捕捉对象的外观变化和长程时间依赖关系。
技术框架:该框架主要包含两个核心模块:视频-语言检查器和关键帧采样器。首先,视频-语言检查器分析输入的视频和语言描述,判断描述的主题和动作是否在视频中实际出现。如果检查结果为否定,则降低该视频的置信度或直接排除。其次,关键帧采样器根据视频内容和语言描述,自适应地选择信息量大的帧。这些帧被用于后续的视频分割处理。最后,利用Sa2VA或其他分割模型对选定的关键帧进行分割,并整合分割结果,得到最终的RVOS结果。
关键创新:本文的关键创新在于提出了一个无需额外训练的框架,通过显式地验证视频内容与语言描述的一致性,以及自适应地选择关键帧,来显著提升Sa2VA在RVOS任务上的性能。与现有方法相比,该方法不需要额外的训练数据或复杂的模型调整,即可实现性能提升。
关键设计:视频-语言检查器可以使用预训练的视觉-语言模型(如CLIP)来计算视频帧和语言描述之间的相似度,并设定阈值来判断一致性。关键帧采样器可以基于帧之间的差异性、与语言描述的相关性等指标来选择关键帧。例如,可以使用光流法计算帧之间的运动信息,并选择运动幅度较大的帧作为关键帧。也可以使用语言模型对每一帧进行描述,并计算描述与原始语言描述之间的相似度,选择相似度较高的帧作为关键帧。具体参数设置和阈值需要根据实际数据集进行调整。
🖼️ 关键图片

📊 实验亮点
该方法在MeViS测试集上取得了显著的性能提升,J&F分数达到64.14%,在第七届LSVOS挑战赛的RVOS赛道中排名第二。该方法无需额外训练,即可显著提升Sa2VA的性能,具有很高的实用价值。实验结果表明,视频-语言检查器和关键帧采样器能够有效减少误报,并捕捉关键信息,从而提升分割精度。
🎯 应用场景
该研究成果可应用于智能视频监控、视频内容分析、人机交互等领域。例如,在智能视频监控中,可以根据自然语言描述快速定位和分割目标对象。在人机交互中,可以实现更自然、更智能的视频编辑和标注。未来,该技术有望进一步扩展到自动驾驶、机器人导航等领域。
📄 摘要(原文)
Referential Video Object Segmentation (RVOS) aims to segment all objects in a video that match a given natural language description, bridging the gap between vision and language understanding. Recent work, such as Sa2VA, combines Large Language Models (LLMs) with SAM~2, leveraging the strong video reasoning capability of LLMs to guide video segmentation. In this work, we present a training-free framework that substantially improves Sa2VA's performance on the RVOS task. Our method introduces two key components: (1) a Video-Language Checker that explicitly verifies whether the subject and action described in the query actually appear in the video, thereby reducing false positives; and (2) a Key-Frame Sampler that adaptively selects informative frames to better capture both early object appearances and long-range temporal context. Without any additional training, our approach achieves a J&F score of 64.14% on the MeViS test set, ranking 2nd place in the RVOS track of the 7th LSVOS Challenge at ICCV 2025.