Lynx: Towards High-Fidelity Personalized Video Generation
作者: Shen Sang, Tiancheng Zhi, Tianpei Gu, Jing Liu, Linjie Luo
分类: cs.CV
发布日期: 2025-09-19
备注: Lynx Technical Report
💡 一句话要点
Lynx:基于单张图像的高保真个性化视频生成模型
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 个性化视频生成 Diffusion Transformer 身份保持 VAE 交叉注意力
📋 核心要点
- 现有方法在个性化视频生成中难以兼顾身份保持、时间连贯性和视觉真实感,尤其是在单张参考图像的条件下。
- Lynx通过ID-adapter和Ref-adapter两个轻量级模块,分别从身份嵌入和参考图像的VAE特征中提取信息,增强身份保真度。
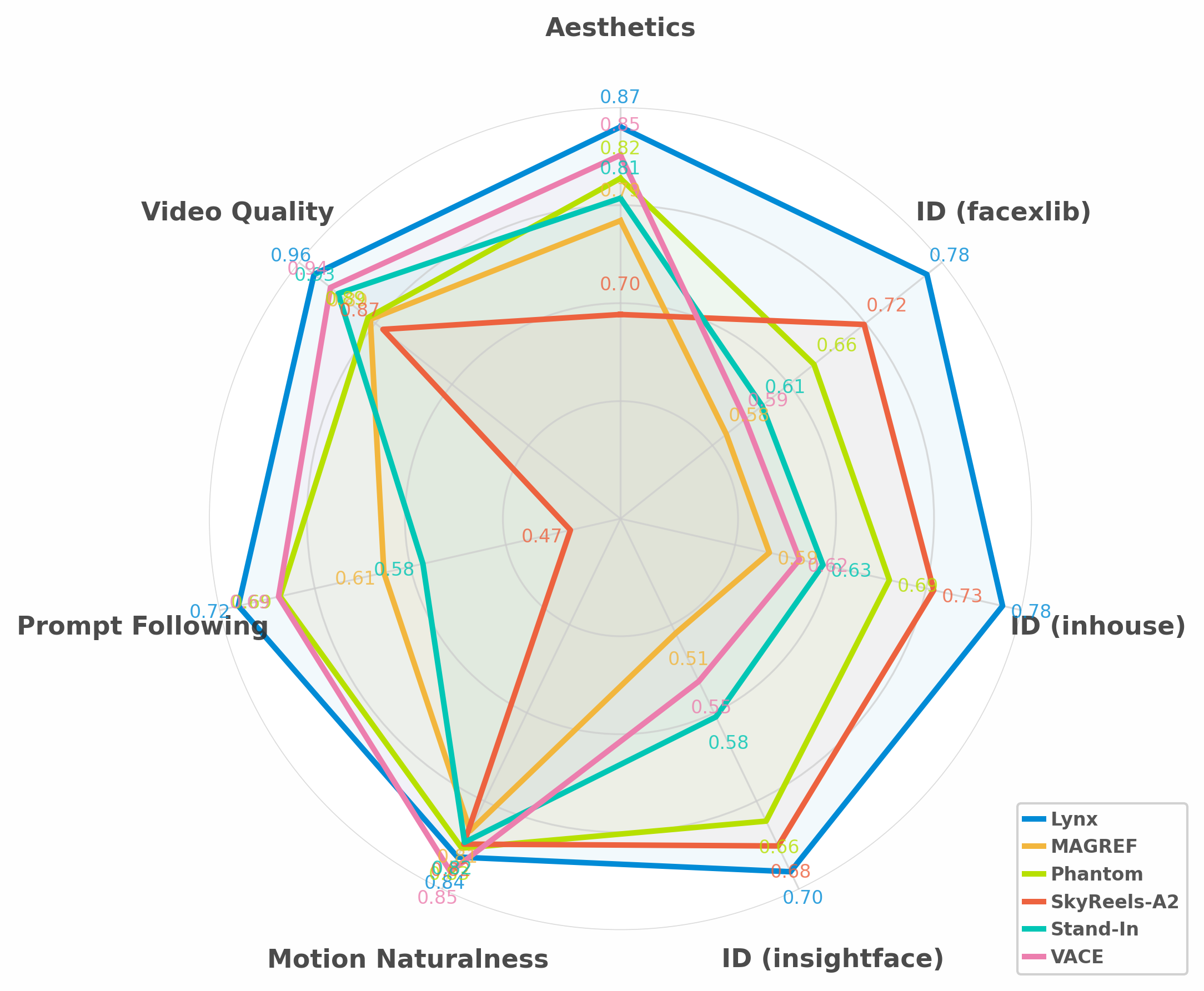
- 实验结果表明,Lynx在面部相似度、提示遵循和视频质量方面均优于现有方法,实现了高质量的个性化视频生成。
📝 摘要(中文)
本文提出Lynx,一个基于单张输入图像的高保真个性化视频合成模型。Lynx构建于开源的Diffusion Transformer (DiT) 基础模型之上,引入了两个轻量级的适配器以确保身份保真度。ID-adapter采用Perceiver Resampler将ArcFace提取的面部嵌入转换为紧凑的身份tokens用于条件控制;Ref-adapter则集成了来自冻结参考路径的密集VAE特征,通过交叉注意力在所有Transformer层中注入细粒度的细节。这些模块共同实现了鲁棒的身份保持,同时维持了时间一致性和视觉真实感。在包含40个对象和20个无偏提示的benchmark上(共800个测试用例)的评估表明,Lynx在面部相似度、提示遵循和视频质量方面表现出色,从而推动了个性化视频生成技术的发展。
🔬 方法详解
问题定义:论文旨在解决单张图像个性化视频生成中身份保持、时间连贯性和视觉真实感难以兼顾的问题。现有方法通常难以在保持身份信息的同时,生成高质量、时间连贯的视频内容,尤其是在参考图像信息有限的情况下。
核心思路:论文的核心思路是利用Diffusion Transformer (DiT) 作为基础模型,并通过引入两个轻量级的适配器(ID-adapter和Ref-adapter)来增强身份保真度。ID-adapter负责从人脸嵌入中提取身份信息,Ref-adapter负责从参考图像中提取细节信息。这样既能利用DiT强大的生成能力,又能保证生成视频的个性化特征。
技术框架:Lynx的整体框架基于Diffusion Transformer (DiT)。首先,使用ArcFace模型提取输入图像的面部嵌入。然后,ID-adapter利用Perceiver Resampler将面部嵌入转换为紧凑的身份tokens。同时,Ref-adapter使用一个冻结的VAE模型提取参考图像的密集特征。最后,ID tokens和VAE特征通过交叉注意力机制注入到DiT的各个Transformer层中,指导视频生成过程。
关键创新:论文的关键创新在于ID-adapter和Ref-adapter的设计。ID-adapter使用Perceiver Resampler有效地将高维人脸嵌入压缩为少量tokens,降低了计算复杂度。Ref-adapter通过冻结的VAE提取参考图像的细节信息,避免了对VAE的微调,保证了生成视频的细节质量。
关键设计:ID-adapter使用Perceiver Resampler将256维的ArcFace嵌入压缩为16个tokens。Ref-adapter使用的VAE模型是预训练好的,并且在训练过程中保持冻结。交叉注意力机制被应用在DiT的每一层,以融合ID tokens和VAE特征。损失函数包括L1损失和LPIPS损失,用于优化生成视频的质量。
🖼️ 关键图片


📊 实验亮点
Lynx在包含40个对象和20个无偏提示的benchmark上进行了评估,共计800个测试用例。实验结果表明,Lynx在面部相似度(Face Resemblance)、提示遵循(Prompt Following)和视频质量(Video Quality)方面均优于现有方法。具体而言,Lynx在面部相似度指标上取得了显著提升,表明其能够更好地保持生成视频中人物的身份信息。
🎯 应用场景
Lynx技术可应用于虚拟形象生成、影视娱乐、游戏开发、社交媒体等领域。用户可以通过上传一张照片,快速生成个性化的视频内容,例如制作个人短片、定制游戏角色、创建虚拟社交形象等。该技术具有广泛的应用前景,有望提升内容创作的效率和个性化水平。
📄 摘要(原文)
We present Lynx, a high-fidelity model for personalized video synthesis from a single input image. Built on an open-source Diffusion Transformer (DiT) foundation model, Lynx introduces two lightweight adapters to ensure identity fidelity. The ID-adapter employs a Perceiver Resampler to convert ArcFace-derived facial embeddings into compact identity tokens for conditioning, while the Ref-adapter integrates dense VAE features from a frozen reference pathway, injecting fine-grained details across all transformer layers through cross-attention. These modules collectively enable robust identity preservation while maintaining temporal coherence and visual realism. Through evaluation on a curated benchmark of 40 subjects and 20 unbiased prompts, which yielded 800 test cases, Lynx has demonstrated superior face resemblance, competitive prompt following, and strong video quality, thereby advancing the state of personalized video generation.