ORCA: Agentic Reasoning For Hallucination and Adversarial Robustness in Vision-Language Models
作者: Chung-En Johnny Yu, Hsuan-Chih, Chen, Brian Jalaian, Nathaniel D. Bastian
分类: cs.CV, cs.AI, cs.MA
发布日期: 2025-09-18
💡 一句话要点
ORCA:通过Agentic推理提升视觉-语言模型在幻觉和对抗鲁棒性上的表现
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 视觉-语言模型 幻觉 对抗鲁棒性 Agentic推理 多模态学习
📋 核心要点
- 现有大型视觉-语言模型易受幻觉和对抗攻击影响,限制了其在实际应用中的可靠性。
- ORCA 采用 Agentic 推理框架,通过观察、推理、评论和行动循环,迭代优化预测结果。
- 实验表明,ORCA 在幻觉基准测试和对抗攻击场景下,均显著提升了模型的准确性和鲁棒性。
📝 摘要(中文)
大型视觉-语言模型(LVLMs)展现了强大的多模态能力,但仍然容易受到内在错误导致的幻觉以及外部攻击造成的对抗性影响,这限制了它们在现实应用中的可靠性。我们提出了ORCA,一个agentic推理框架,通过测试时结构化推理和一套小型视觉模型(小于30亿参数)来提高预训练LVLMs的事实准确性和对抗鲁棒性。ORCA通过观察-推理-评论-行动循环运行,使用证据性问题查询多个视觉工具,验证跨模型的不一致性,并迭代地改进预测,无需访问模型内部或重新训练。ORCA还存储中间推理轨迹,支持可审计的决策。虽然主要旨在减轻对象级别的幻觉,但ORCA也表现出涌现的对抗鲁棒性,而无需对抗训练或防御机制。我们在三种设置下评估ORCA:(1)干净图像上的幻觉基准测试,(2)没有防御的对抗扰动图像,以及(3)应用防御的对抗扰动图像。在POPE幻觉基准测试中,ORCA将独立LVLM的性能提高了+3.64%至+40.67%。在POPE上的对抗扰动下,ORCA在LVLM上的平均准确度提高了+20.11%。当与AMBER图像上对抗扰动的防御技术结合使用时,ORCA进一步提高了独立LVLM的性能,在评估指标上的增益范围为+1.20%至+48.00%。这些结果表明,ORCA为构建更可靠和鲁棒的多模态系统提供了一条有希望的途径。
🔬 方法详解
问题定义:大型视觉-语言模型(LVLMs)在处理多模态任务时,容易产生幻觉(hallucination),即生成与图像内容不符的信息。此外,LVLMs也容易受到对抗攻击,即通过对图像进行微小扰动,就能使模型产生错误的预测。现有方法通常需要大量的对抗训练或复杂的防御机制,成本较高且效果有限。
核心思路:ORCA的核心思路是利用多个小型视觉模型作为“专家”,通过Agentic推理的方式,对LVLM的输出进行验证和修正。类似于人类专家会互相质疑和验证信息,ORCA通过多个视觉模型的协同工作,减少LVLM的幻觉,并提高其对抗鲁棒性。这种方法无需访问LVLM的内部参数,也无需重新训练。
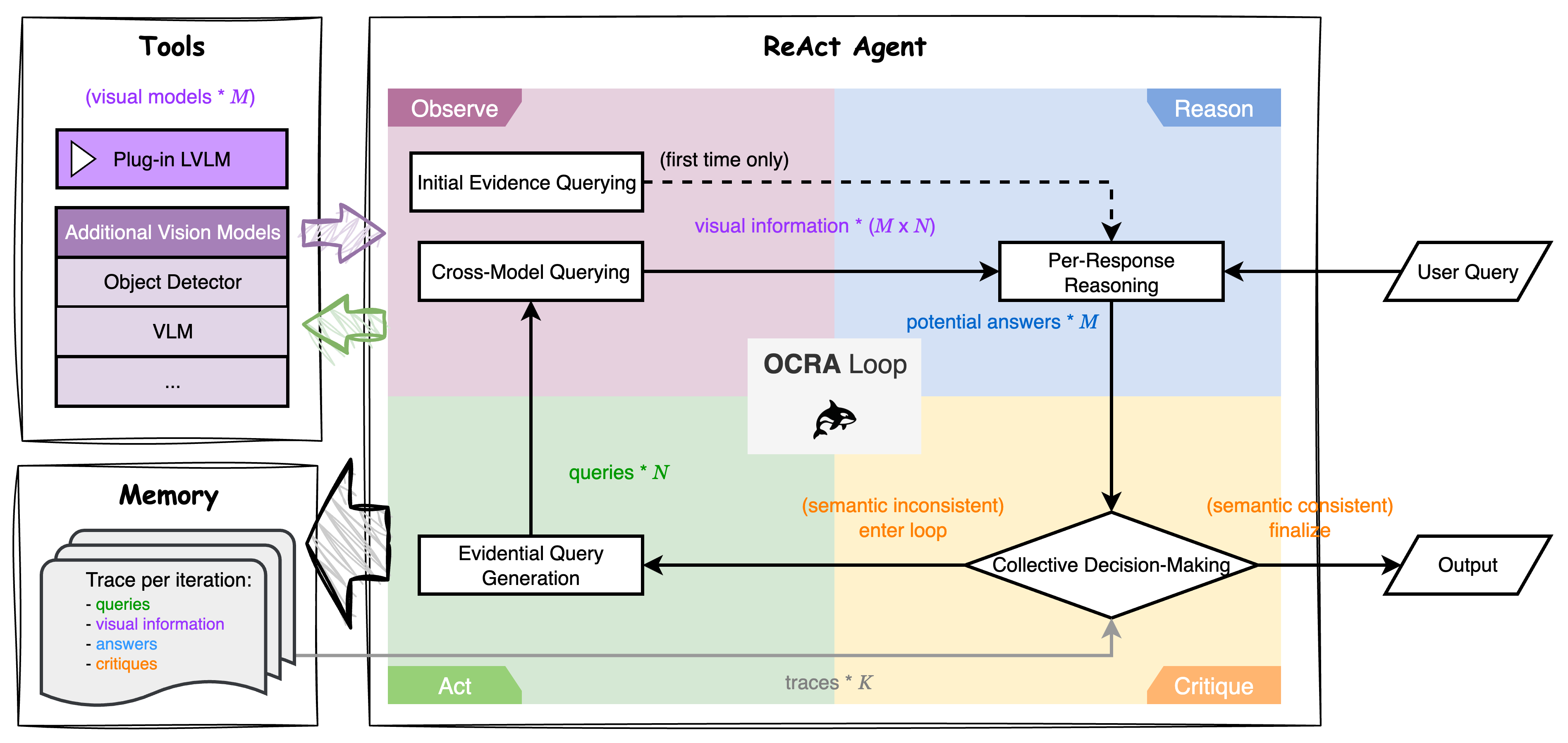
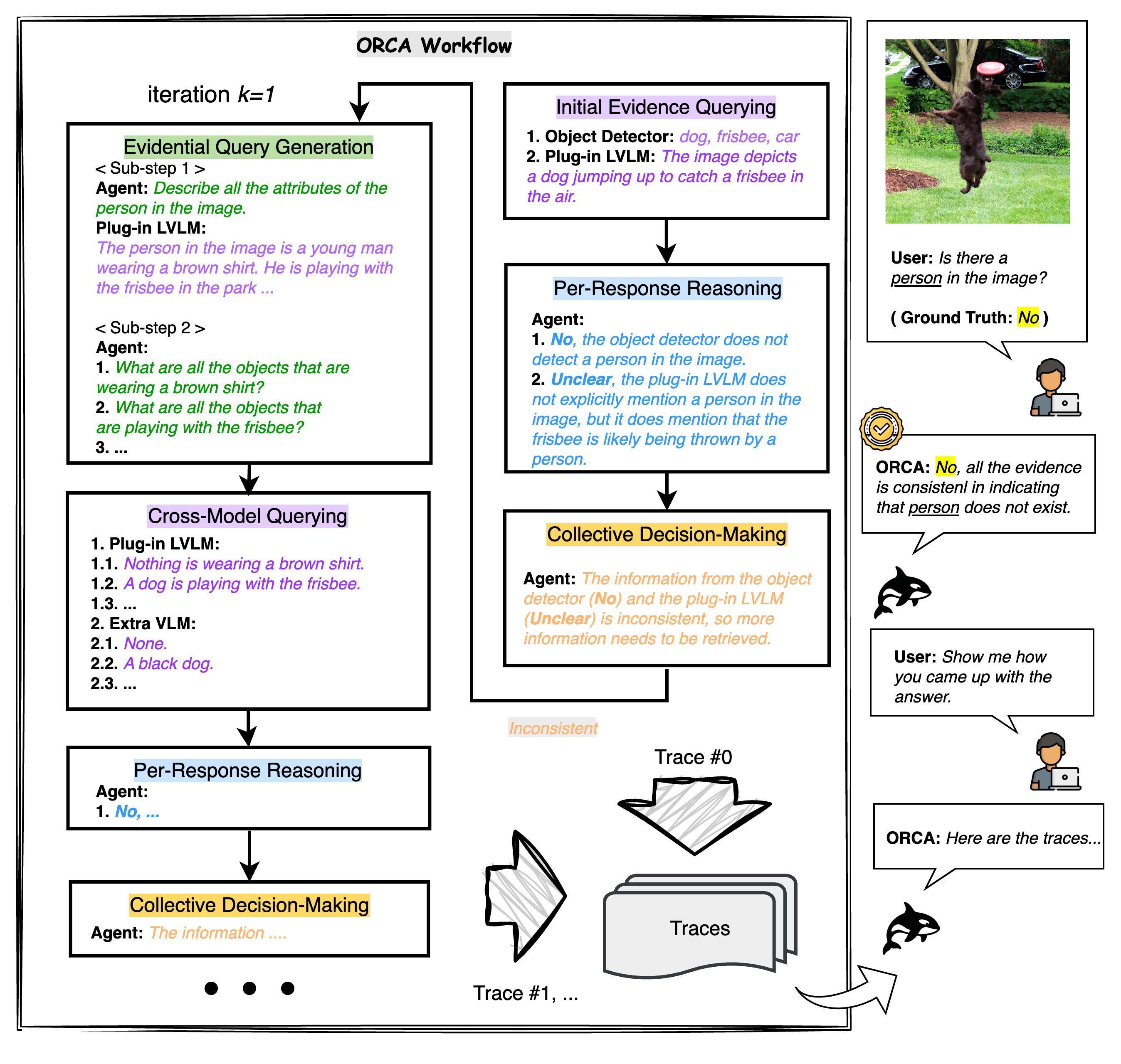
技术框架:ORCA的整体框架是一个Observe-Reason-Critique-Act循环。首先,Observe阶段使用LVLM生成初始预测。然后,Reason阶段使用一系列小型视觉模型(例如,目标检测、属性识别等)对图像进行分析,并生成证据性问题。Critique阶段比较LVLM的预测和视觉模型的分析结果,检测不一致性。最后,Act阶段根据Critique的结果,修正LVLM的预测。ORCA会记录中间推理过程,方便审计和调试。
关键创新:ORCA的关键创新在于其Agentic推理框架,它将多个小型视觉模型组合成一个专家系统,通过协同工作来提高LVLM的可靠性。与传统的对抗训练或防御机制不同,ORCA不需要修改LVLM的内部结构或参数,而是通过外部推理来提高其性能。此外,ORCA的推理过程是可解释的,可以追溯到每个视觉模型的输出,这有助于理解和调试模型。
关键设计:ORCA的关键设计包括:1) 选择合适的视觉模型作为“专家”,这些模型需要具有不同的视觉能力,例如目标检测、属性识别等。2) 设计合适的证据性问题,这些问题需要能够有效地验证LVLM的预测。3) 设计合适的Critique机制,能够准确地检测LVLM预测和视觉模型分析结果之间的不一致性。4) 设计合适的Act机制,能够根据Critique的结果,有效地修正LVLM的预测。具体参数设置和损失函数取决于所使用的视觉模型和任务。
🖼️ 关键图片

📊 实验亮点
实验结果表明,ORCA 在 POPE 幻觉基准测试中,将 LVLM 的性能提高了 3.64% 到 40.67%。在对抗扰动下,ORCA 使 LVLM 的平均准确度提高了 20.11%。结合防御技术后,ORCA 在 AMBER 图像上进一步提高了 LVLM 的性能,增益范围为 1.20% 到 48.00%。这些结果表明,ORCA 能够有效地减少 LVLM 的幻觉,并提高其对抗鲁棒性。
🎯 应用场景
ORCA 有潜力应用于各种需要高可靠性和鲁棒性的视觉-语言任务中,例如自动驾驶、医疗诊断、安全监控等。通过提高 LVLM 的准确性和可信度,ORCA 可以帮助人们更好地理解和利用多模态信息,从而做出更明智的决策。未来,ORCA 可以扩展到更多的视觉任务和语言模型,构建更强大的多模态智能系统。
📄 摘要(原文)
Large Vision-Language Models (LVLMs) exhibit strong multimodal capabilities but remain vulnerable to hallucinations from intrinsic errors and adversarial attacks from external exploitations, limiting their reliability in real-world applications. We present ORCA, an agentic reasoning framework that improves the factual accuracy and adversarial robustness of pretrained LVLMs through test-time structured inference reasoning with a suite of small vision models (less than 3B parameters). ORCA operates via an Observe--Reason--Critique--Act loop, querying multiple visual tools with evidential questions, validating cross-model inconsistencies, and refining predictions iteratively without access to model internals or retraining. ORCA also stores intermediate reasoning traces, which supports auditable decision-making. Though designed primarily to mitigate object-level hallucinations, ORCA also exhibits emergent adversarial robustness without requiring adversarial training or defense mechanisms. We evaluate ORCA across three settings: (1) clean images on hallucination benchmarks, (2) adversarially perturbed images without defense, and (3) adversarially perturbed images with defense applied. On the POPE hallucination benchmark, ORCA improves standalone LVLM performance by +3.64\% to +40.67\% across different subsets. Under adversarial perturbations on POPE, ORCA achieves an average accuracy gain of +20.11\% across LVLMs. When combined with defense techniques on adversarially perturbed AMBER images, ORCA further improves standalone LVLM performance, with gains ranging from +1.20\% to +48.00\% across evaluation metrics. These results demonstrate that ORCA offers a promising path toward building more reliable and robust multimodal systems.