Comparing Computational Pathology Foundation Models using Representational Similarity Analysis
作者: Vaibhav Mishra, William Lotter
分类: cs.CV, cs.AI
发布日期: 2025-09-18 (更新: 2025-11-05)
备注: Proceedings of the 5th Machine Learning for Health (ML4H) Symposium
💡 一句话要点
利用表征相似性分析比较计算病理学中的多个预训练模型
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 计算病理学 预训练模型 表征相似性分析 深度学习 医学影像
📋 核心要点
- 现有计算病理学预训练模型缺乏对其学习表征结构和变异性的深入理解,阻碍了模型选择和优化。
- 论文采用表征相似性分析(RSA)方法,系统比较了六个主流CPath预训练模型的表征空间,揭示其内在结构。
- 实验发现不同模型表征差异显著,且普遍存在切片依赖性,染色标准化可有效降低该依赖性。
📝 摘要(中文)
计算病理学(CPath)中的预训练模型因其在促进下游任务方面的潜力而得到越来越多的发展。尽管最近的研究评估了不同模型的任务性能,但对其学习表征的结构和变异性知之甚少。本文系统地分析了六个CPath预训练模型的表征空间,使用了计算神经科学中流行的技术。分析的模型涵盖了视觉-语言对比学习(CONCH、PLIP、KEEP)和自蒸馏(UNI (v2)、Virchow (v2)、Prov-GigaPath)方法。通过使用来自TCGA的H&E图像块进行表征相似性分析,发现UNI2和Virchow2具有最独特的表征结构,而Prov-Gigapath在模型中具有最高的平均相似性。具有相同的训练范式(仅视觉与视觉-语言)并不能保证更高的表征相似性。所有模型的表征都表现出高度的切片依赖性,但疾病依赖性相对较低。染色标准化降低了所有模型的切片依赖性,范围从5.5% (CONCH) 到 20.5% (PLIP)。在内在维度方面,与仅视觉模型更分散的表征相比,视觉-语言模型表现出相对紧凑的表征。这些发现突出了提高对切片特定特征的鲁棒性的机会,为模型集成策略提供了信息,并深入了解了训练范式如何塑造模型表征。我们的框架可以扩展到医学成像领域,在这些领域中,探测预训练模型的内部表征可以支持其有效开发和部署。
🔬 方法详解
问题定义:计算病理学领域涌现出大量预训练模型,但如何理解和比较这些模型的内部表征,以及如何利用这些理解来改进模型性能,是一个关键问题。现有方法主要关注下游任务的性能评估,缺乏对模型表征空间的系统分析,难以指导模型选择、集成和优化。
核心思路:论文的核心思路是利用表征相似性分析(RSA)这一来自计算神经科学的方法,来比较不同计算病理学预训练模型的表征空间。RSA通过计算不同模型对相同输入图像的表征向量之间的相似性,来衡量模型之间的表征相似程度。通过分析表征相似性矩阵,可以揭示模型之间的共性和差异,以及模型对不同类型图像的敏感程度。
技术框架:论文的技术框架主要包括以下几个步骤:1) 选择六个具有代表性的计算病理学预训练模型,涵盖视觉-语言对比学习和自蒸馏等不同训练范式。2) 使用来自TCGA的H&E染色病理图像块作为输入。3) 提取每个模型对每个图像块的表征向量。4) 计算所有模型对之间表征向量的相似性,构建表征相似性矩阵。5) 分析表征相似性矩阵,揭示模型之间的表征相似程度、切片依赖性和疾病依赖性。6) 实验染色标准化对表征相似性的影响。
关键创新:论文的关键创新在于将表征相似性分析这一方法引入到计算病理学预训练模型的研究中。通过RSA,可以深入理解模型的内部表征,揭示模型之间的共性和差异,以及模型对不同类型图像的敏感程度。这为模型选择、集成和优化提供了新的视角和依据。
关键设计:论文的关键设计包括:1) 选择具有代表性的预训练模型,涵盖不同训练范式。2) 使用来自TCGA的H&E染色病理图像块作为输入,保证了实验的可靠性和可重复性。3) 使用余弦相似度作为表征向量相似性的度量标准。4) 分析切片依赖性和疾病依赖性,揭示模型对不同类型图像的敏感程度。5) 实验染色标准化对表征相似性的影响,为提高模型的鲁棒性提供了指导。
🖼️ 关键图片
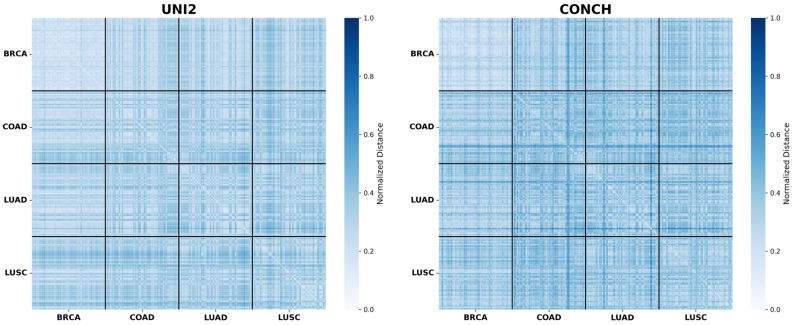
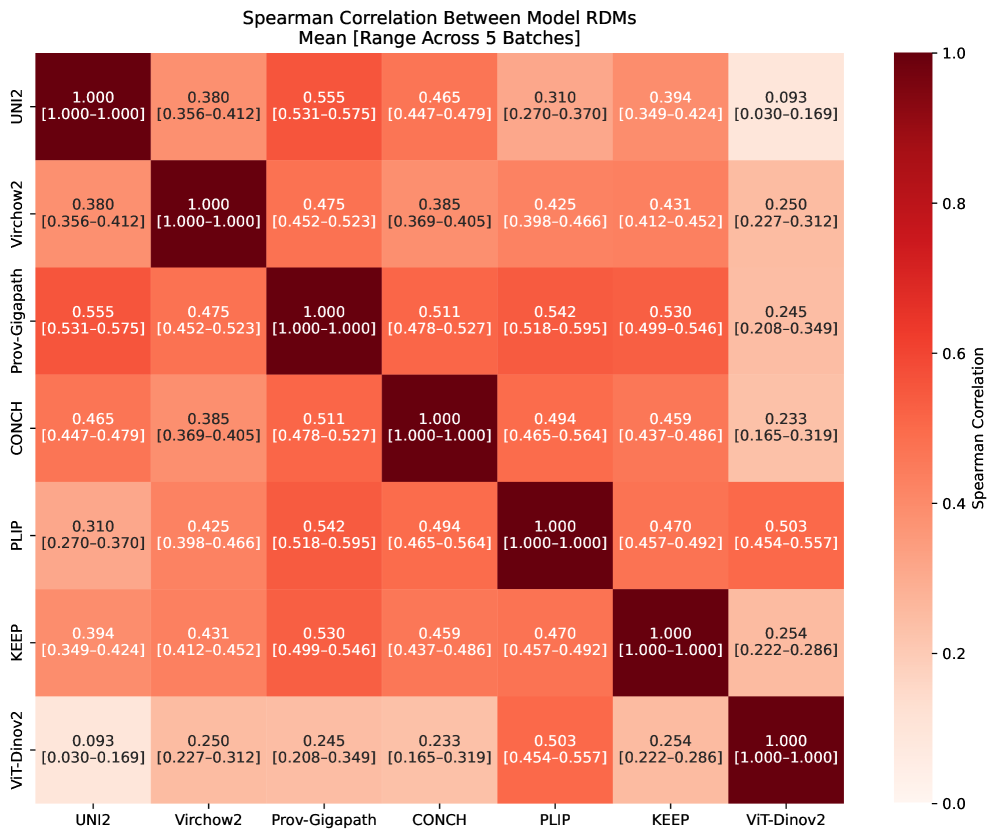
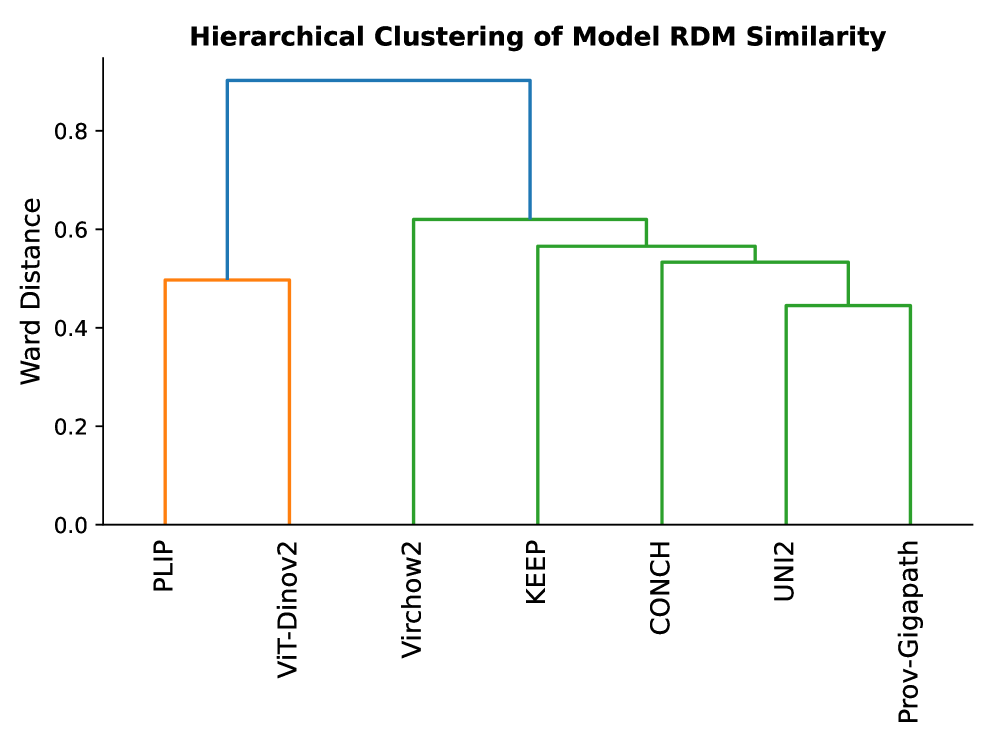
📊 实验亮点
实验结果表明,UNI2和Virchow2具有最独特的表征结构,而Prov-Gigapath具有最高的平均相似性。视觉-语言模型表现出相对紧凑的表征,而仅视觉模型则表现出更分散的表征。染色标准化可降低所有模型的切片依赖性,范围从5.5% (CONCH) 到 20.5% (PLIP)。
🎯 应用场景
该研究成果可应用于计算病理学模型的选择与集成,指导模型训练和优化,提高模型在病理诊断、预后预测等任务中的性能。通过分析模型表征空间,可以更好地理解模型的优势和局限性,从而选择合适的模型应用于特定任务。此外,该方法还可扩展到其他医学影像领域,促进医学影像预训练模型的发展和应用。
📄 摘要(原文)
Foundation models are increasingly developed in computational pathology (CPath) given their promise in facilitating many downstream tasks. While recent studies have evaluated task performance across models, less is known about the structure and variability of their learned representations. Here, we systematically analyze the representational spaces of six CPath foundation models using techniques popularized in computational neuroscience. The models analyzed span vision-language contrastive learning (CONCH, PLIP, KEEP) and self-distillation (UNI (v2), Virchow (v2), Prov-GigaPath) approaches. Through representational similarity analysis using H&E image patches from TCGA, we find that UNI2 and Virchow2 have the most distinct representational structures, whereas Prov-Gigapath has the highest average similarity across models. Having the same training paradigm (vision-only vs. vision-language) did not guarantee higher representational similarity. The representations of all models showed a high slide-dependence, but relatively low disease-dependence. Stain normalization decreased slide-dependence for all models by a range of 5.5% (CONCH) to 20.5% (PLIP). In terms of intrinsic dimensionality, vision-language models demonstrated relatively compact representations, compared to the more distributed representations of vision-only models. These findings highlight opportunities to improve robustness to slide-specific features, inform model ensembling strategies, and provide insights into how training paradigms shape model representations. Our framework is extendable across medical imaging domains, where probing the internal representations of foundation models can support their effective development and deployment.