Emulating Human-like Adaptive Vision for Efficient and Flexible Machine Visual Perception
作者: Yulin Wang, Yang Yue, Yang Yue, Huanqian Wang, Haojun Jiang, Yizeng Han, Zanlin Ni, Yifan Pu, Minglei Shi, Rui Lu, Qisen Yang, Andrew Zhao, Zhuofan Xia, Shiji Song, Gao Huang
分类: cs.CV, cs.AI, cs.LG, eess.IV
发布日期: 2025-09-18
🔗 代码/项目: GITHUB
💡 一句话要点
提出AdaptiveNN,通过模仿人类自适应视觉实现高效灵活的机器视觉感知
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 自适应视觉 强化学习 视觉感知 序列决策 高效计算
📋 核心要点
- 现有机器视觉模型被动处理整个场景,导致资源需求随分辨率和模型大小线性增长,限制了实际应用。
- AdaptiveNN模仿人类视觉,通过序列决策由粗到精关注任务相关区域,逐步整合信息并主动结束观察。
- 实验表明,AdaptiveNN在多种任务上实现了高达28倍的推理成本降低,同时保持或提升了准确率。
📝 摘要(中文)
人类视觉具有高度的适应性,通过顺序地注视任务相关的区域来高效地采样复杂环境。相比之下,目前流行的机器视觉模型被动地一次性处理整个场景,导致过度的资源需求,这种资源需求随着时空输入分辨率和模型大小的增加而增加,从而产生了阻碍未来发展和实际应用的关键限制。本文介绍了一种通用框架AdaptiveNN,旨在推动从“被动”到“主动、自适应”视觉模型的范式转变。AdaptiveNN将视觉感知构建为一个由粗到精的顺序决策过程,逐步识别和关注与任务相关的区域,逐步组合跨注视的信息,并在信息充足时主动结束观察。我们建立了一个将表征学习与自奖励强化学习相结合的理论,从而能够对不可微的AdaptiveNN进行端到端训练,而无需对注视位置进行额外的监督。我们在涵盖9项任务的17个基准上评估了AdaptiveNN,包括大规模视觉识别、细粒度判别、视觉搜索、处理来自真实驾驶和医疗场景的图像、语言驱动的具身AI,以及与人类的并排比较。AdaptiveNN在不牺牲准确性的前提下,实现了高达28倍的推理成本降低,灵活地适应不同的任务需求和资源预算而无需重新训练,并通过其注视模式提供了增强的可解释性,展示了通往高效、灵活和可解释的计算机视觉的有希望的途径。此外,AdaptiveNN在许多情况下表现出与人类非常相似的感知行为,揭示了其作为研究视觉认知的宝贵工具的潜力。
🔬 方法详解
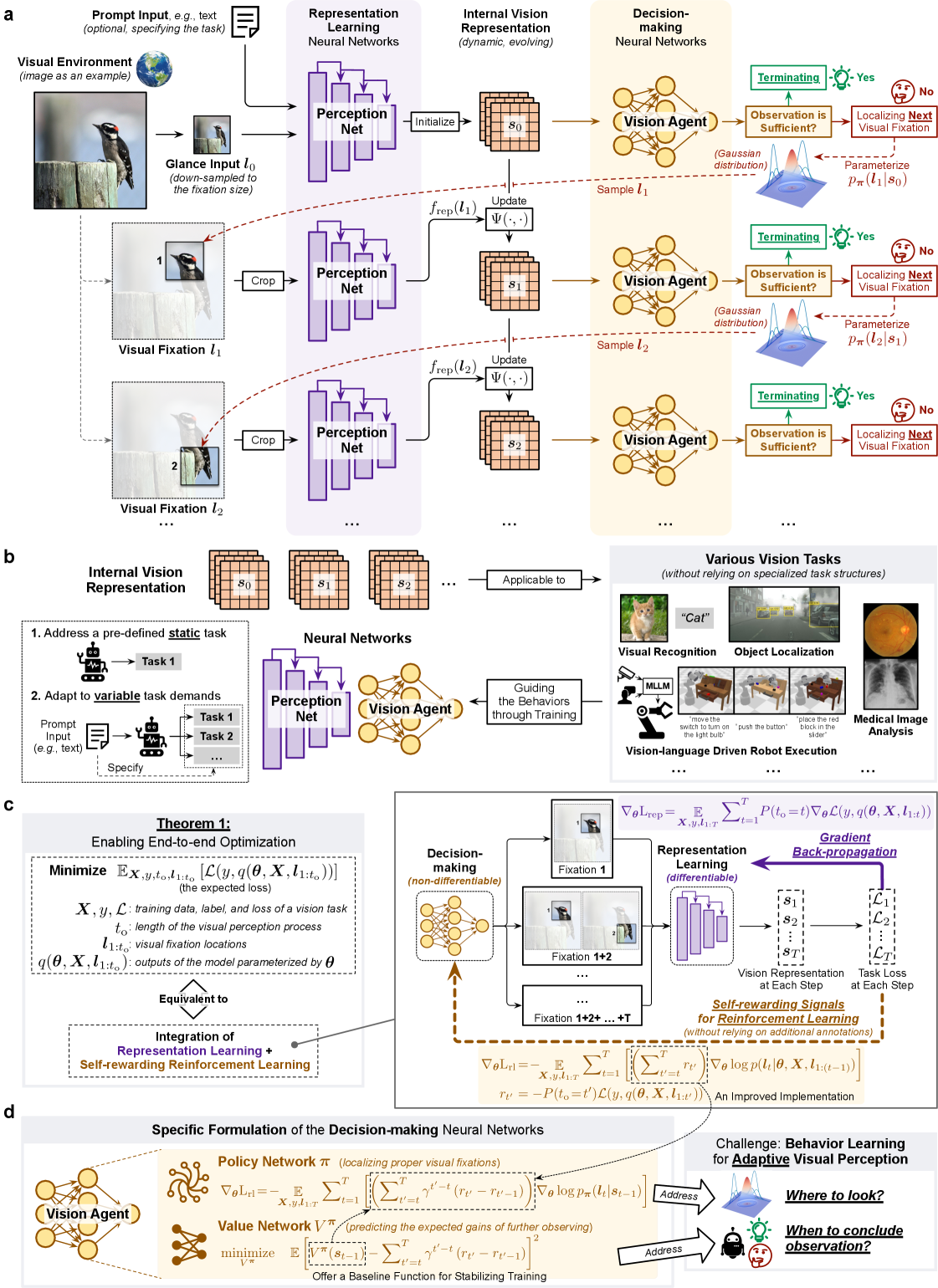
问题定义:现有机器视觉模型通常采用被动式处理方式,即一次性处理整个输入图像,计算量巨大,尤其是在高分辨率或视频场景下。这种方式忽略了人类视觉系统选择性关注重要区域的能力,导致资源浪费和效率低下。因此,需要一种更高效、更灵活的视觉感知方法,能够根据任务需求动态调整关注区域,降低计算成本。
核心思路:AdaptiveNN的核心思路是模仿人类视觉的自适应特性,将视觉感知过程建模为一个序列决策过程。模型通过一系列的“注视”(fixation)动作,逐步选择图像中的重要区域进行观察,并整合这些区域的信息。当模型认为已经获得了足够的信息时,就会主动结束观察,做出最终的判断。这种由粗到精、逐步聚焦的方式能够显著减少计算量,并提高模型的效率和灵活性。
技术框架:AdaptiveNN的整体框架包含以下几个主要模块:1) 表征学习模块:用于提取输入图像的特征表示。2) 注视策略网络:基于当前状态(已观察区域的特征和历史注视信息)决定下一个注视的位置。3) 信息整合模块:将每次注视获得的局部信息整合到全局表示中。4) 决策模块:基于全局表示做出最终的预测。整个过程通过强化学习进行训练,目标是最大化任务奖励并最小化计算成本。
关键创新:AdaptiveNN的关键创新在于将视觉感知建模为一个可学习的序列决策过程,并采用自奖励强化学习进行端到端训练。与传统的基于注意力机制的方法不同,AdaptiveNN不仅学习了如何关注重要区域,还学习了何时停止观察,从而实现了更高效的资源利用。此外,AdaptiveNN的训练过程不需要额外的注视位置监督信息,降低了数据标注的成本。
关键设计:AdaptiveNN的关键设计包括:1) 自奖励函数:结合了任务奖励(例如分类准确率)和计算成本惩罚,鼓励模型在保证性能的同时尽可能减少注视次数。2) 注视策略网络结构:采用循环神经网络(RNN)来建模注视序列的依赖关系。3) 信息整合方式:可以使用注意力机制或简单的特征拼接来整合不同注视区域的信息。4) ** coarse-to-fine 的区域选择策略**:从低分辨率开始,逐步聚焦到高分辨率区域。
🖼️ 关键图片


📊 实验亮点
AdaptiveNN在17个基准测试中表现出色,在不牺牲准确性的前提下,实现了高达28倍的推理成本降低。例如,在ImageNet数据集上,AdaptiveNN在保持相同准确率的情况下,显著减少了计算量。此外,AdaptiveNN在细粒度图像分类、视觉搜索等任务上也取得了优于传统方法的性能。与人类视觉行为的对比实验表明,AdaptiveNN在许多情况下表现出与人类相似的注视模式。
🎯 应用场景
AdaptiveNN具有广泛的应用前景,包括自动驾驶、医疗影像分析、机器人导航、视频监控等领域。其高效的计算特性使其能够在资源受限的设备上运行,例如移动设备和嵌入式系统。此外,AdaptiveNN的可解释性使其能够帮助人们理解模型的决策过程,从而提高模型的可靠性和可信度。未来,AdaptiveNN有望成为一种通用的视觉感知框架,推动计算机视觉技术的发展。
📄 摘要(原文)
Human vision is highly adaptive, efficiently sampling intricate environments by sequentially fixating on task-relevant regions. In contrast, prevailing machine vision models passively process entire scenes at once, resulting in excessive resource demands scaling with spatial-temporal input resolution and model size, yielding critical limitations impeding both future advancements and real-world application. Here we introduce AdaptiveNN, a general framework aiming to drive a paradigm shift from 'passive' to 'active, adaptive' vision models. AdaptiveNN formulates visual perception as a coarse-to-fine sequential decision-making process, progressively identifying and attending to regions pertinent to the task, incrementally combining information across fixations, and actively concluding observation when sufficient. We establish a theory integrating representation learning with self-rewarding reinforcement learning, enabling end-to-end training of the non-differentiable AdaptiveNN without additional supervision on fixation locations. We assess AdaptiveNN on 17 benchmarks spanning 9 tasks, including large-scale visual recognition, fine-grained discrimination, visual search, processing images from real driving and medical scenarios, language-driven embodied AI, and side-by-side comparisons with humans. AdaptiveNN achieves up to 28x inference cost reduction without sacrificing accuracy, flexibly adapts to varying task demands and resource budgets without retraining, and provides enhanced interpretability via its fixation patterns, demonstrating a promising avenue toward efficient, flexible, and interpretable computer vision. Furthermore, AdaptiveNN exhibits closely human-like perceptual behaviors in many cases, revealing its potential as a valuable tool for investigating visual cognition. Code is available at https://github.com/LeapLabTHU/AdaptiveNN.